To learn about defining data models for Audiences, refer to the Customer Studio documentation.
Hightouch models define and organize the data you want to query from a source.
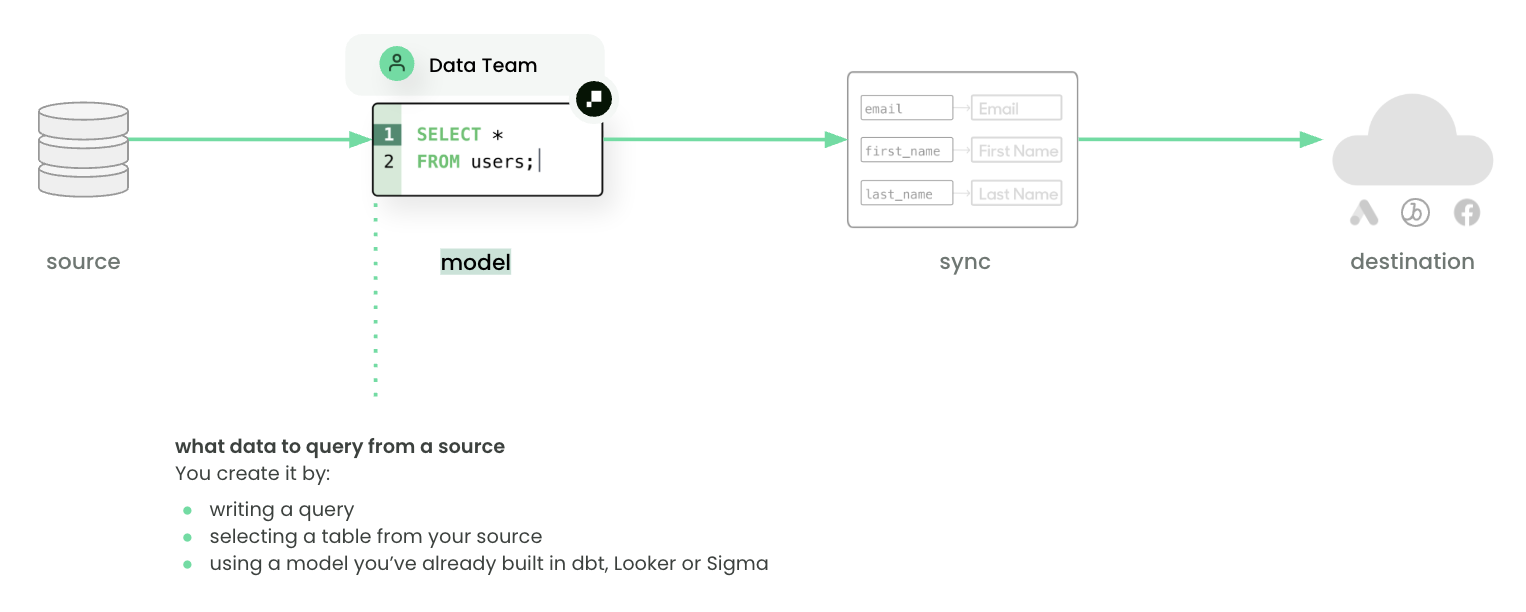
To create a new model, navigate to the Models page and click Add model. Next, select one of you the sources you've setup. Then choose a modeling method:
- SQL editor
- Table selector
- dbt model selector
- Looker
- Sigma
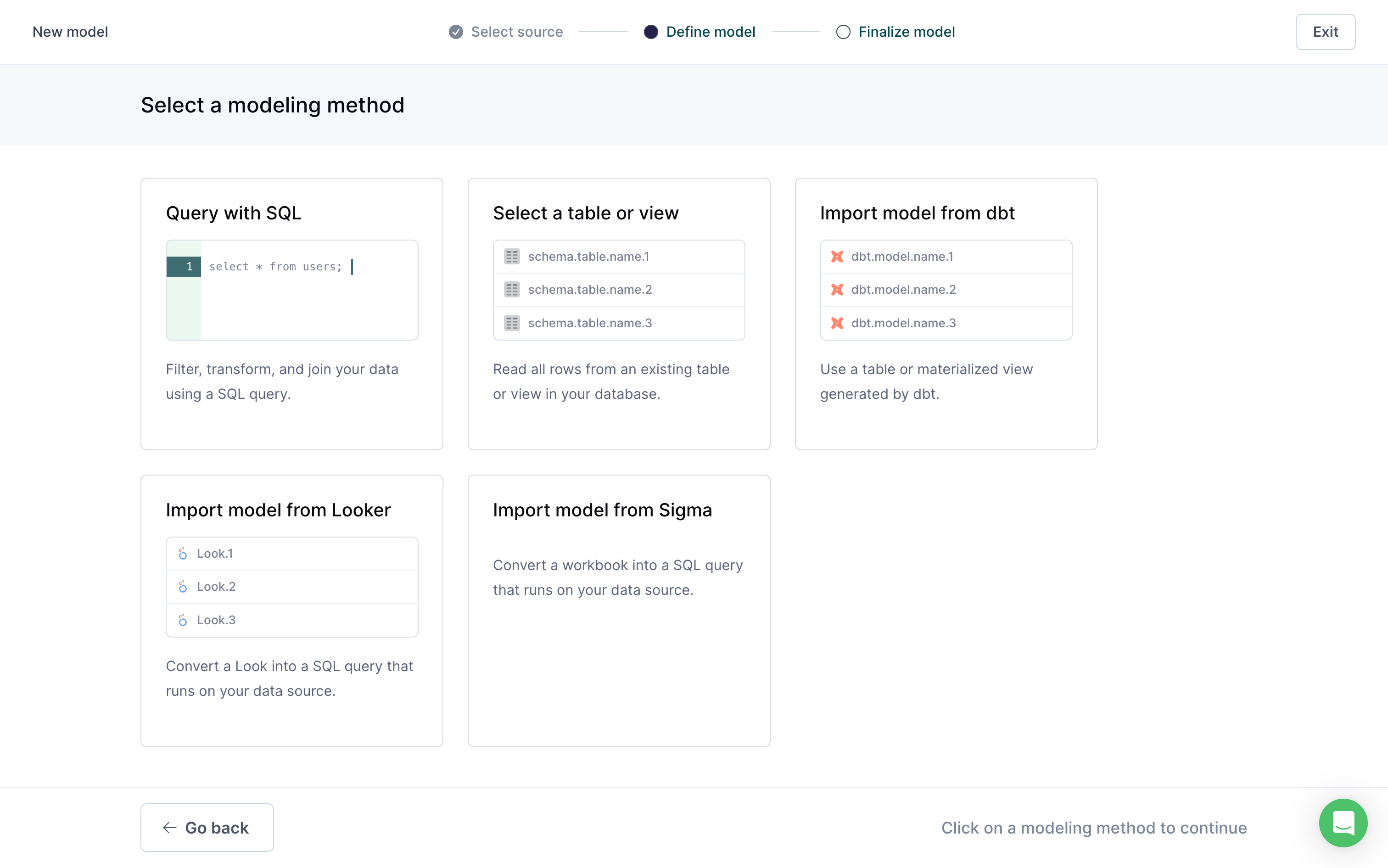
Supported modeling methods depend on the source. Refer to source documentation to learn about supported modeling methods.
