The Warehouse Sync Logs feature writes sync metadata back into your data warehouse. It makes per-row information from the live debugger available in your warehouse so that you can perform complex analysis, rather than just inspect syncs row-by-row.
When you enable Warehouse Sync Logs, Hightouch logs a corresponding row for every row processed during the sync. This includes the row's status and any errors from processing the row. You can then explore these logs using SQL or BI tools you use on top of your warehouse.
For example, you can:
- Categorize all the errors in your sync using regular expressions and find unexpected errors.
- Filter out previously failed rows from your model using a
JOIN. - Aggregate the sync history to see what rows are changing the most. Flapping rows can be a sign of data integrity issues.
- Visualize row changes in your models over time. For example, you may be interested in seeing how targeted users in an ad campaign changed over the campaign duration.
Refer to the example queries section for concrete examples.
Schema
Hightouch writes sync logs into three tables within the hightouch_audit schema:
- Changelog: This table contains a row for every operation performed by Hightouch. It includes the result of the operation and any error messages from syncing.
- Snapshot: This table contains each row's latest status in your model. The information is similar to the Changelog table, but since it contains the latest status, it's easier to query for some use cases.
- Sync runs: This table contains a log of all the sync runs. You can
JOINthe changelog and snapshot tables to this table for more information on when the sync occurred and how it was configured.
Information across all syncs is written into these same three tables—you can differentiate which rows were part of which sync using the sync_id column.
