| Audience | Data or analytics engineers, platform admins |
| Prerequisites |
|
Before configuring your schema, decide which data to expose and how to organize it. These decisions determine what marketers can target, filter, and sync to destinations.
What you'll learn
- Map your entities with an entity-relationship diagram before building
- Choose the right grain for your parent model
- Decide where data belongs: parent model, related model, event model, trait, or merge column
- Decide when a value should be a trait vs. upstream logic
- Structure a starter schema and expand it over time
- Name models and columns so marketers can self-serve
- Plan for sensitive data and how to scope access to it
- Avoid common anti-patterns that lead to confusing audience behavior
Overview
Your schema defines the data available in Customer Studio. It determines what marketers can filter on, use to build audiences, and sync to destinations.
A well-designed schema makes Customer Studio easier to use. A poorly organized schema makes audiences harder to build and maintain.
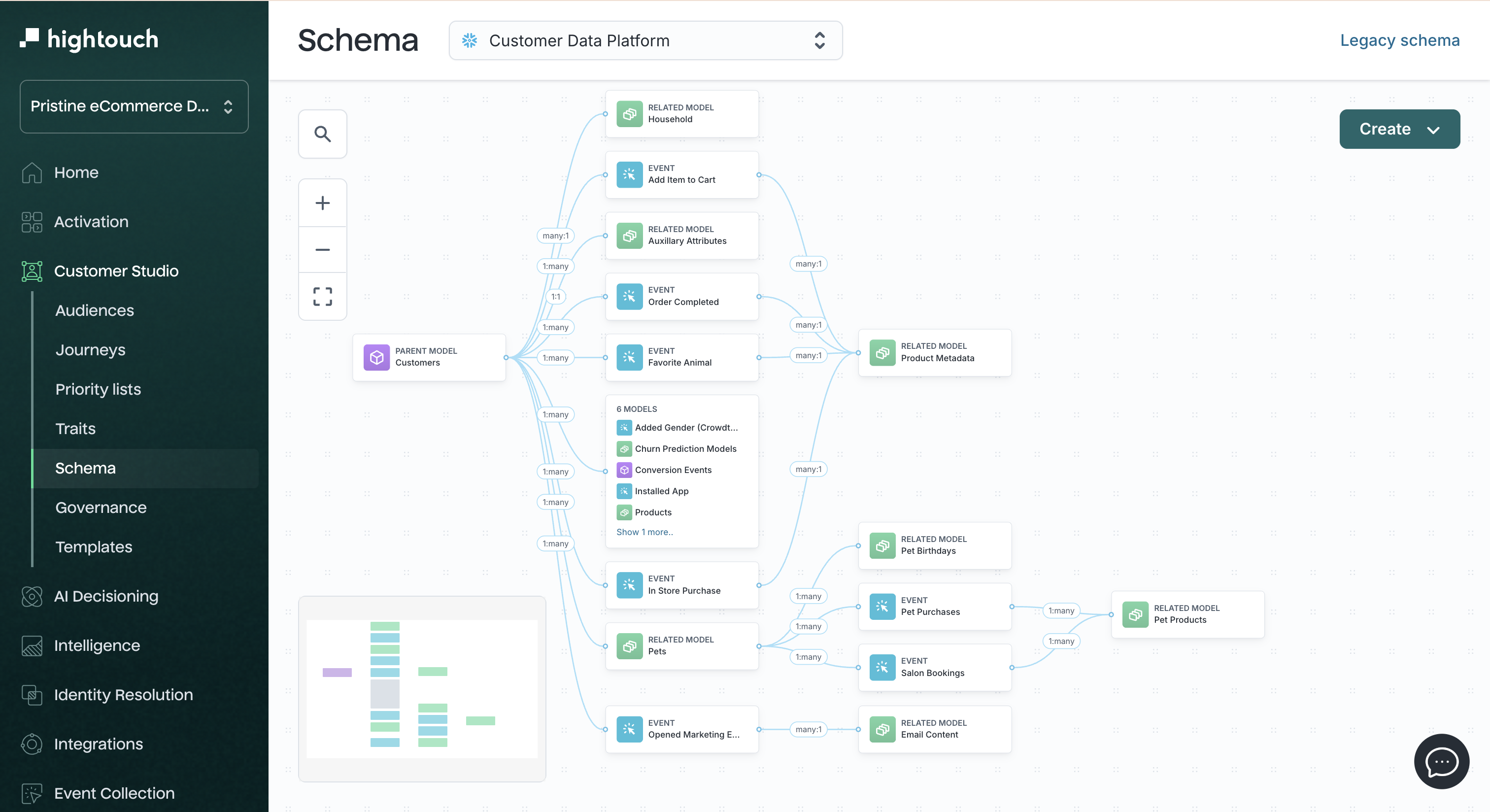
In Customer Studio, you'll define three types of models:
- Parent model: The base entity audiences are built from (for example,
Users) - Related models: Additional context joined to the parent (for example,
Households) - Event models: Timestamped behaviors (for example,
Product Viewed)
Together, these models and their relationships define the data marketers can use when building audiences.