Refer to the SQL editor and table selector docs for details on how to use those modeling methods.
Refer to the Extensions documentation to learn more about how to connect Hightouch to these platforms and build Hightouch models using existing dbt models, Looker Looks, or Sigma workbooks.
Unique primary key requirement
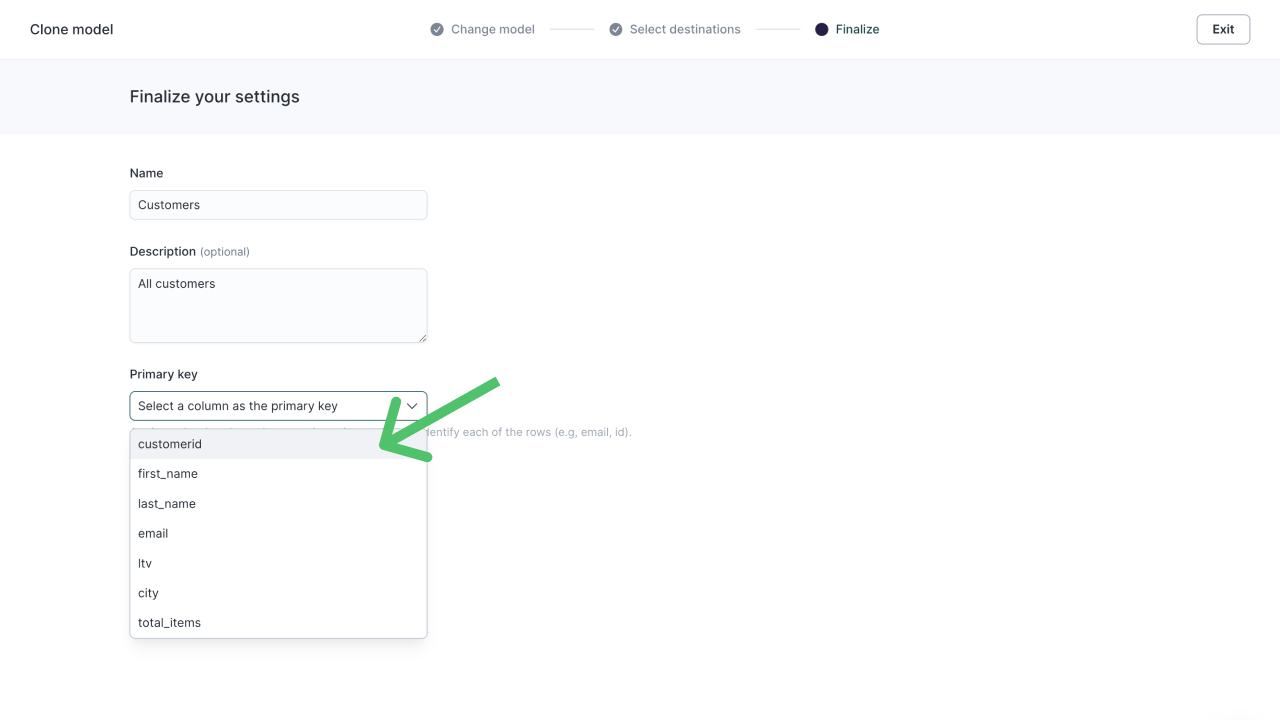
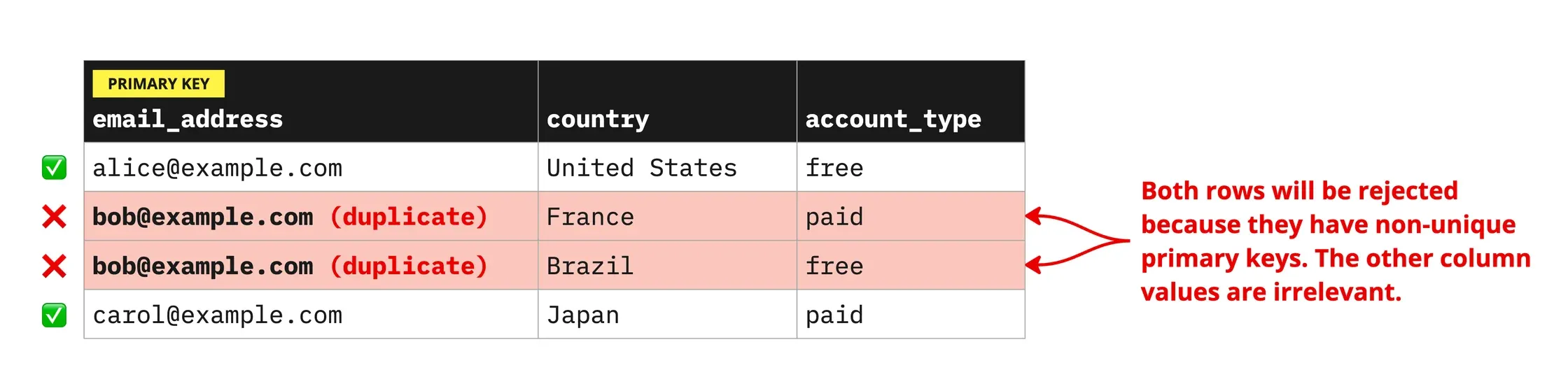
Regardless of which method you use to build your models, you must always designate a column as the model's primary key, which is a non-repeating, non-null value that uniquely identifies each row. For example, if you have a table containing customer profiles, you might have a column named CustomerID that distinguishes each customer from all the others. (While several customers can share the same first name, location, or even phone number, they cannot share the same CustomerID.)