See the detailed schema section for a detailed description of the available columns.
You can learn more about PII in these tables on the Lightning sync engine page.
Setup
Enabling Warehouse Syncs logs requires you to enable the Lightning sync engine first. Hightouch supports using Warehouse Sync Logs with the following sources:
Required permissions
The user you used to connect your source to Hightouch must be able to write into the hightouch_audit schema. You shouldn't require any additional permissions once you've set up the Lightning sync engine.
Enable Warehouse Sync Logs for a source
To enable logging for all syncs that use a source:
-
Go to
Integrations→Sources. -
Select your source.
-
Open the
Sync logstab. -
Select the log tables you want Hightouch to write to your warehouse:
- Sync snapshots
- Changelog
- Sync runs
- Audience snapshots (optional)
- Audience holdout group logs (optional)
Each of the first three tables also has an Audience syncs only sub-option that limits logging to audience syncs.
-
Save.
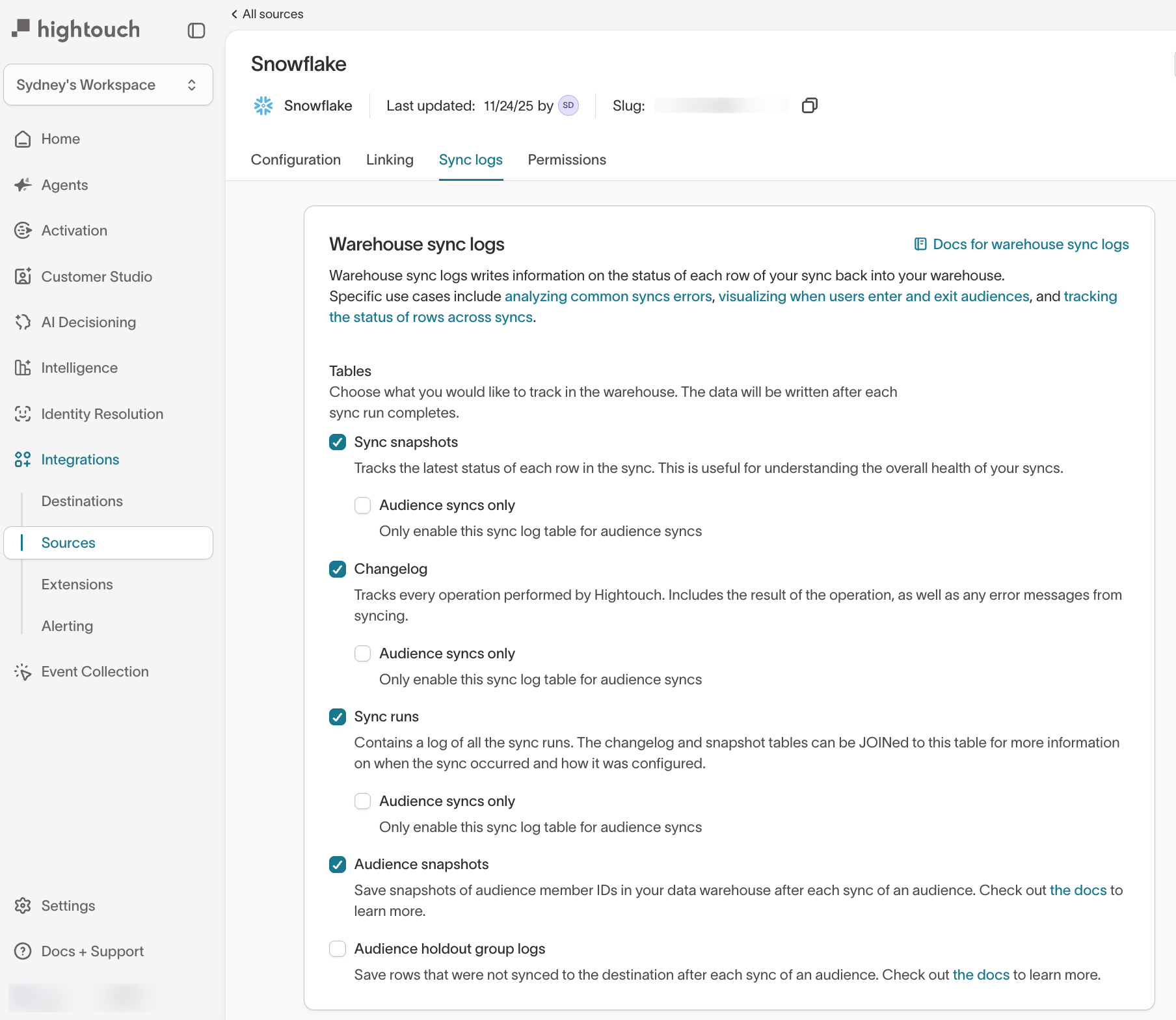
Enabling a table here allows Hightouch to write logs for any sync that uses this source.
Be mindful of storage usage. Sync logs can generate a lot of data depending on how many tables you enable and how often your syncs run. If you only need logs for a few workflows, you can enable them at the sync level instead of the source level to reduce storage. However, enabling logs at the source level ensures logs are always available when debugging issues, which can save considerable time if a sync fails unexpectedly.
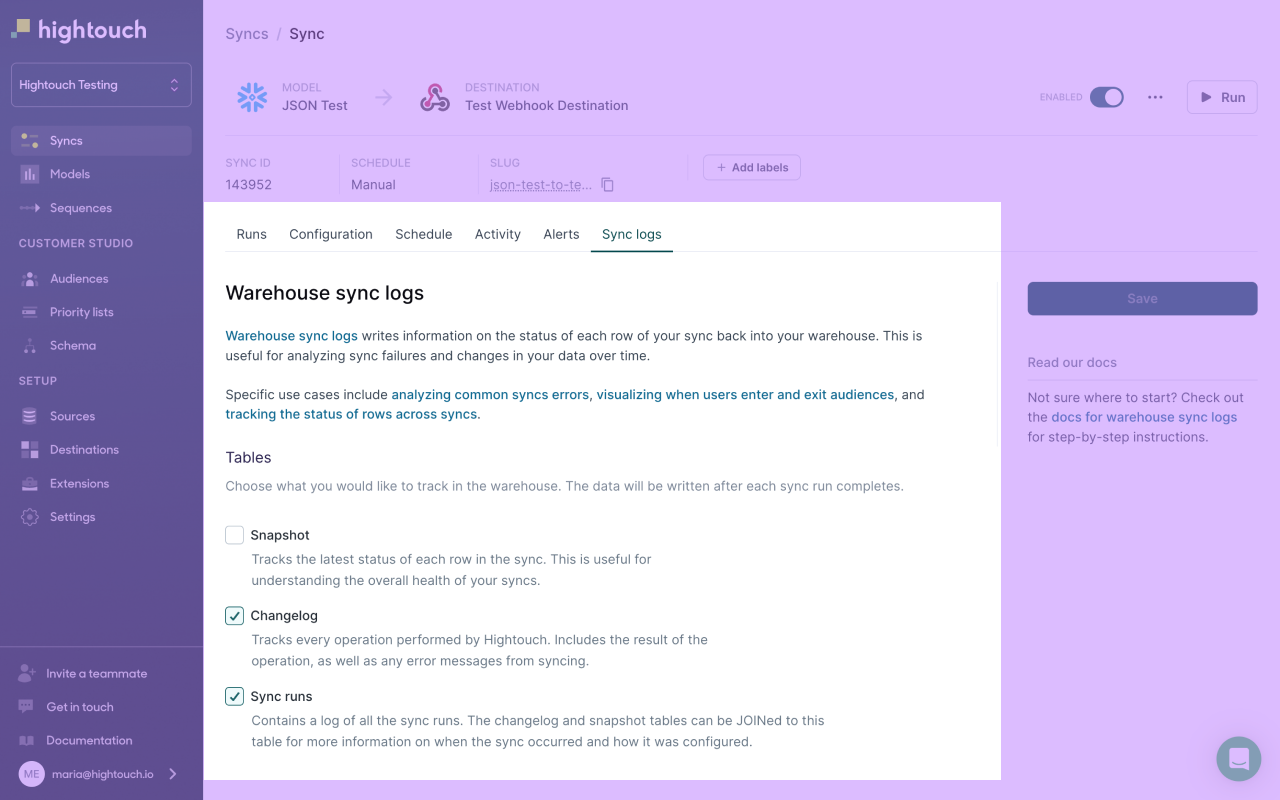
Enable Warehouse Sync Logs for a sync
Use sync-level logging when you only need logs for specific workflows or want to limit storage usage. Use source-level logging when you want logging enabled consistently across all syncs powered by the source.
