
Ingest and process your data via a data stream
Overview
Hightouch integrates directly with Amazon Kinesis to support high-throughput, distributed, or asynchronous workloads, letting you build a custom connector to your internal systems.
Getting started
Connect to your AWS account
When setting up the Amazon Kinesis destination for the first time, you need to enter your AWS Credentials to give Hightouch access to your AWS account. Hightouch needs permission to send streaming data to Amazon Kinesis on your behalf.
Hightouch believes in the principle of least privilege. We ask for no more permissions than necessary. For the Amazon Kinesis destination, Hightouch requires kinesis:PutRecords and kinesis:ListStreams.
When configuring your credentials in Hightouch, you have two options:
- Setting up a cross-account role (recommended)
- Providing an access key
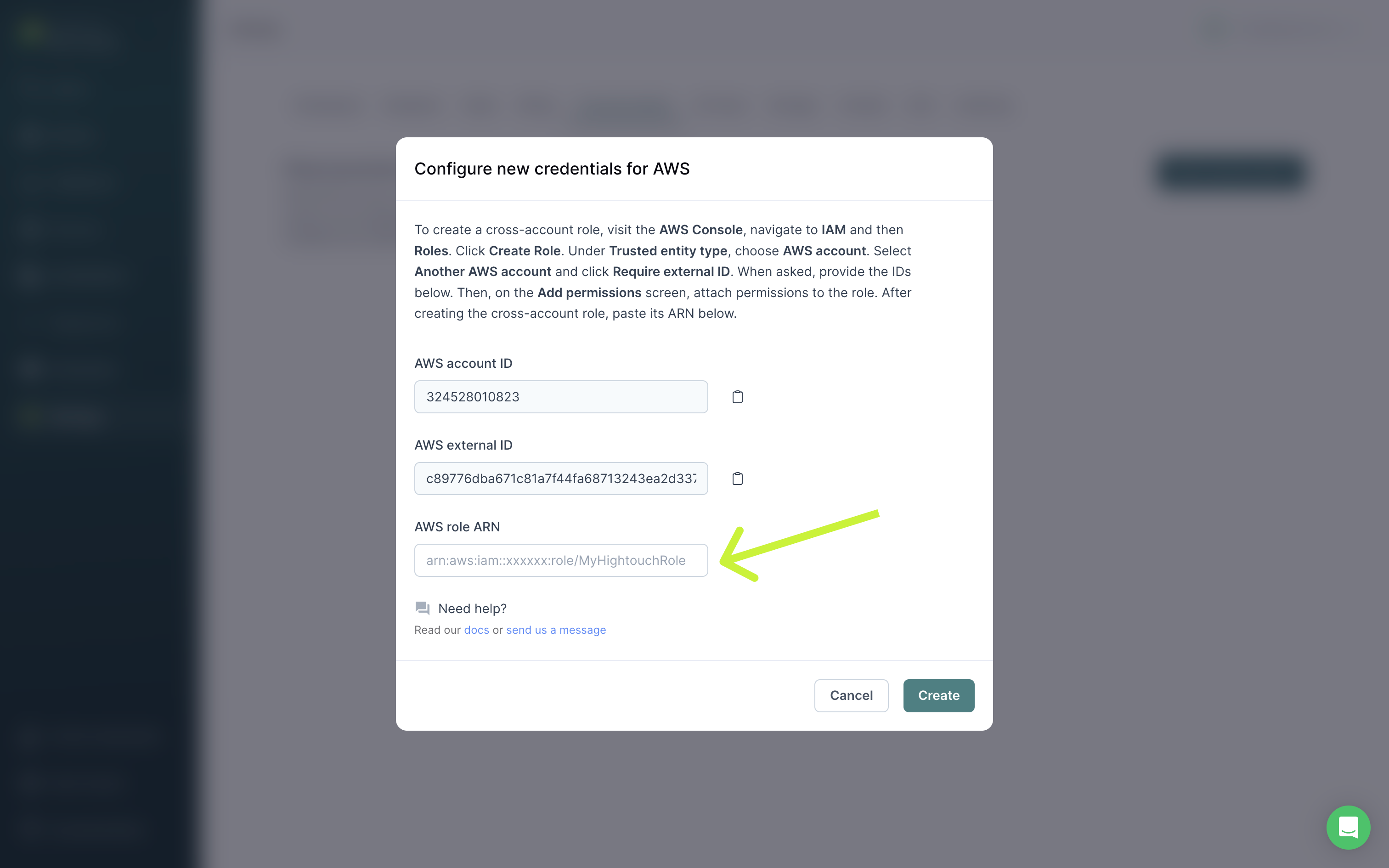
Set up cross-account role
Cross-account roles are the most secure method for granting Hightouch access to Amazon Kinesis in your AWS account.
