
Transfer data at scale from your warehouse to Google Cloud Storage
Supported syncing
| Object Type | Description | Supported Sync Modes |
|---|---|---|
| Any data set | Sync data from a source to Google Cloud Storage as JSON, NDJSON, CSV, Parquet, or XML files | All, Insert, Diff, Upsert |
- All: All mode creates one file with all the rows in the query results, every time the sync runs.
- Insert: Insert mode creates one file with the rows that were added since the last sync.
- Diff: Diff mode creates three files, one for rows added, one for rows changed, and another for rows removed since the last sync.
- Upsert: Upsert mode creates one file with the rows that were added or changed since the last sync. Removed rows aren't included.
For more information about sync modes, refer to the sync modes docs.
Hightouch can process large sync runs in parallel across multiple workers. Parallel processing doesn't change the sync output: Hightouch merges the results and writes them to the files you configure.
The order of rows and columns in uploaded files may differ from how they appear in your model. This is expected behavior and applies to all sync modes. Learn more about row and column ordering →
Connect to Google
Go to the Destinations overview page and click the Add destination button. Select Google Cloud Storage and click Continue. You can then authenticate Hightouch to Google Cloud Storage by entering your:
- GCP Credentials: if you need to create a cloud credential, consult our documentation
- GCP Project ID: you can follow these steps to find it
- GCP Bucket Name: this should just be the name of the bucket, not a URL
Sync configuration
Once you've set up your Google Cloud Storage destination and have a model to pull data from, you can set up your sync configuration to begin syncing data. Go to the Syncs overview page and click the Add sync button to begin. Then, select the relevant model and the Google Cloud Storage destination you want to sync to.
Select file format
Hightouch supports syncing JSON, NDJSON, CSV, Parquet, and XML files to Google Cloud Storage.
Enter filename
The filename field lets you specify the parent directory and the name of the file you want to use for your results.
You can include timestamp variables in the filename, surrounding each with {}.
Hightouch supports these timestamp variables:
YYYY: Represents the full year in four digits.YY: The last two digits of the year.MM: Two-digit month format (01-12).DD: Two-digit day format (01-31).HH: Two-digit hour format in 24-hour clock (00-23).mm: Two-digit minute format (00-59).ss: Two-digit second format (00-59).ms: Three-digit millisecond format.X: Unix timestamp in seconds.x: Unix timestamp in milliseconds.
All dates and times are UTC.
For example, you could enter upload/{YYYY}-{MM}-{DD}-{HH}-{mm}-result.json to dynamically include the year, month, date, hour, and minute in each uploaded file. Hightouch would insert each file in the upload directory, which would need to already exist in your bucket.
You can also use other variable values to include sync metadata in the filename:
{model.id}{model.name}{sync.id}{sync.run.id}
If a file already exists at the path you entered at the time of a sync, Hightouch overwrites it.
If you are using an audience and would like to include the audience name, you
will still use {model.name}.
Set filename offset
By default, Hightouch uses the timestamp of the sync run to fill in timestamp variables. You can optionally include an offset in seconds. For example, if you want the filename's date to be 24 hours before the sync takes place, enter '-86400' (24 hours * 60 minutes * 60 seconds).
Upsert mode
Upsert mode writes the rows that were added or changed since the last sync to a single file. Removed rows aren't included. Use Upsert when a downstream process only needs incremental updates, for example, a pipeline that ingests new and updated records from one file.
If you select the Upsert sync mode, enter the file path in the Which file would you like to sync upserted rows to? field. Timestamp variables work the same way as in the filename field. If a file already exists at the path, Hightouch overwrites it.
In the output file, added rows appear before changed rows.
Upsert mode has two limitations:
- Column mappings are required — Upsert mode doesn't support the Sync all columns option. Map the columns you want to sync explicitly (see Columns to sync).
- Batching isn't available — Upsert always merges results into a single file (see Batch size).
Columns to sync
You can export all columns exactly as your model returns them or choose to export specific ones.
If you need to rename or transform any column values you're syncing, you can use the advanced mapper to do so. If you choose this option, Hightouch only syncs the fields you explicitly map.