Select your primary key column when prompted during model setup.
If your dataset doesn't include any truly unique columns, you can use the SQL editor to either filter out duplicate rows or create a composite column to use for your primary key. If you're not using the SQL modeling method or if SQL isn't supported by your source, you need to make changes to your data upstream to ensure it includes a unique column.
Rows with null primary keys will be ignored by the sync.
Hightouch's sync engine relies on unique primary keys to detect when rows are added, changed, or removed in a data model. See the change data capture docs to learn how Hightouch accomplishes this.
As a safeguard to prevent duplicate records from reaching to your destination, Hightouch will automatically filter out rows with non-unique primary keys. In the sync logs, they will be marked as “Rejected”, just like any other row-level error. It is safer to reject these rows than to risk syncing wrong or duplicate data.
Make sure to read through the primary key updates section before making any changes to your primary key.
Updating a primary key
Hightouch relies on unique primary keys to detect when rows are added, changed, or removed. Therefore, altering the primary key requires Hightouch to reset its change data capture (CDC) for syncs that depend on your model.
When changing a primary key, you will be asked whether or not a backfill should be performed. Two options are available:
Reset CDC without backfill: By electing to reset CDC without a backfill, you are instructing Hightouch to ignore the current state of your model and to track only rows that are added, changed, or removed in the future. The next sync run will be used as an opportunity to capture a snapshot of your model, but no data will be sent to the destination. Thereafter, future sync runs will track new changes only. (This option is recommended for insert-only use cases like conversion events, operational alerts, and other situations where a backfill would create undesired duplicate records. Beware that skipping the backfill may cause your destination to drift out of sync with your data model.)
Reset CDC with backfill (i.e., full resync): By electing to reset CDC with a backfill, you are instructing Hightouch to perform a full resync of your entire data model. This means that Hightouch will not perform any diffing and will instead process every row as if it's the first time the sync has ever run. All rows will be sent to the destination again. (This option may be preferred for syncs to CRMs and other services that are configured to update existing records instead of creating new ones. Do not use this option if a backfill will create duplicates or trigger downstream actions.)
By default, proceeding with your primary key change will immediately trigger a run for every sync that depends on your model. It is necessary to reset CDC as quickly as possible after the primary key is updated. However, you can opt out of this behavior, in which case the CDC reset will be deferred until the next sync run.
You don't need to manually trigger a full resync if you change the primary key column's data type. If you change the primary key's data type in the model configuration, your sync will process normally. If you make this change in your source or in the SQL editor, the entire model query result set is automatically resynced as if you triggered a full resync. As outlined in the full resync prerequisites section, this can create duplicates in your destination data. You may wish to reset change data capture without a backfill instead.
Row and column ordering
Hightouch’s sync engine is optimized for performance and scale. It divides data into batches and processes them in parallel so large syncs complete quickly. This distributed design means rows and columns may be sent to destinations in a different order than they appear in your model.
This is normal behavior and does not affect which records are synced or the values written. If you notice that files or datasets appear in a different order between runs, that variation is expected. Any apparent ordering you observe is incidental and not guaranteed to remain consistent over time.
This applies to all destination types, including spreadsheets and file uploads. Even if you use a custom SQL model with an ORDER BY clause, that ordering applies only when previewing the model. The order in which rows and columns are processed during syncs can still vary.
Data types and casting
When you define a model, Hightouch doesn't change the data types found in your source unless otherwise specified. You can view a column's type in a model's Columns tab.
