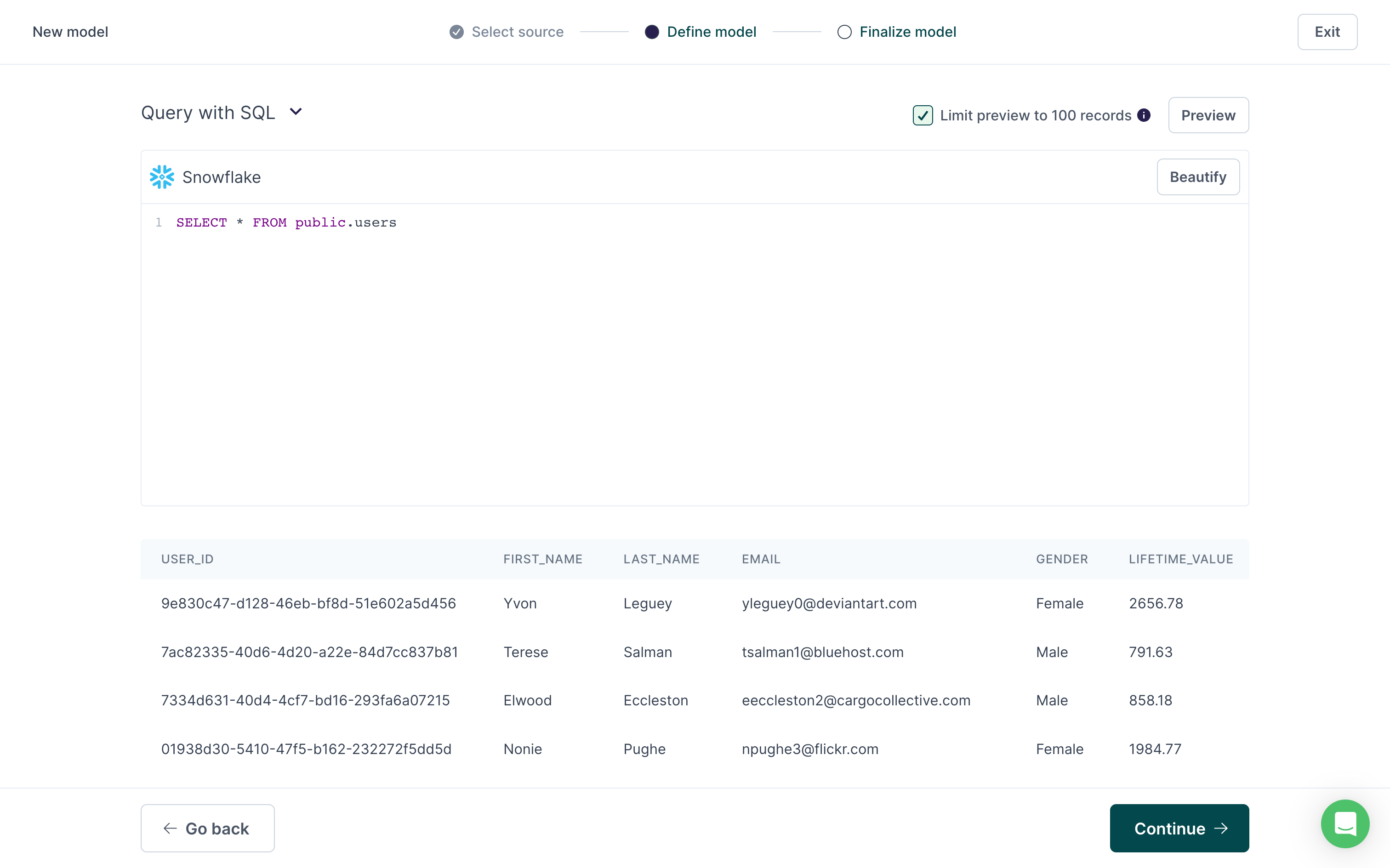
With the SQL editor modeling method, you can write a SQL query to define your model. The SQL editor can execute whatever SQL is native to your warehouse or database.
If you encounter warehouse query failures while previewing or running downstream syncs, see Resolve SQL compilation errors.
Your query depends on the data in your model. For example, if you are using the Sample B2B SaaS source, you can use the following query to select the entire public.users table:
SELECT * FROM public.users
Before you can continue, you must click Preview to see a preview of the data. By default, Hightouch limits the preview to the first 100 rows. Once you've confirmed that the preview contains the data you expect, click Continue.
You can't save a model if your query doesn't return any results. If you need to save a model with such a query because you expect there to be results in the future, see the save a model without results section.
The last step for model setup is to enter a descriptive Name and select the column to use as a Primary key. You can optionally select a folder to move the model to.