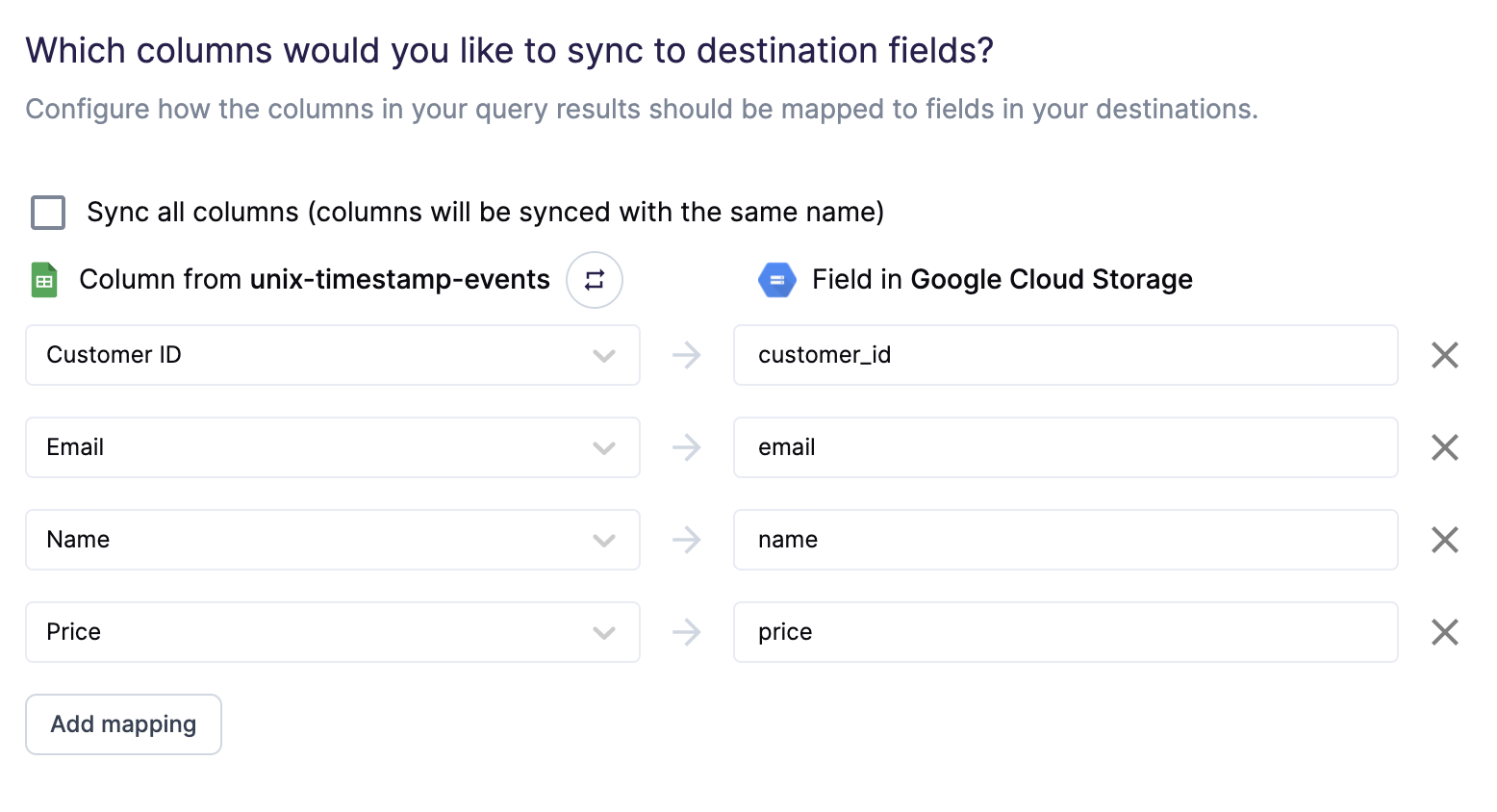
The preceding example shows how to selectively export the company, email, name, and price fields. Hightouch exports these fields to new fields in the file and ignores all other columns from your results.
CSV options
If you're syncing to a CSV file, you have additional configuration options:
- Delimiter: Your options are comma (
,), semicolon (;), pipe (|), tilde (~), and tab - (Optional) Whether to include a CSV header row in the exported files
- (Optional) Whether to include a byte order mark (BOM) in the exported files, the BOM is
<U+FEFF>
Batch size
By default, and depending on your sync mode, Hightouch sends one file for each export. (In Diff mode, Hightouch sends up to three files.)
By enabling batching, you allow Hightouch to send multiple files if your model query results are large. This can help avoid file size errors.
Batching isn't available in Upsert mode.
Empty file results
You can select how Hightouch should handle empty results files. Empty result files can occur if your model's query results haven't changed since the last sync.
You can select whether to skip empty files. If you skip empty files, it means Hightouch won't export any files if your model's query results haven't changed since your last sync.
Tips and troubleshooting
Common errors
To date, our customers haven't experienced any errors while using this destination. If you run into any issues, please don't hesitate to . We're here to help.
Live debugger
Hightouch provides complete visibility into the API calls made during each of your sync runs. We recommend reading our article on debugging tips and tricks to learn more.
Sync alerts
Hightouch can alert you of sync issues via Slack, PagerDuty, SMS, or email. For details, please visit our article on alerting.