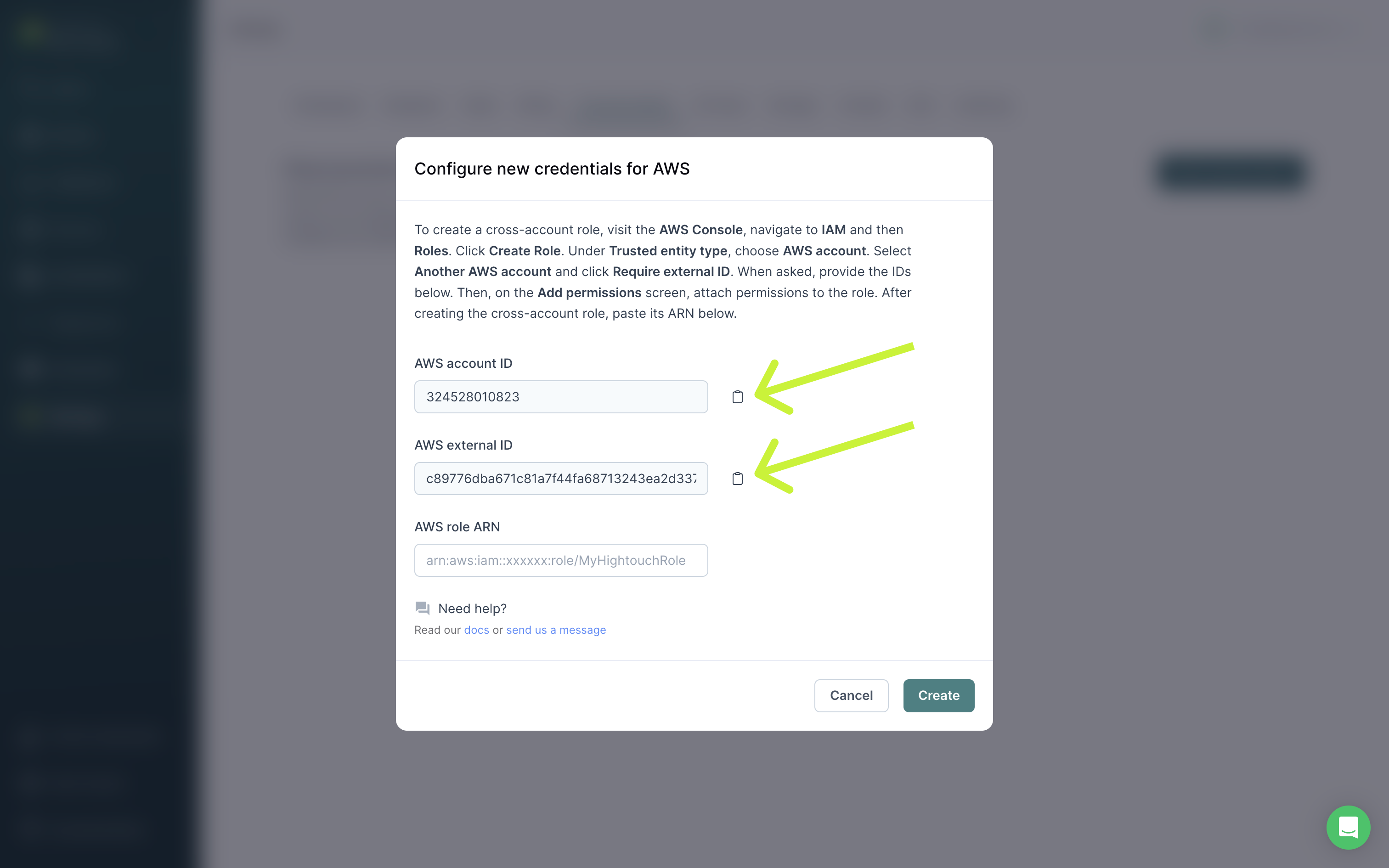
You need the Account ID and External ID in the Hightouch UI to set up a cross-account role.