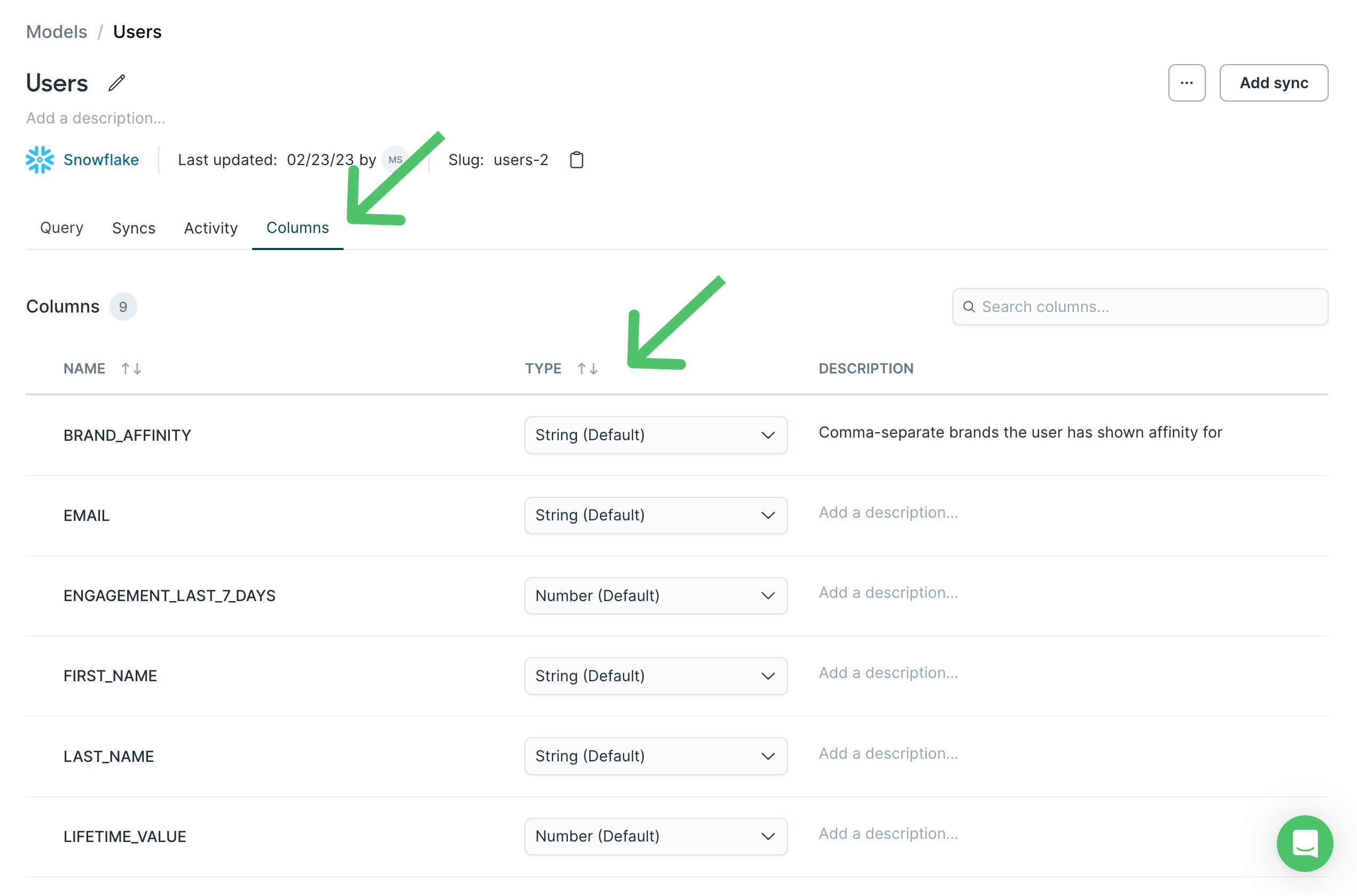
To safeguard your syncs from failing, the data types your model returns must align with your destination's data type expectations. If your source data types don't match your destination's expectations, you can use data casting while setting up your models.
Hightouch intentionally stringifies your chosen primary key column for enhanced performance during change data capture. If you need to sync the primary key column as a non-string value, use SQL aliasing in your model to create a new column specifically for syncing.
Preview model results
When first defining a model, it's highly recommened to Preview results before you continue with setup. Previewing lets you validate the data your model returns before syncing it to downstream destinations.
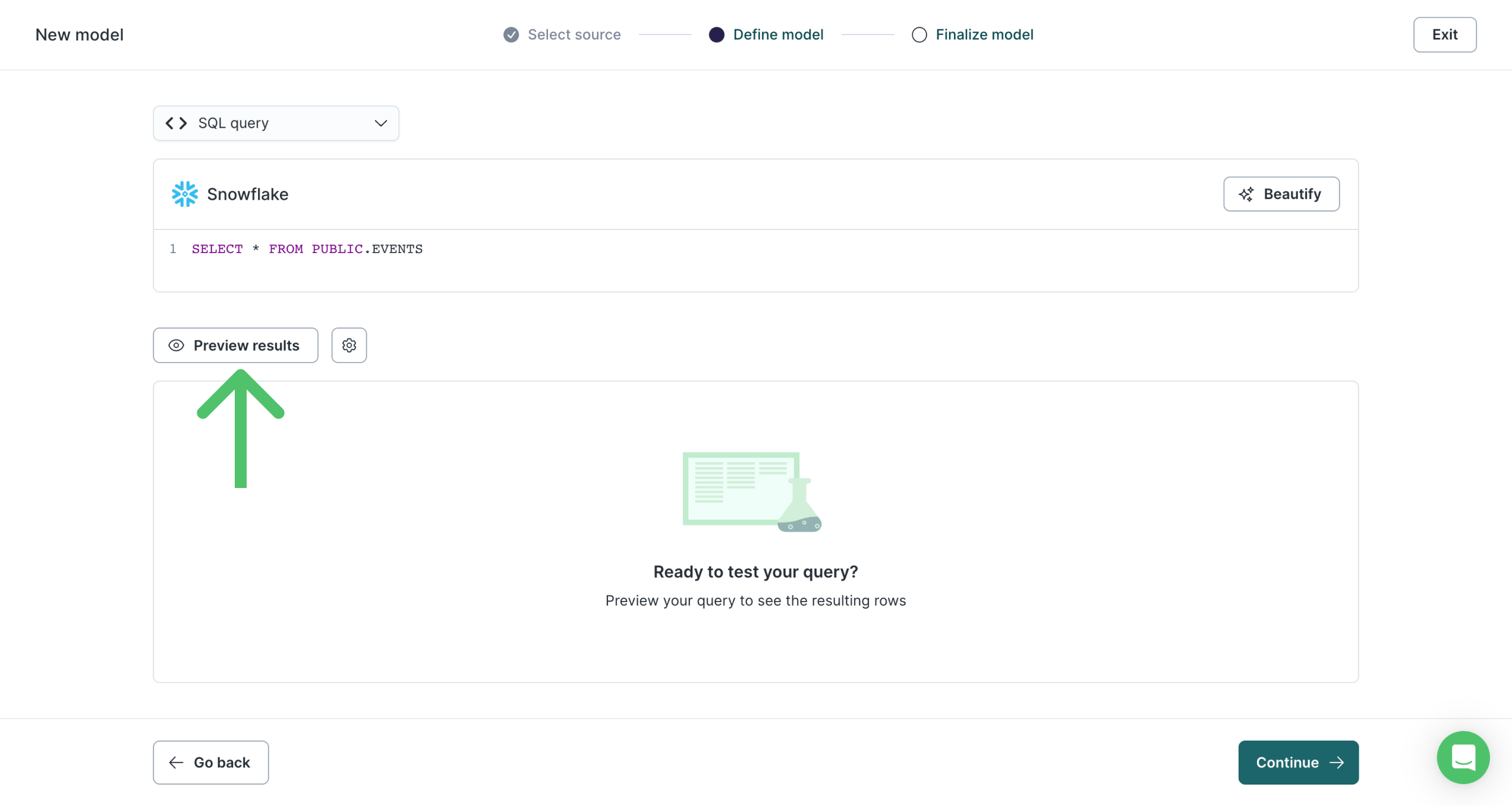
Previewing a model's query results can also be helpful when troubleshooting issues. To preview an existing model's results, open the model's overview page and click Edit.