Warehouse Sync Logs are off for all syncs by default. To enable them on a particular sync:
- Ensure the Lightning sync engine is enabled for the source.
- Go to the Sync Logs tab in the sync's overview page.
- Enable your desired tables: Snapshot, Changelog, and/or Sync runs.
Example queries
The following example queries are written for Snowflake, but you could create similar queries for other sources. Check out Hightouch's dbt package for more use cases.
Get the most common sync error
This SQL groups and counts rows by failure_reason, enabling you to find the most common sync error.
select
failure_reason,
count(*) as c
from hightouch_audit.sync_snapshot
where failure_reason is not null
group by failure_reason
order by c desc

Track when users entered and exited a model
This SQL tracks when users enter and exit a model. It's particularly useful when used with Customer Studio audiences and visualized in a BI tool.
with details as (
select
model_name,
row_id,
op_type as type,
started_at as timestamp,
lag(op_type) over(partition by model_name, row_id order by started_at) as lag_type
from hightouch_audit.sync_changelog c
join hightouch_audit.sync_runs r on c.sync_id = r.sync_id
where op_type != 'changed'
order by model_name, row_id
)
select
row_id as user_id,
model_name as audience,
type,
timestamp
from details
where (lag_type != type or lag_type is null)
order by model_name, row_id, timestamp

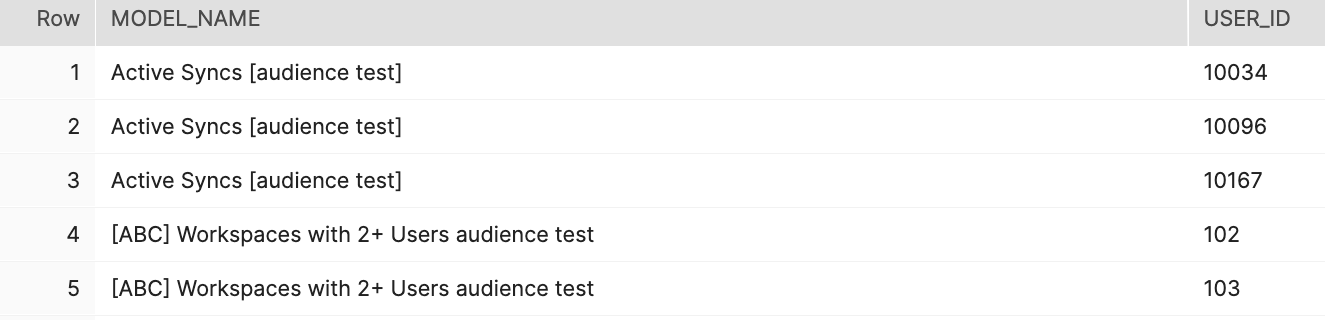
Get the current rows in all models
This SQL finds all current (most recently synced rows that didn't fail) across all models. It's particularly useful to find all members for audiences created in Customer Studio.
with model_names as (
select distinct
sync_id,
model_name
from hightouch_audit.sync_runs
)
select
model_name,
row_id as user_id
from hightouch_audit.sync_snapshot s
join model_names r on s.sync_id = r.sync_id
where s.status != 'failed'
qualify row_number() over (partition by user_id, model_name order by null) = 1
order by user_id
Detailed schema
Hightouch writes to the sync_changelog,sync_snapshot, and sync_runs tables after each sync.