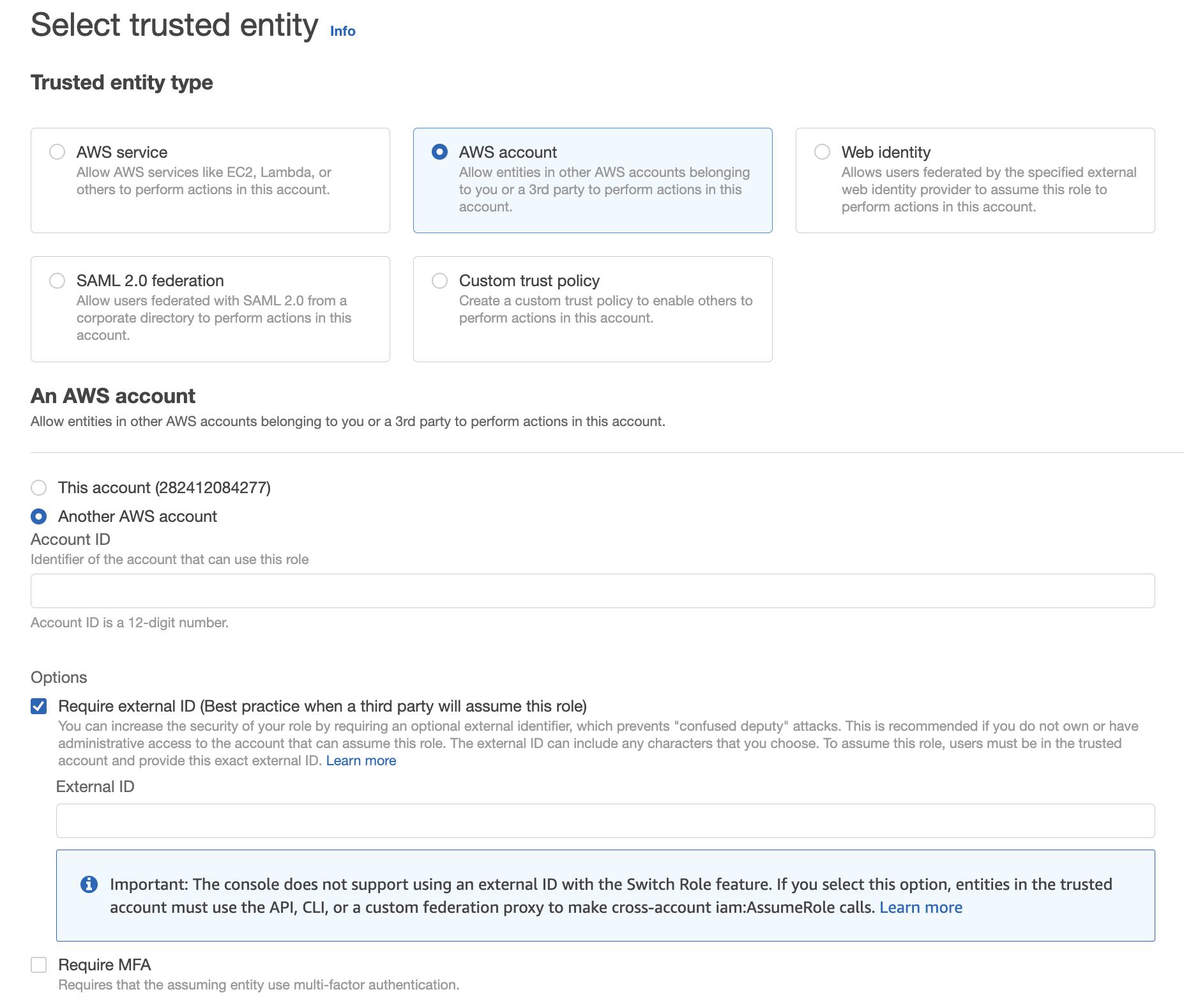
- In the AWS Console, navigate to IAM → Roles.
- Click Create Role.
- Under Trusted entity type, choose AWS account.
- Select Another AWS account and also click Require external ID.
- Copy/paste the Account ID from Hightouch into the Account ID field in AWS.
- Copy/paste the External ID from Hightouch into the External ID field in AWS.
- On the Add permissions screen, proceed to attach permissions to the role using any policy that includes at least
kinesis:PutRecordsandkinesis:ListStreams. Then create the role.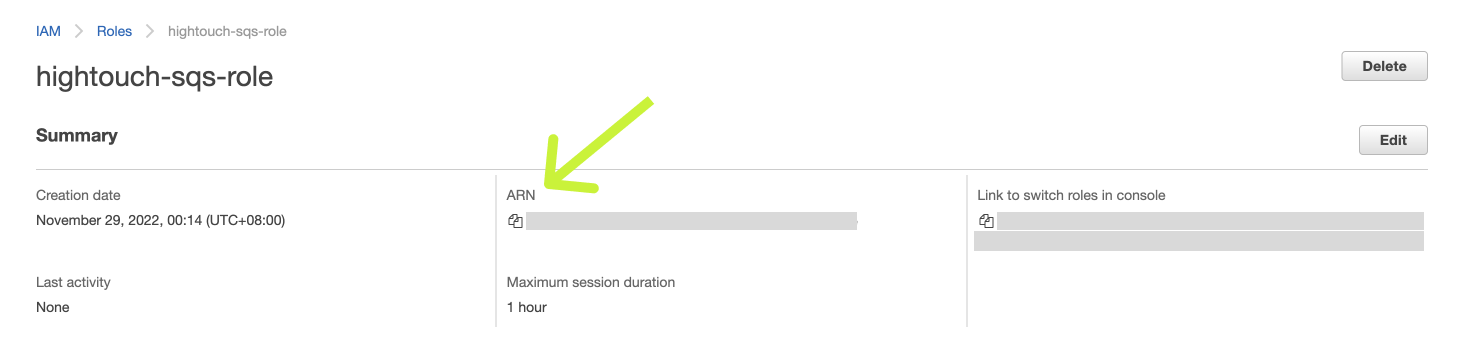
- Copy/paste the Role ARN from AWS into Hightouch. Click Create to finish setting up your cross-account role.
Provide access key
If you don't want to create a cross-account role, you can create a regular IAM user and share a Access Key ID and Secret Access Key with Hightouch.