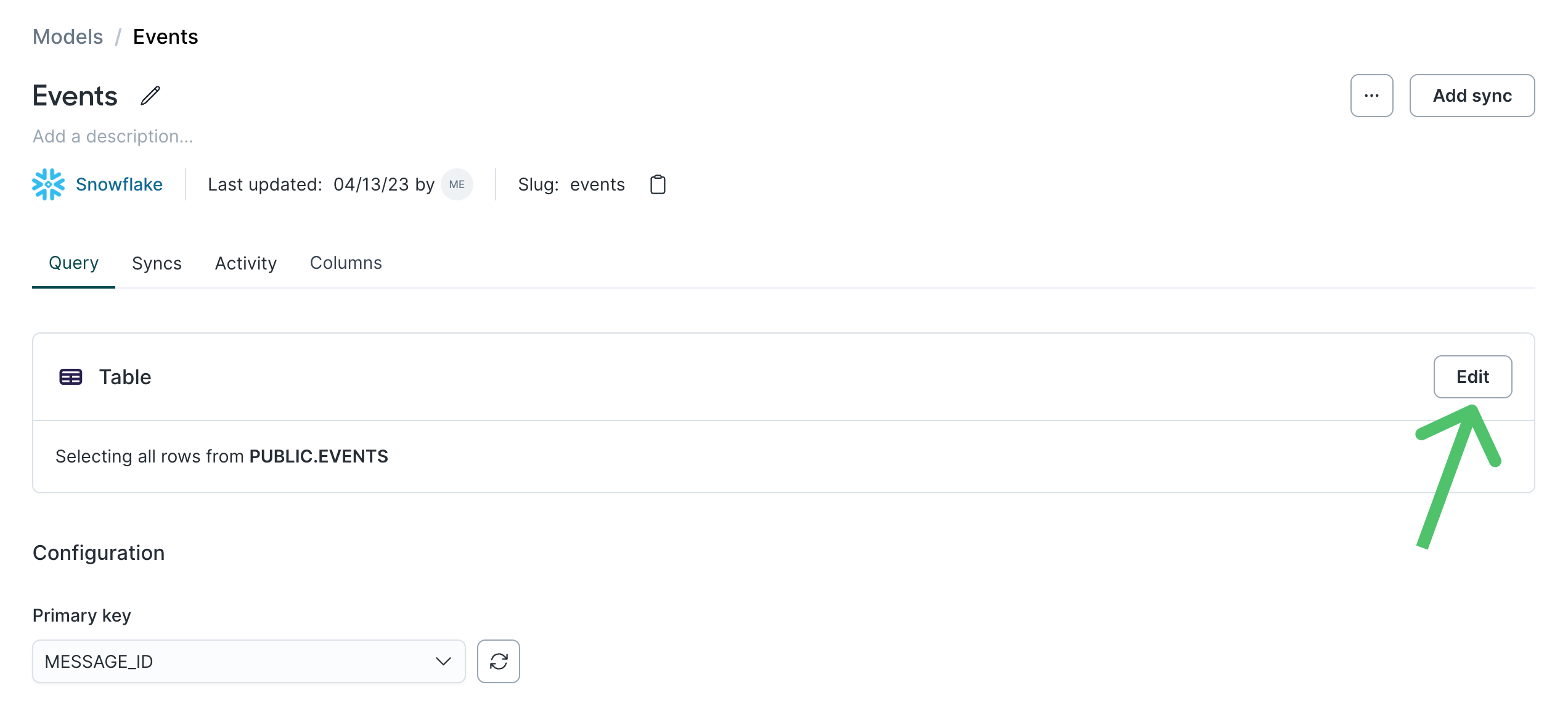
You can then select to Preview results.
