Explore the interactive architecture diagram
See how data moves through Hightouch — including security controls, private networking, and storage boundaries.
Overview
At Hightouch, we work with large healthcare, financial, and public enterprises to activate and govern sensitive customer data—across syncs, events, Customer Studio, and AI Decisioning. We are committed to building a warehouse‑native customer data and AI platform designed to meet rigorous enterprise security standards.
This document gives an overview of our security processes and infrastructure architecture.
Key security highlights
We’ve been through thousands of rigorous security reviews. These are the most important, high-level points to understand before diving into the details:
-
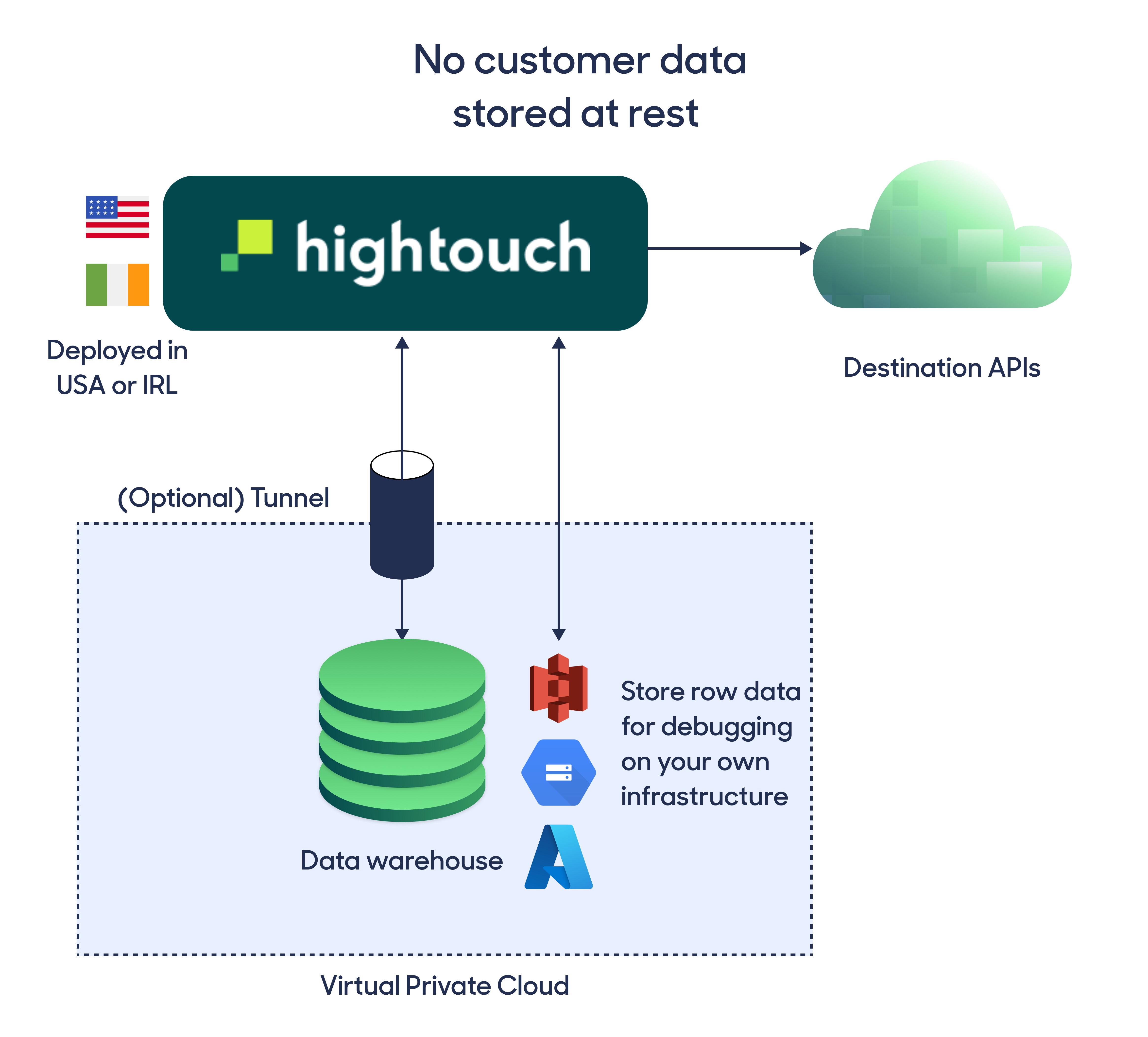
Hightouch never stores your customer data at rest*
For standard Reverse ETL, Events, and composable CDP use cases, Hightouch does not create a separate, long‑lived copy of your primary customer tables in Hightouch infrastructure. Your source‑of‑truth data stays in your warehouse and other systems of record. Hightouch uses only the minimal, configurable storage needed for logs, change‑data‑capture state, and certain AI workloads. -
Your cloud, your region
Any Hightouch workspace can be deployed in a supported region on AWS, GCP, or Azure. -
Least-privilege warehouse access
- Hightouch requires limited
READaccess to your warehouse, following the principle of least privilege. You can tightly scope this access using native warehouse permissions. - With the default Basic sync engine, change-data-capture runs on Hightouch infrastructure and only minimal metadata is stored in your configured bucket.