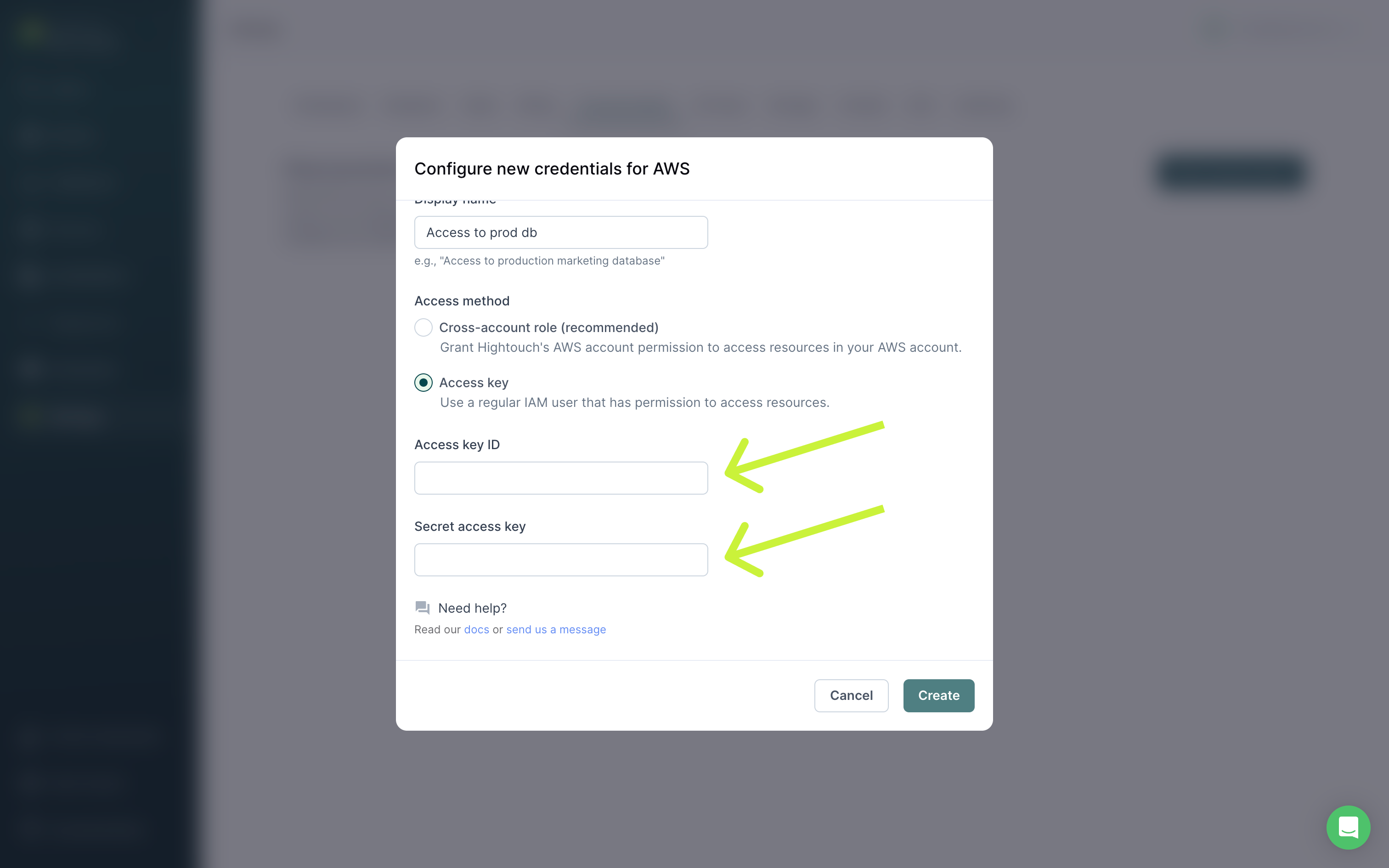
Be sure to attach the user to a permission policy that includes kinesis:PutRecords and kinesis:ListStreams for the specific resource you want to use via a Hightouch sync.
An example policy looks like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["kinesis:PutRecords", "kinesis:ListStreams"],
"Resource": [
"YOUR_KINESIS_ARN_1",
"YOUR_KINESIS_ARN_2",
"YOUR_KINESIS_ARN_3"
]
}
]
}
Select your AWS region
In this step, you specify which region has the resources you want to sync to.
Syncing data
Once you've authenticated your AWS account in Hightouch and selected an AWS Region, you've completed setup for a Amazon Kinesis destination in your Hightouch workspace. The next step is to configure a sync that send messages whenever rows are added, changed, or removed in your model.