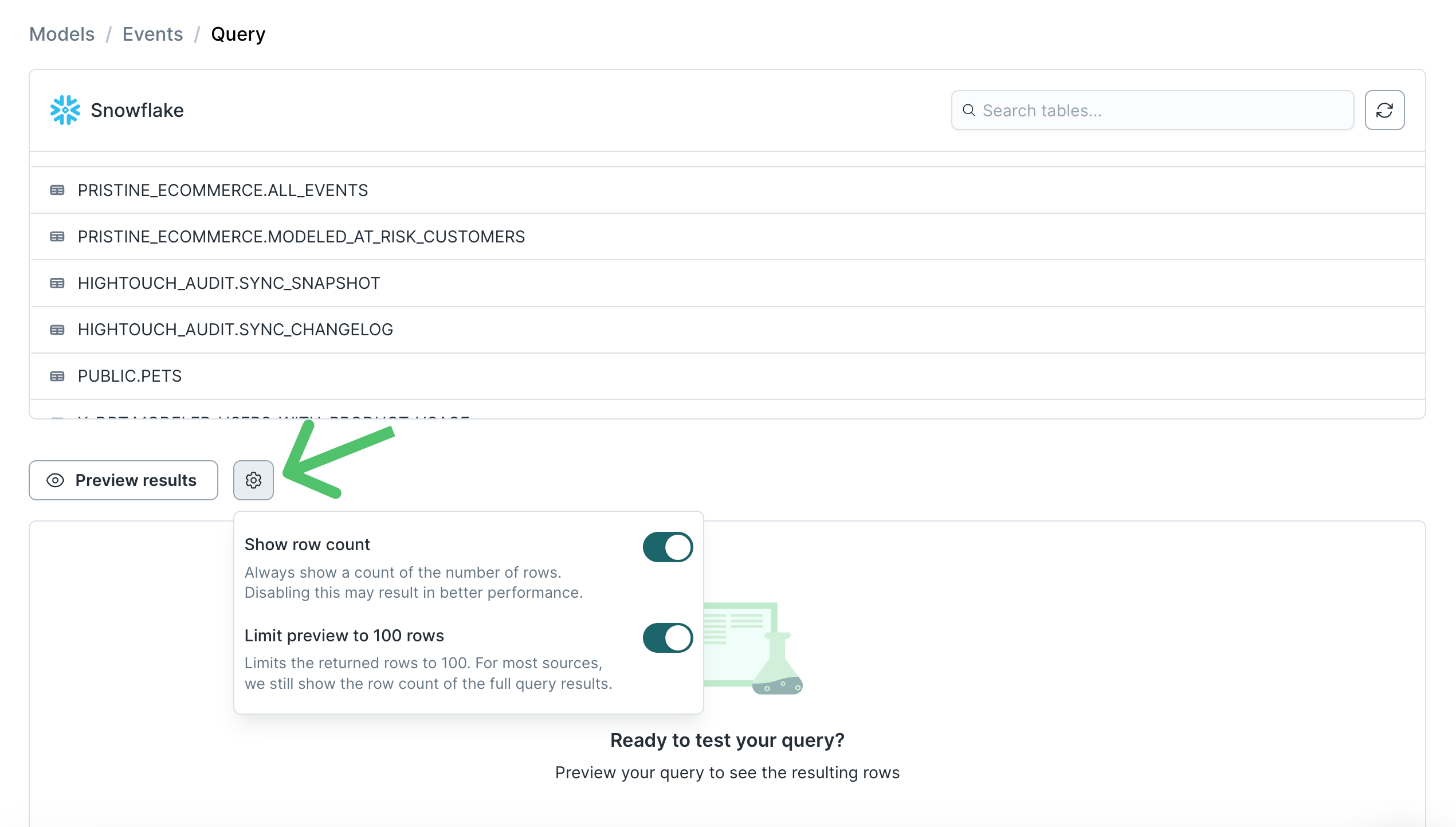
If you want to display all model rows, click the gear symbol, then toggle off Limit preview to 100 rows. You can also turn off Show row count to improve loading performance for larger data models.
Column descriptions
Hightouch automatically pulls in column descriptions from supported sources. Column descriptions are supported for
Snowflake, BigQuery , Databricks, and other SQL-based sources that provide the standard INFORMATION_SCHEMA.COLUMNS
table, such as PostgreSQL, MySQL, MSSQL, and their cloud-managed variants. You can add descriptions to your models'
columns so that team members (and your future self) can better understand the data. Go to a model's Columns tab and
click the a column's description to edit it. If you edit a description in Hightouch, your version displays instead
of the comment on the source column.