- If you enable the Lightning sync engine (recommended for larger or high‑volume syncs), Hightouch also requires
WRITEaccess for logging and advanced features. This access is isolated to a configurable Hightouch-managed location in your warehouse and never intersects with your own data.
- Hightouch requires limited
-
Customer-owned storage by design
Hightouch uses a cloud storage bucket as a caching layer for high-performance data movement and debugging. We strongly advocate that this is your bucket, in your cloud, where you maintain ownership and data retention configuration. See Cloud storage and Bring your own bucket. -
Private networking support
When communicating with your warehouse and your cloud bucket, we support private connectivity across all major clouds (AWS PrivateLink, Azure Private Link, GCP Private Service Connect) to ensure no communication between Hightouch and your data infrastructure is exposed to the public internet. -
Encryption and regional data residency
All customer data is encrypted in transit (TLS 1.2+). Data processed by Hightouch remains within the cloud and region where your workspace is deployed. Any outbound API traffic is encrypted. -
Strong governance and access controls
Hightouch Workspace governance supports SSO/SCIM, granular RBAC and custom roles, label-based controls, approval workflows, and audit logs to ensure users only access the data and features appropriate to their role.
* This design applies to all core Hightouch products, including Reverse ETL, Events, and Customer Studio. Certain features—such as Real‑Time and AI/ML features—may cache feature data, outcomes, or logs in the storage bucket configured for your workspace to meet latency and observability requirements. These artifacts are single‑tenant, can be stored in your cloud bucket, and are never used to train shared or third‑party models. See the AI Addendum and AI Decisioning data handling for details.
Compliance

Hightouch maintains SOC 2 Type 2 compliance and is ISO 27001 certified by Schellman, an accredited certification body.
Hightouch supports customer compliance with HIPAA, GDPR, and CCPA requirements.
In addition to these certifications, we follow established security best practices, including:
- Automated vulnerability scanning
- Regular third-party penetration testing — please for the latest report
SOC 2 Type 2 audit report
If you are an existing Hightouch customer, you can:
or ping us in your dedicated Slack channel to request our SOC 2 audit report.
If you are trialing Hightouch, your point of contact can provide you with the SOC 2 audit report under NDA.
Architecture overview
At a high level, Hightouch follows a simple flow:
- Connect securely to your warehouse or other source.
- Define what data to pull from your source using models.
- Use syncs to map that data to destinations and control when it runs.
Connecting to your data
Hightouch connects directly to your warehouse over TLS by default. For most customers, this direct connection is sufficient.
If your source is deployed within a private network or VPC, Hightouch also supports secure connectivity via:
- SSH tunneling or reverse SSH tunneling
- Private networking such as AWS PrivateLink, GCP Private Service Connect, or Azure Private Link
See Networking overview for architecture patterns and trade-offs.
A direct TLS connection is appropriate for most deployments. Private networking or tunneling is typically required when your warehouse is not publicly accessible.
Defining data with models
After connecting your source, you create models.
Models are SQL definitions that Hightouch executes directly on your warehouse. They define what data to retrieve, but they do not store customer data inside Hightouch.
Syncing to destinations
A sync determines:
- Which model to use
- How fields are mapped to a destination
- When and how frequently the sync runs
When a sync initiates, Hightouch:
- Executes the model’s SQL query directly on your warehouse.
- Computes incremental changes using our change data capture process (see Change data capture architecture).
- Translates the resulting rows into the appropriate destination APIs.
Data handling during execution
Customer data flows through Hightouch infrastructure only during an active sync.
During this process, data is:
- Encrypted in transit using TLS 1.2 or higher
- Processed within the same cloud and region where your Hightouch workspace is deployed
- Not stored as primary customer tables within Hightouch infrastructure for standard Reverse ETL and CDP use cases
Limited operational logs and change-data-capture metadata are stored as described in Data storage.
Hightouch does not expose its compute instances directly to the public internet. Infrastructure is secured according to cloud provider security best practices.
Transit details
Hightouch uses AWS Elastic Load Balancing to distribute incoming traffic across healthy targets and increase application and network availability.