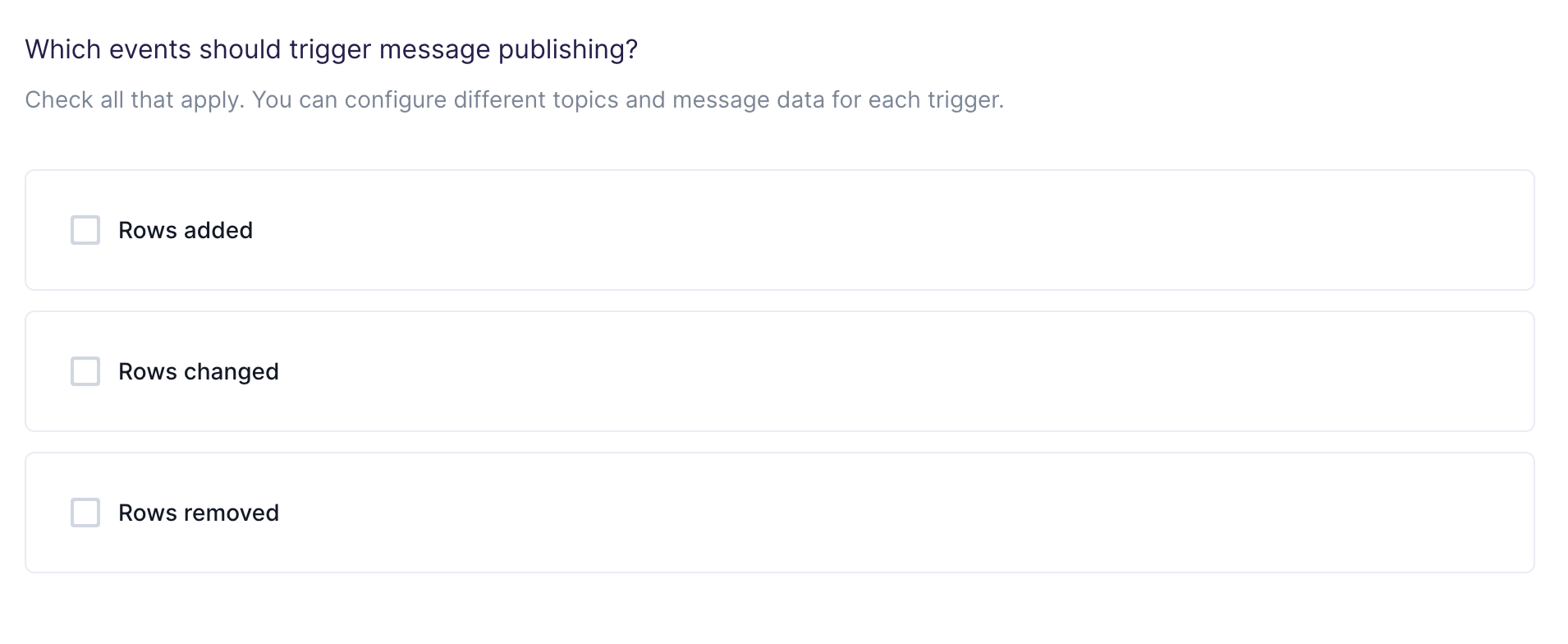
Configure your events trigger
Hightouch monitors your data model for added, changed, and removed rows. In this step, you specify which of these events should trigger message publishing.
Choose your data stream
In this step, you choose which data stream to send messages to. Hightouch allows you to sync to existing data streams that are already in your Amazon Kinesis.
Customize your streaming data
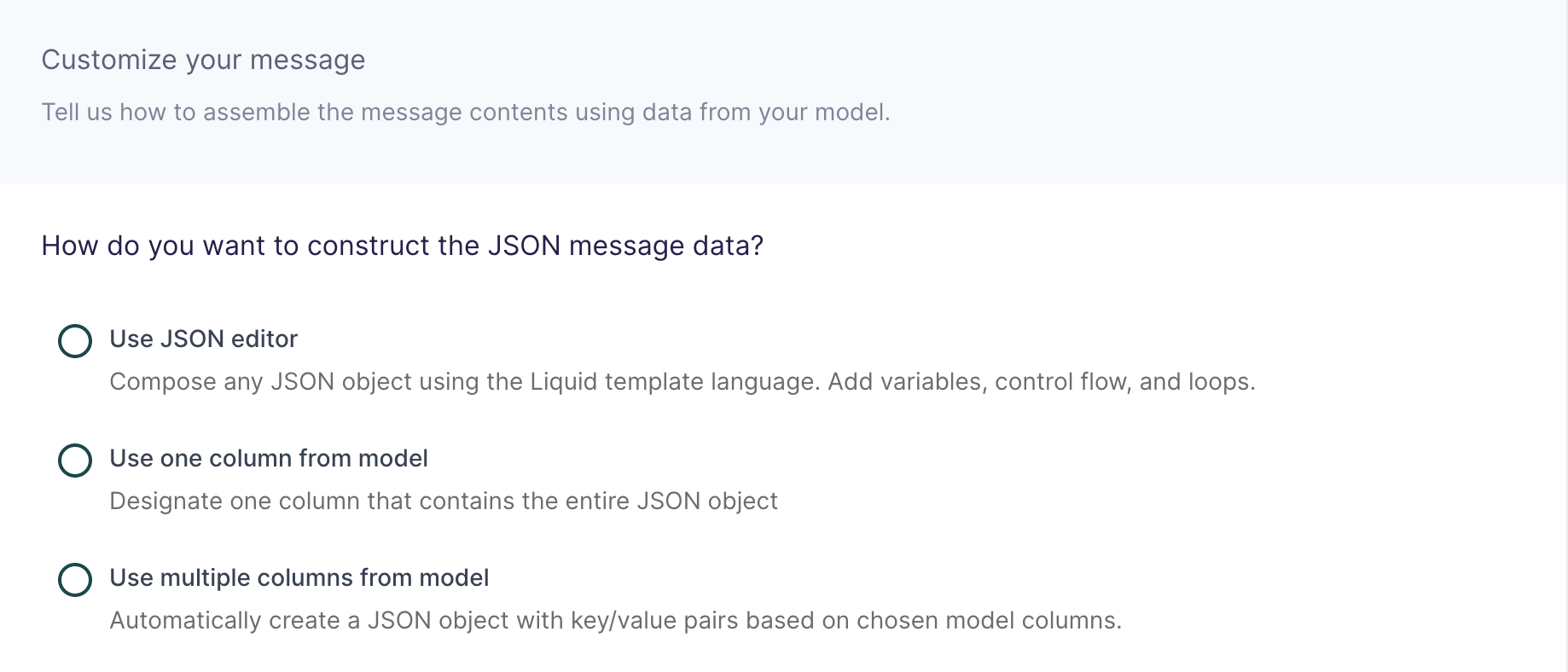
In this step, you tell Hightouch how to build the JSON streaming data object using data from your model.