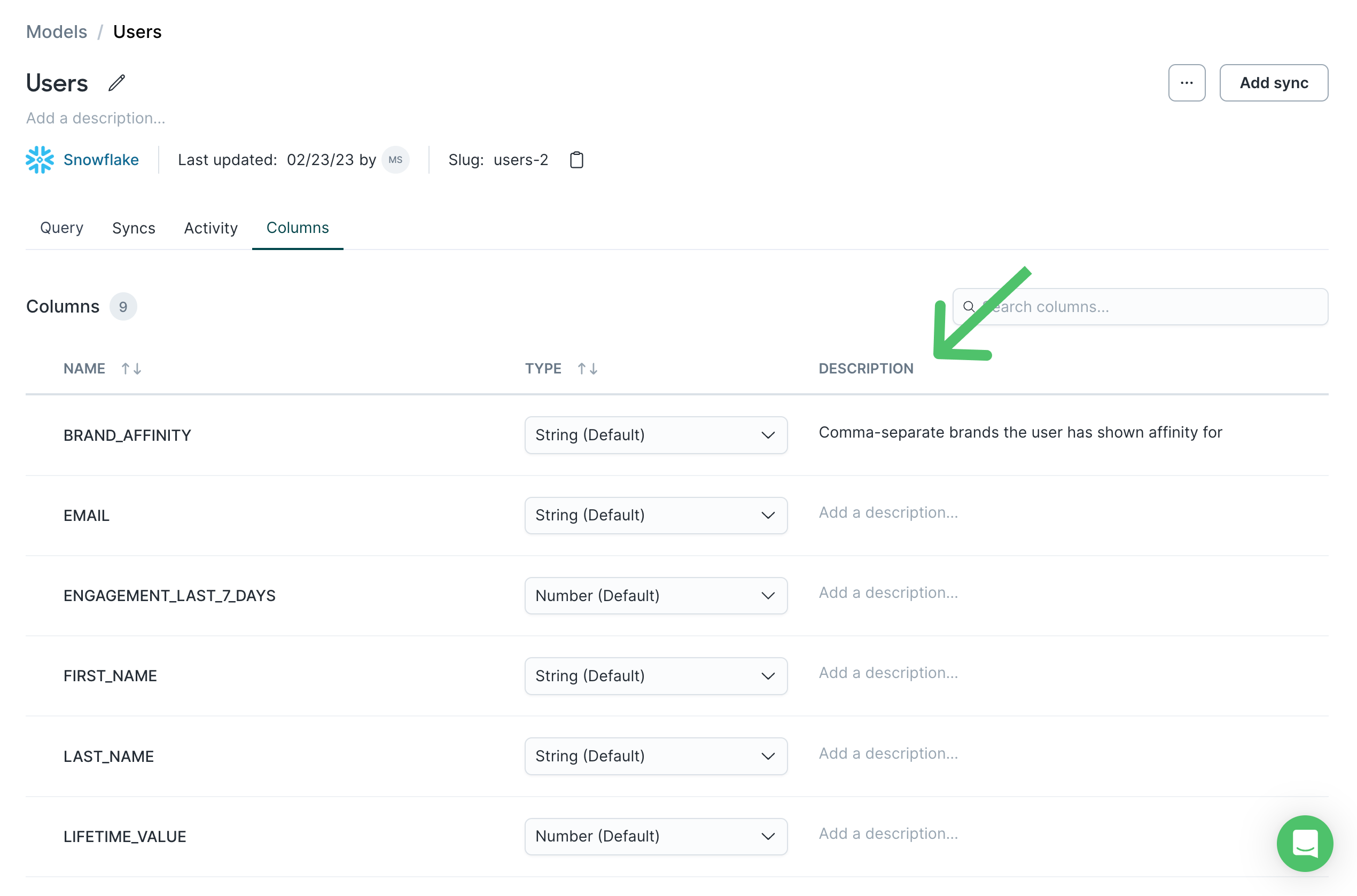
If you're using the dbt extension to build models, Hightouch automatically pulls in columns descriptions from dbt.
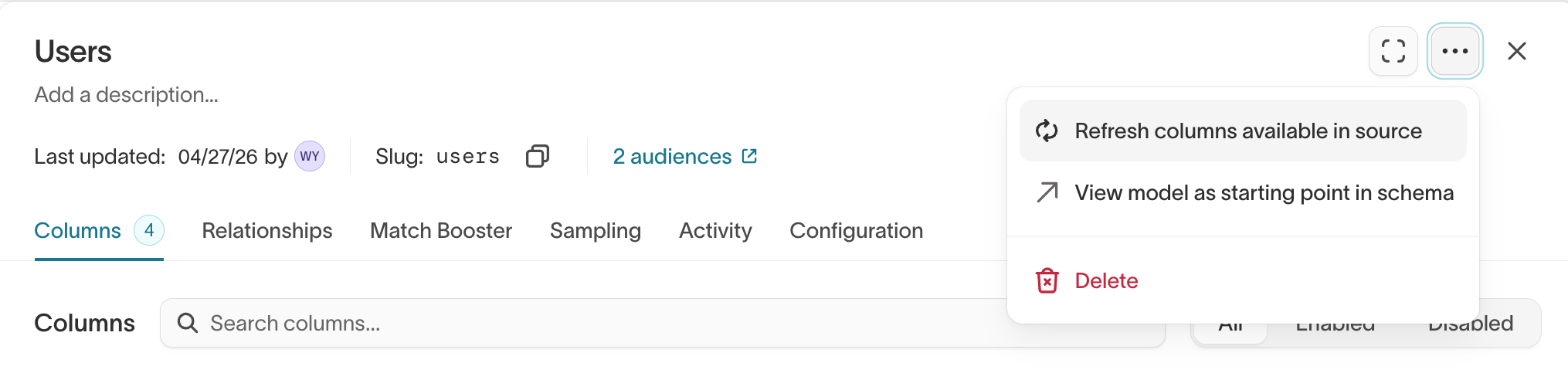
Updating column descriptions from the source
To update column descriptions from your source, you can navigate to any model from that source -->
click the Refresh columns available in source button.
Alternatively, you can trigger this refresh by navigating to the table selector and refreshing the table list. The table selector is available in two places:
-
Activation -> Models -> any model within the source
-
Customer Studio -> Schema -> select a model -> Query -> edit.
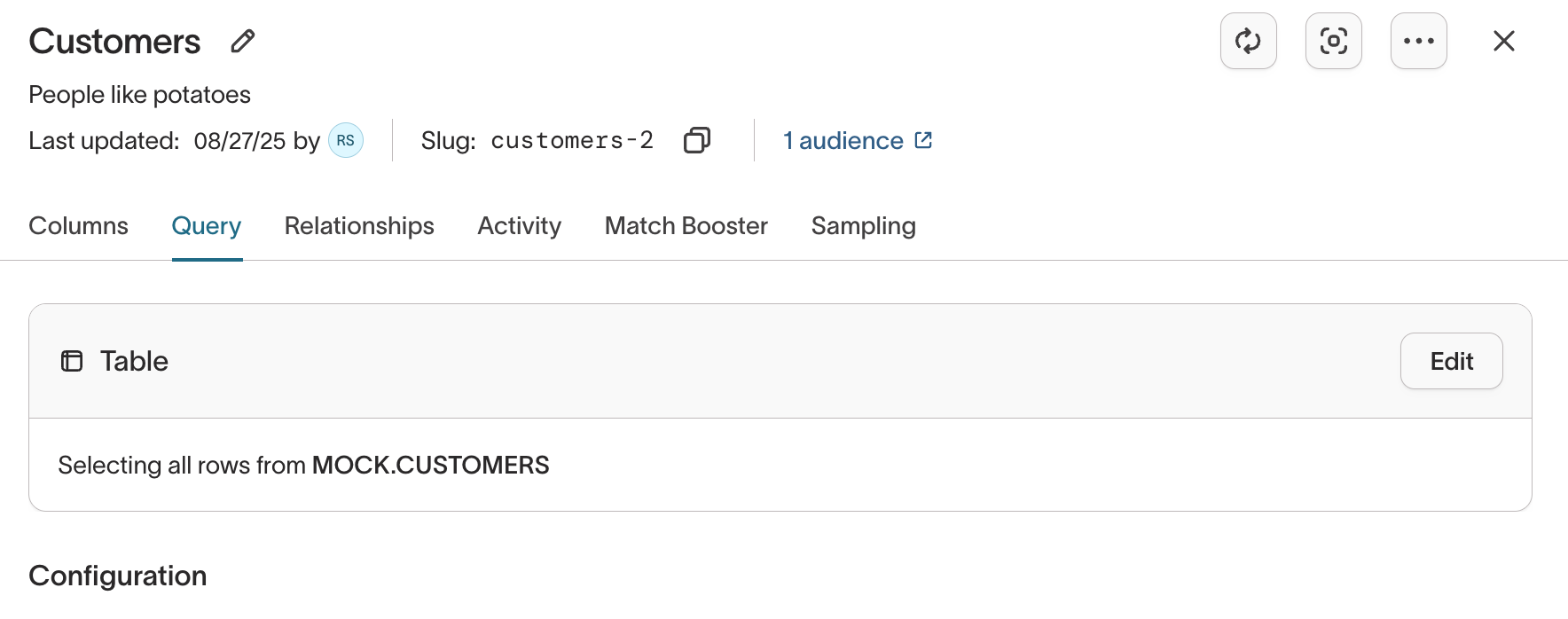
Once in the table selector, click the refresh icon to refresh the tables available from that source, this also updates the column descriptions.