Before you begin
Before designing your schema, make sure you have:
- Workspace access — Grant workspace access to the data-team members who set up and maintain the schema. See Inviting users.
- A connected source — Customer Studio builds a schema from a single warehouse source. Choose the warehouse that holds the customer, event, and transaction data your audiences need. See Sources.
- Connected destinations — Connect the tools where you'll activate audiences, such as ad platforms, lifecycle and email tools, and CRMs. Destinations aren't required to build or preview audiences, but you need at least one to activate them. See Destinations.
- Sync engine and storage (recommended) — Plan for the Lightning Sync Engine, which powers journeys, sampling, and audience snapshots. For security or compliance, Business tier teams can self-host storage so the data Hightouch keeps for change data capture and sync debugging stays in their own bucket.
Coordinate with business teams
Before building your schema, work with marketers or campaign owners on what they need to target and filter on. Start with one or two high-priority use cases rather than designing for everything at once. Good first use cases include:
- Suppression audiences (for example, exclude recent purchasers from ad spend)
- Re-engagement windows (for example, users inactive for 30+ days)
- Lifecycle stage audiences (for example, trial users who haven't activated)
Use these use cases to decide:
- which tables to expose
- which relationships to define
- how to name models and columns
Map your entities before you build
Before you configure anything in Customer Studio, sketch an entity-relationship diagram (ERD). List the entities you'll expose, such as users, accounts, purchases, and events. Then draw how they connect: which table is the parent, which join to it, and whether each relationship is one-to-one, one-to-many, or many-to-many.
Creating an ERD first helps you validate your model before you build it. Test your ERD against a real audience question. For example, can your models answer "target users who signed up but never completed onboarding"? If they can't answer a priority use case, restructure the diagram first.
Choose the right grain
The grain of your parent model determines what one row represents. Each row becomes one member of an audience and one record in a sync.
Before choosing a table, decide what one row should represent. Common choices include individual users, accounts, households, or devices. It affects:
- Audience membership is evaluated per parent row
- Sync output contains one record per qualifying parent row
- Traits and filters resolve back to the parent grain
If you set the parent model at the account grain, you can target accounts but not individual users within them. If you need both, you'll need separate parent models or a user-level grain with account data joined as a related model.
When to use multiple parent models
Some businesses need to target different entities for different use cases. A B2B company might target individual users for product adoption campaigns and accounts for renewal outreach. A marketplace might target buyers and sellers separately.
Create separate parent models only when you need to target different entities. Each has its own related models, events, and traits, and powers its own independent set of audiences.
The grain doesn't always map to a person. For example, an airline might use one row per traveler per flight instead of one row per traveler. That lets marketers target each trip independently.
Common scenarios that call for multiple parent models:
- B2B companies targeting both users and accounts
- Marketplaces with distinct buyer and seller audiences
- Products with both end users and admin contacts
Start with one parent model for your highest-priority use case. Add a second only when you have a concrete campaign that requires a different targeting entity. Avoid creating extra parent models just to expose more fields — in most cases, the better solution is a related model, a through relationship, or a trait. More parent models create more audience entry points, more duplicated configuration, and more opportunities for marketers to choose the wrong one.
If a related model or event table connects to multiple parent models, share it via relationships instead of duplicating it.
Choose the right model type
Store each type of data in the model that best matches how marketers will use it. Use this table to decide where a piece of data should live:
| If you need to... | Use a... | Example |
|---|---|---|
| Target an entity directly | Parent model column | region, signup_date, plan_tier |
| Filter on repeated records linked to the parent | Related model | Purchases, subscriptions, support tickets |
| Filter on timestamped behaviors | Event model | Page views, logins, cart additions |
| Collapse many rows into one value per parent row | Trait | Total spend, days since last login, most frequent category |
| Access a parent field inside a related or event model | Merge column | Show region on purchase records |
Sync field mappings draw from parent model columns, merge columns, and traits. Data on related and event models is available for audience filtering but does not appear directly in sync output. To include a value from a related model in a sync, create a trait that rolls it up to the parent or add it as a merge column.
Why can't I map this field? Sync mappings use parent model columns, traits, and merge columns. Fields on related and event models can be used for filtering but not sync mappings. To make one available, create a trait, add a merge column, or move the value to the parent model.
When to model something as a trait
Use a trait when marketers need a reusable value derived from related or event data, such as lifetime value, days since last purchase, total number of orders, or most frequent product category.