Configure partition key
This field is sent along with the streaming data and determines which shard in the stream the data record is assigned to. Amazon Kinesis Data Streams uses the partition key as input to a hash function that maps the partition key and associated data to a specific shard. Specifically, an MD5 hash function is used to map partition keys to 128-bit integer values and to map associated data records to shards. As a result of this hashing mechanism, all data records with the same partition key map to the same shard within the stream.

This destination offers three methods of composing a JSON object:
Use JSON editor

With the JSON editor, you can compose any JSON object using the Liquid template language. This is particularly useful for complex streaming data bodies containing nested objects and arrays, which can sometimes be difficult to model entirely in SQL.
Suppose your data model looks like this:
| full_name | age | email_address | phone_number |
|---|---|---|---|
| John Doe | 30 | john@example.com | +14158675309 |
And you want your streaming data like this:
{
"name": "John Doe",
"age": 30,
"contact_info": [
{
"type": "email",
"value": "john@example.com"
},
{
"type": "phone",
"value": "+14158675309"
}
]
}
Your Liquid template should look like this:
{
"name": "{{row.full_name}}",
"age": {{row.age}},
"contact_info": [
{
"type": "email",
"value": "{{row.email_address}}"
},
{
"type": "phone",
"value": "{{row.phone_number}}"
}
]
}
This makes it so you can reference any column using the syntax {{row.column_name}}. You can also use advanced Liquid features to incorporate control flow and loops into your dynamic streaming data.
When injecting strings into your JSON body, be sure to surround the Liquid tag in double quotes.
Use one column from model
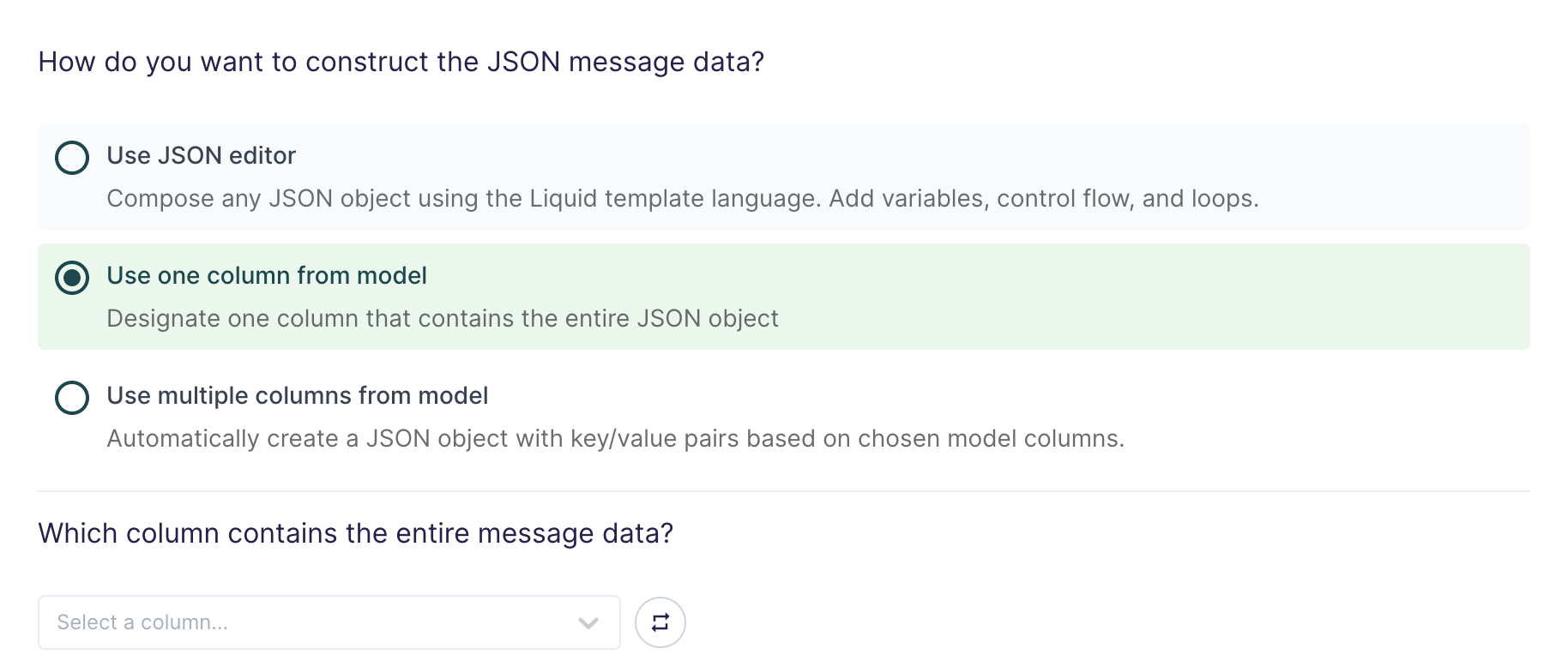
If you're already storing JSON data in your source, or if you have the ability to construct a JSON object using SQL, you can select one column in your model that already contains the full streaming data.