If you've enabled audience snapshotting, you'll also find a hightouch_planner.audience_membership table in your warehouse.
Refer to the audience snapshot docs for its detailed schema.
Changelog table
This hightouch_audit.sync_changelog table is log of all changes across all sync runs. If the same row is synced in multiple sync runs, it has multiple entries in this table.
| COLUMN | DESCRIPTION |
|---|---|
sync_id | The ID of the sync |
sync_run_id | The ID of the sync run |
op_type | Whether the row was added, changed, or removed relative to the last run. This is computed by Hightouch when planning the sync run |
row_id | The value of the row's primary key as defined from the model |
status | Whether the row was successfully synced into destination. They value may be: succeeded - the row was successfully synced, failed - Hightouch attempted to sync the row, but it failed to sync, or aborted - Hightouch planned to sync the row, but didn't attempt to sync. This may happen if the sync may have been cancelled, or the sync encountered a fatal error that terminated the run early. |
failure_reason | If the status is failed, this field contain a string describing why the row failed to sync. |
fields | A JSON object of the raw data from the model that is synced into the destination. Note that this is the raw data from the warehouse, not the payload that Hightouch sent to the destination. This column has limitations in Redshift (see FAQ for details, below). |
split_group | (Optional) The experiment group name. If no syncs are using experiments, this column isn't created. |
Snapshot table
This hightouch_audit.sync_snapshot table stores the current status of each row in the most recent sync run, even if the row wasn't synced in the most recent run.
After each run, the old statuses for the sync are dropped and replaced with updated statuses.
| COLUMN | DESCRIPTION |
|---|---|
sync_id | The ID of the sync |
op_type | Whether the row was added, changed, or unchanged relative to the last run |
row_id | The value of the row's primary key as defined from the model |
status | The status of the row. See the sync_changelog.status description for a list of possible statuses |
failure_reason | If the status is failed, this contains a string describing why the row failed to sync |
fields | The fields from the model for this row. See the sync_changelog.fields description for more information |
split_group | (Optional) The experiment group name. If no syncs are using experiments, this column isn't created. |
Sync runs table
This hightouch_audit.sync_runs table stores general metadata information about each sync run. You can join the sync_changelog and sync_snapshot tables using the sync_id column.
| COLUMN | DESCRIPTION |
|---|---|
sync_id | The ID of the sync |
sync_run_id | The ID of the sync run |
primary_key | The primary key column of your sync as defined on the model attached to the sync. |
destination | The destination type, for example, Salesforce or Braze |
model_name | The name of the model attached to the sync |
model_id | The ID of the model attached to the sync |
status | The status of the sync run. This will be either succeeded or failed. In general, the per-row results of the sync are a better indication of status. |
error | The sync-level error if the sync terminated early |
started_at | When the sync run started |
finished_at | When the sync run finished |
num_planned_add | The number of planned adds. |
num_planned_change | The number of planned changes. |
num_planned_remove | The number of planned removes. |
num_attempted_add | The number of planned adds that were actually attempted. |
num_attempted_change | The number of planned changes that were actually attempted. |
num_attempted_remove | The number of planned removes that were actually attempted. |
num_succeeded_add | The number of planned adds that were successfully synced to the destination |
num_succeeded_change | The number of planned changes that were successfully synced to the destination |
num_succeeded_remove | The number of planned removes that were successfully synced to the destination |
num_failed_add | The number of planned adds that were attempted, but failed to get synced into destination |
num_failed_change | The number of planned changes that were attempted, but failed to get synced into destination |
num_failed_remove | The number of planned removes that were attempted, but failed to get synced into destination |
FAQ
What's the performance impact of enabling Warehouse Sync Logs?
The performance impact of enabling Warehouse Sync Logs is low since it reuses data already present from the Lightning sync engine. Hightouch only writes the rows after Hightouch syncs to the destination, meaning there is no effect on destination throughput.
Pruning entries in the history tables is safe. Doing so doesn't affect future syncs, though the deleted rows won't be rewritten into the history tables.
What are the limitations in Redshift?
Because Redshift does not support strings longer than 65,535 bytes,
it is not possible to store JSON representations of arbitrary length in the warehouse sync logs. Hightouch attempts
to store model data in the fields column of sync_changelog and sync_snapshot, but if the model contains either
long strings or a large number of fields, some fields may be truncated.
Truncated values in sync_changelog.fields and sync_snapshot.fields do not mean that values were truncated
when Hightouch synced data to the destination; it's purely a limitation of the warehouse logs.