Clone models
After creating a model, you can clone it by opening the horizontal three-dot menu on its overview page and clicking Clone.
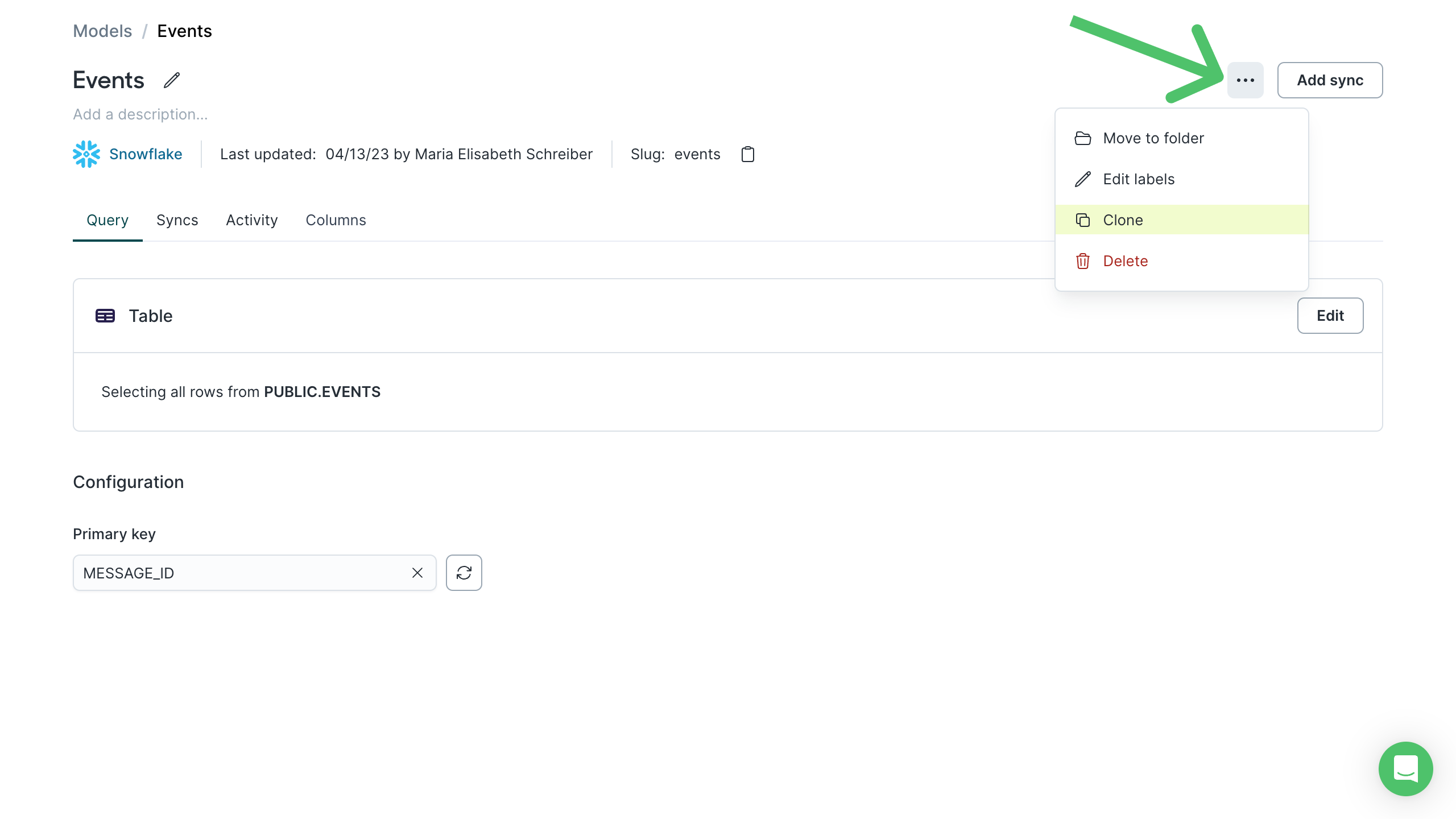
This opens a new page where you can:
- edit and preview the cloned model's query
- select which syncs to clone, if the model you're cloning has syncs associated with it
- give it a custom name and description
- confirm which model column to use as the primary key
Once you finish creating the cloned model, you can further edit it and configure additional syncs on it, like any other model.