This setting is commonly used when syncing web events that have already been collected and stored as JSON objects in your database.
Use multiple columns from model
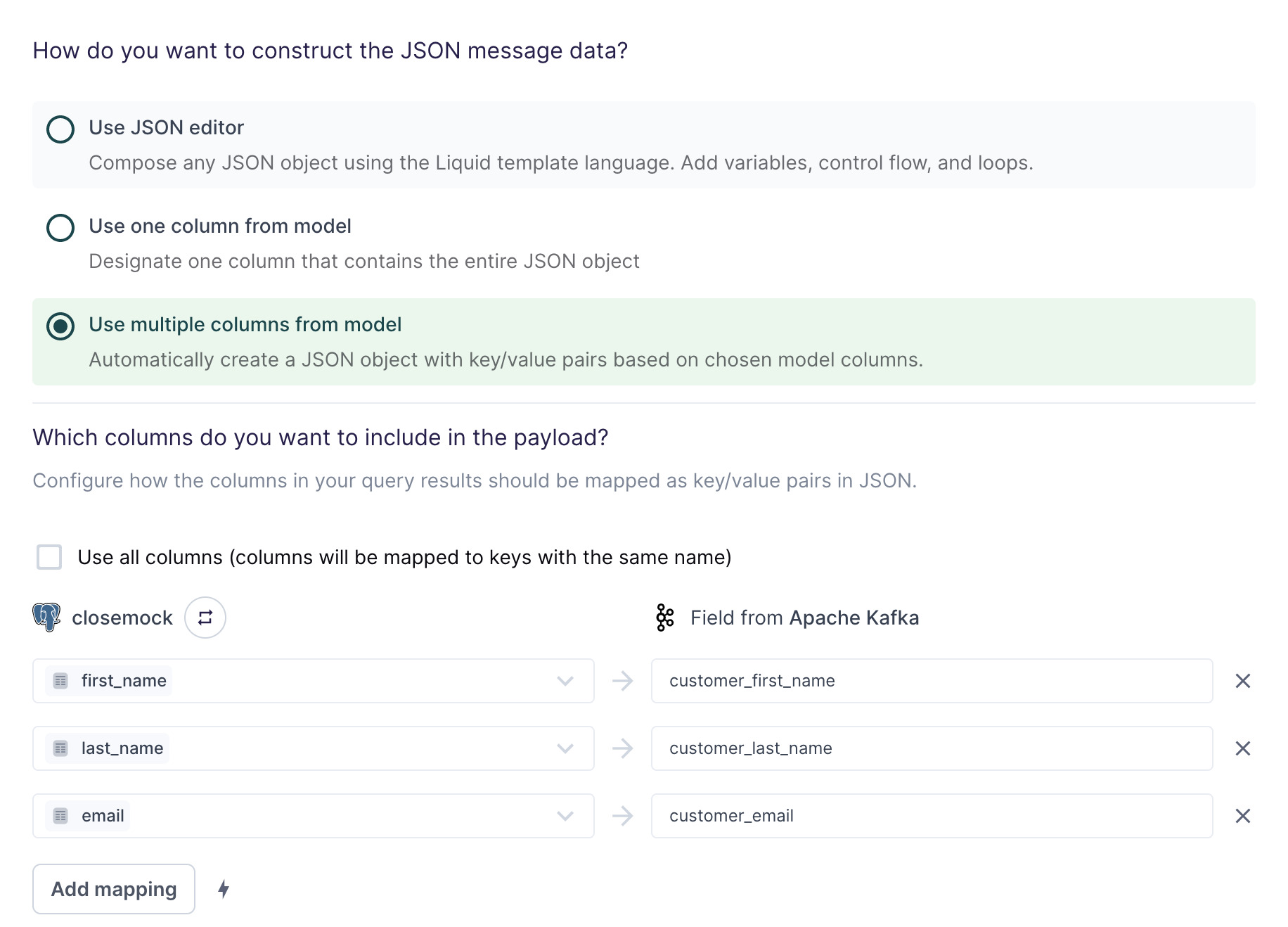
For the simplest use cases, Hightouch can construct a JSON object with key/value pairs based on multiple columns in your model.