Traits are the right choice when:
- The value doesn't exist as a column on the parent model and needs to be computed from related or event data
- Multiple audiences will use the same calculation, so you want to define it once
- Marketers need the value in sync field mappings (traits on the parent model are syncable; related/event fields are not)
Keep the logic upstream instead when:
- The calculation defines a core business metric your team governs centrally (for example, official LTV or churn score)
- The computation is expensive and benefits from materialization in the warehouse
- Multiple teams outside Customer Studio need the same value
For details on creating and managing traits, see Traits.
Start with a recommended shape
You don't need to model your entire warehouse on day one. A good starting point:
- 1 parent model (for example,
Users) with common attributes flattened onto it (email, region, plan, signup date) - 2–3 high-value related models (for example, Purchases, Subscriptions)
- 1–2 event tables (for example, Page Views, Logins)
Expand the schema as use cases grow, adding models when new use cases require them.
Name models and columns for marketers
Marketers interact with the schema through the audience builder. Names should be easy to understand without warehouse context:
- Use plain names:
Signup datenotcreated_at,Regionnotgeo_region - Name models after what they represent, not where they come from:
Usersnotbraze_user_attributes,Purchasesnotfact_order_items - Use column aliases to rename technical column names without changing your warehouse
- Disable columns that add noise (internal IDs, ETL metadata, debugging fields)
Keep data types consistent
Mismatched data types between models cause relationship errors and confusing audience results:
- Keep primary key types consistent across models — an
integerprimary key on the parent and abigintforeign key on a related model can cause join failures - Store timestamps as UTC timestamp or datetime types, not strings
- Normalize numeric units and document them — store currency in one consistent unit (for example, cents as an integer) instead of mixing dollars and cents across models
- Decide what null values mean (unknown, not applicable, or excluded) and set a default upstream so audience filters behave predictably
- Cast nested or JSON fields upstream where practical — the audience builder works best with flat, typed columns
Plan for sensitive data
Decide how you'll handle personally identifiable information (PII) before you expose a model, so marketers only see the data they need. PII includes names, email addresses, phone numbers, and payment or government identifiers.
You control sensitive data in two places:
- In your warehouse — Mask or hash values that your destinations don't need in cleartext. Hash emails or phone numbers used only as join keys, and keep raw values only in the models that genuinely require them.
- In Hightouch — Set a privacy level on each sensitive column.
Redactedkeeps a column filterable while hiding raw values in previews, andSync-onlyorSync-blockedcontrol whether a value can leave in a sync.
To scope which rows and destinations a team can reach, plan for subsets and destination rules. Subsets restrict row-level access by attributes like region or brand. Destination rules enforce consent and channel constraints per destination. Plan these access rules when you design your schema.
Decide what belongs upstream vs. in Hightouch
Store business-critical, reusable, or core-metric logic in your warehouse as a materialized view, dbt model, or table. Use Hightouch traits and computed columns for activation-specific calculations, not as a replacement for core data modeling.
Build a presentation layer first
We recommend creating a presentation layer in your warehouse before building your schema. A presentation layer is a set of pre-joined, pre-aggregated models (for example, dbt marts) built for activation. It should:
- flatten complex joins
- materialize expensive calculations
- expose clean, marketer-friendly columns
Materialize expensive joins in your warehouse whenever possible. Large event tables should also be partitioned or clustered by timestamp. This improves audience preview and sync performance.
For large event tables, default your audience templates and examples to a bounded lookback window — for example, the last 90 days — so interactive previews stay fast.
Keep parent models lean
Expose only the columns marketers need for filtering and sync field mappings. Put infrequently used attributes in related models. A lean parent model makes the audience builder faster and easier to navigate.
Handle JSON and nested fields upstream
Customer Studio supports JSON and nested fields, but flatten them into typed columns in your presentation layer whenever possible. If you expose nested data, document the expected shape for marketers.
Avoid common anti-patterns
- Using the wrong parent model grain. Setting the parent at household or account grain when you need to target individuals leads to audience count confusion and inability to personalize per user.
- Exposing unnecessary tables and columns. Only expose the tables and columns marketers actually need. A schema with 50 models and hundreds of columns makes the audience builder harder to use, not easier.
- Naming models after their sync destination. A parent model named
Braze user attributesmakes sense for one sync but confuses everyone when you add more destinations. Name models after the entity they represent. - Skipping relationship validation. Test your relationships with a small audience before building production campaigns. A misconfigured join key silently produces wrong audience counts.
What's next?
Once you've planned your data model, configure it in Customer Studio:
- Define your schema Create parent, related, and event models, configure columns, and set up relationships.
- Create traits Build reusable calculated values marketers can use in audience filters and sync field mappings.