To protect data in transit, Hightouch enforces:
- TLS 1.2 or later on all HTTPS load balancers
- Disabling legacy SSL and older TLS versions with known vulnerabilities
- Alignment with the AWS Well-Architected Framework principles for:
- Operational excellence
- Security
- Reliability
- Performance efficiency
- Cost optimization
We apply the following best practices for traffic between Hightouch, your data sources, and your destinations:
- Encryption in transit everywhere (TLS 1.2+)
- Authenticated network communications for all connections
- Automated detection of unintended data access
- Private connectivity options when required:
- SSH tunneling (standard and reverse)
- AWS PrivateLink
- GCP Private Service Connect
- Azure Private Link
All outbound traffic to public SaaS APIs is also encrypted via TLS 1.2 or higher.
Data storage
After sending data downstream, Hightouch persists only the operational data needed for change‑data‑capture and debugging. This includes request/response payloads, row‑level status, and diff state, stored in a cloud storage bucket. By default, this bucket is Hightouch‑managed for self‑service plans, but you can use your own cloud bucket so these artifacts live entirely in your infrastructure.
Change data capture architecture
To prevent unnecessary API requests and limit the amount of data sent downstream, Hightouch uses change data capture (CDC) or “diffing.”
For most enterprise and high‑volume workloads, Hightouch recommends the Lightning sync engine for performance and to keep more state inside your warehouse.
There are two main approaches:
- The Lightning sync engine computes diffs inside your warehouse.
- Hightouch requires
WRITEaccess to specific tables in a dedicated internal schema (for example,hightouch_planner) to store metadata from previous syncs. - This in‑warehouse computation typically enables faster syncs at higher volumes and keeps more state inside your environment.
- Hightouch requires
- The Basic sync engine (also called “local diffing”) computes diffs in Hightouch infrastructure.
- It does not require
WRITEaccess to your warehouse. - It may have slightly slower sync speeds at very high volumes but can offload some compute from your warehouse.
- Diff metadata is stored alongside sync logs in your Hightouch‑managed or BYO bucket.
- It does not require
In both cases, the authoritative source of customer data remains your warehouse; Hightouch stores only the minimal metadata needed to compute and apply changes efficiently.
Bring your own bucket
Hightouch supports two main storage patterns for sync logs and diff metadata:
-
Self‑service plans (default):
-
Hightouch stores query results, diff metadata, and sync logs in an encrypted, Hightouch‑managed cloud bucket.
-
A default short retention period (for example, 30 days) is applied to minimize data at rest while still enabling debugging.
-
Business and enterprise plans (recommended):
-
You can host your own bucket on AWS, Google Cloud, or Azure.
-
Hightouch writes logs and diff metadata directly into your storage, so:
- Data stays within your own cloud account and residency regime.
- You control retention, lifecycle policies, and access management.
For many enterprise deployments, the recommended pattern is:
- Lightning sync engine for in‑warehouse diff computation, and
- BYO bucket for sync logs and any remaining observability data.
This combination ensures both compute and storage remain as close to your own infrastructure and controls as possible.
If you’d like to enable BYO bucket, please .
PII redaction and access control
Sometimes, you need to sync personally identifiable information (PII) to a destination, but you don't want your entire team to have access to it inside Hightouch.
For example:
- You may need to sync emails, phone numbers, or other identifiers to ad platforms for accurate targeting.
- You may want marketers to build audiences that rely on PII under the hood, but without exposing those raw values in the UI.
Hightouch supports a defense‑in‑depth approach for PII, combining workspace‑level governance with field‑level controls:
Workspace governance and RBAC
Use workspace governance and role‑based access control (RBAC) to control who can see and act on sensitive data:
- Use roles and custom roles to limit who can:
- Edit sources and destinations
- View sync logs and row‑level data
- Access Customer Studio schema and traits
- Use SSO/SCIM and group‑based access to centralize control over who can access your workspace and its features.
These controls ensure that only the right teams have access to areas of the product where PII may be visible (for example, logs and row‑level previews).
Data masking and privacy levels in Customer Studio
For additional protection in Customer Studio, use data masking to control how sensitive columns appear across the platform while still using them for activation:
-
When configuring your schema in Customer Studio, you can assign a privacy level to each column. Available levels include Blocked, Redacted, Sync-only, Sync-blocked, and Approved.
-
For example, columns marked as Redacted:
- Can still be used as identifiers or filters behind the scenes
- Will not show raw values in audience previews or insights
-
Hightouch also automatically flags potential PII columns for review, so you can classify them before marketers begin building audiences.
Together, RBAC, privacy levels, and audit logs help ensure that only the right users see sensitive data, and even then, only where it’s strictly necessary.