Suppose your model looks like this:
| first_name | last_name | |
|---|---|---|
alice.doe@example.com | Alice | Doe |
bob.doe@example.com | Bob | Doe |
carol.doe@example.com | Carol | Doe |
The field mapping in the screenshot above would generate the following streaming data for the first row:
{
"customer_first_name": "Alice",
"customer_last_name": "Doe",
"customer_email": "alice.doe@example.com"
}
You can use the field mapper to rename fields. For example, first_name can
be mapped to customer_first_name.
Configure optional message properties
Along with your row data in JSON format, you can also optionally include an explicit hash key to explicitly determine the shard the data record is assigned to.
ExplicitHashKey
This is a string field that should be a hash value and will override the partition key hash.
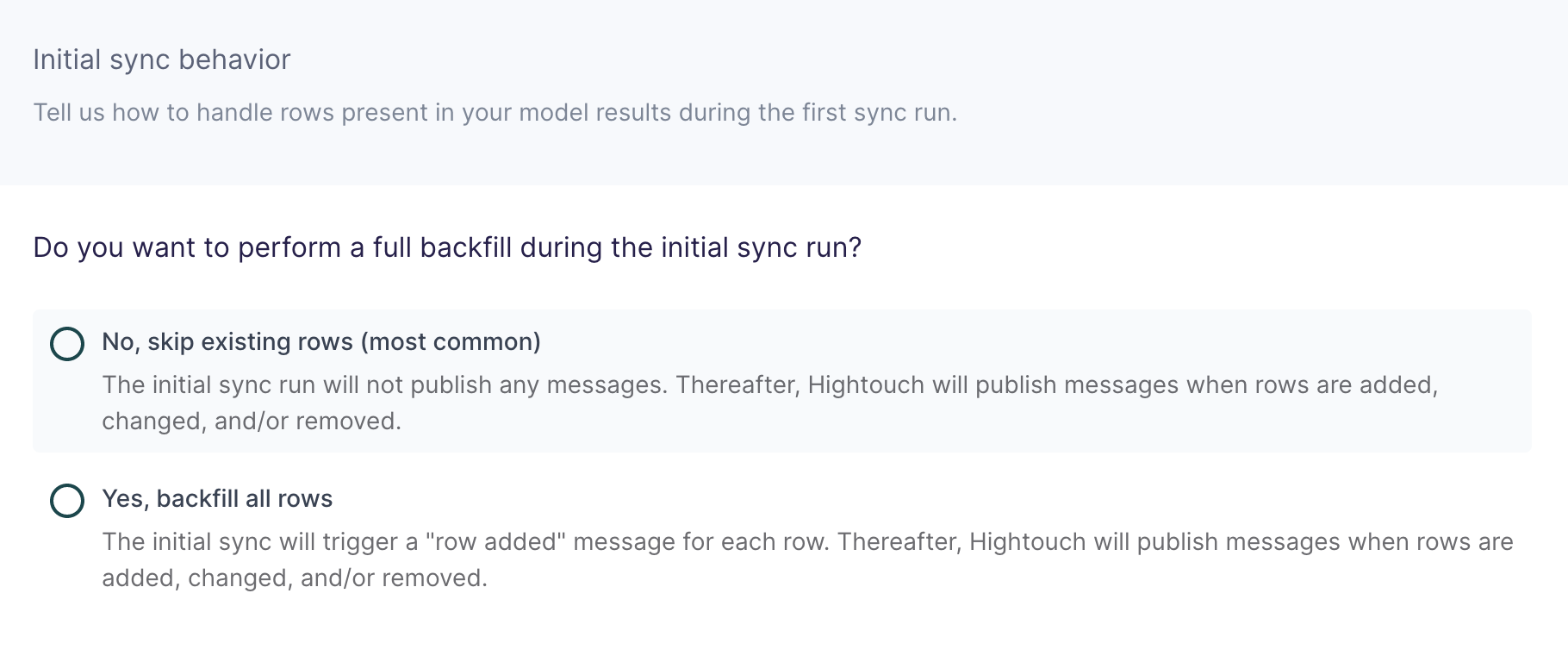
Configure initial sync behavior
In this step, you tell Hightouch how to handle rows present in your model results during the first sync run.
Certain workflows may require performing a backfill of all rows during the initial sync. For other use cases, you might only want to send messages in response to future data changes.
Tips and troubleshooting
Common errors
If you encounter an error or question not listed below and need assistance, don't hesitate to . We're here to help.
ProvisionedThroughputExceededException: Rate exceeded for shard.
This error refers to Amazon Kinesis’ quotas and limits. Manual intervention isn't required since our sync engine retries rejected rows during the following sync run.
Live debugger
Hightouch provides complete visibility into the API calls made during each of your sync runs. We recommend reading our article on debugging tips and tricks to learn more.
Sync alerts
Hightouch can alert you of sync issues via Slack, PagerDuty, SMS, or email. For details, please visit our article on alerting.