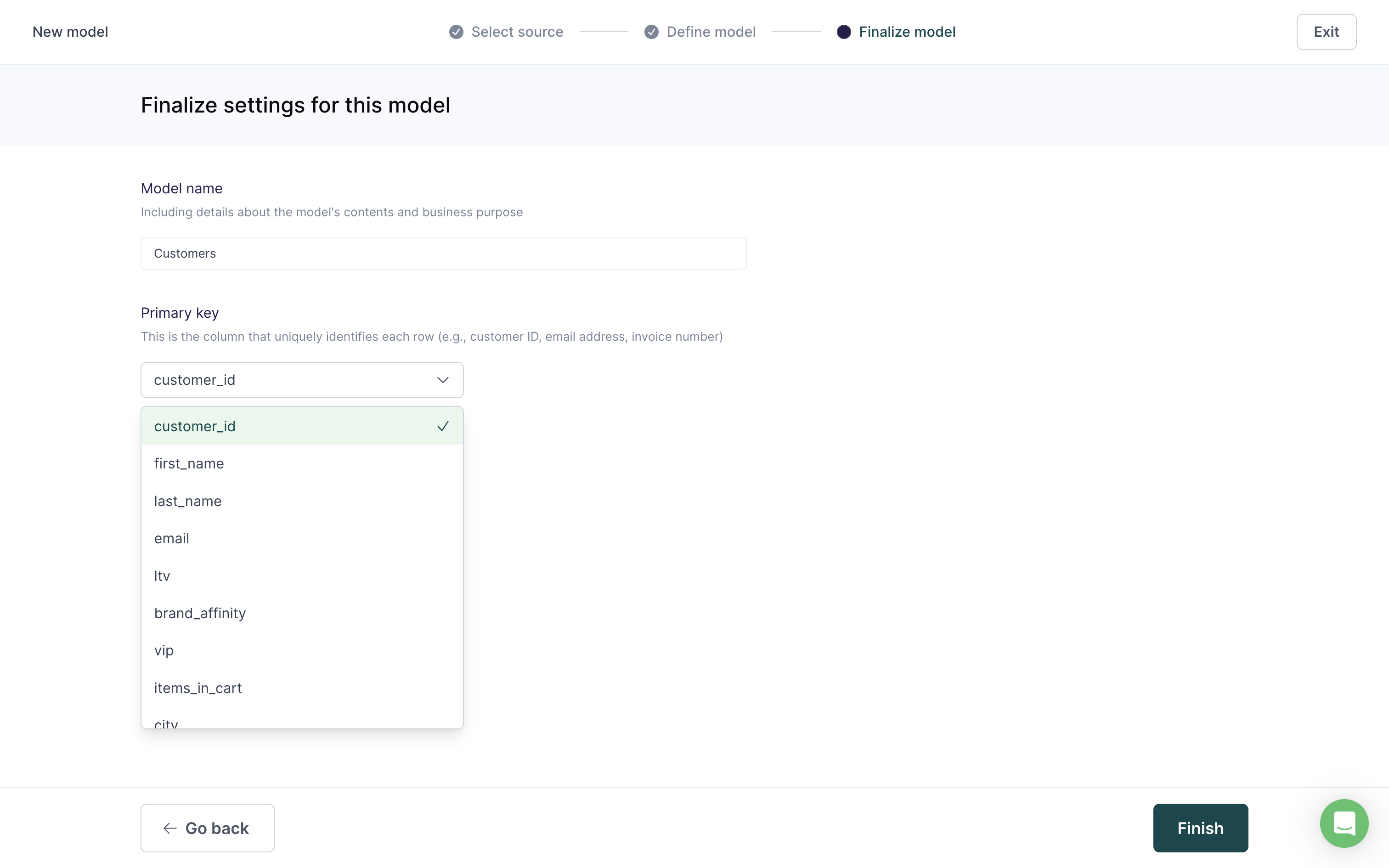
Click Finish to complete your model setup.
Unique primary key requirement
All models require a unique primary key. If your dataset doesn't inherently include any truly unique columns, you can use SQL to either:
- filter out duplicate rows, if you're not concerned about losing data from one or more of the duplicated rows
- create a composite column to use for your primary key
As explained in the primary key updates section, if you alter a model's primary key by selecting a different column, you will be prompted to perform a full sync or reset the change data capture for all syncs that depend on that model. Be careful when modifying primary keys. If you keep the same column name but alter the way its values are calculated, some records may be added or deleted in your destination, depending on how your sync is configured.
Hightouch intentionally stringifies your chosen primary key column for enhanced performance during change data capture. If you need to sync the primary key column as a non-string value, use SQL aliasing in your model to create a new column specifically for syncing.
Filter out duplicates
When you write a SELECT statement to define your model, you can use a GROUP BY clause to retrieve only the unique rows based on the column you want to use for your primary key:
SELECT *
FROM users
GROUP BY primary_key_column
This query returns only one row for each unique primary_key_column value, while ignoring the duplicates.
This query returns one row for each primary_key_column value, so if there are multiple rows with the same primary_key_column value, only one of them will be returned.
If you want your model's query results to return every row in your dataset, it's better to create a composite primary key.
Composite primary keys
If your dataset doesn't inherently include a truly unique primary key, you can create one. For example, in a CRM, you may have users that are identified by email, but belong to multiple organizations:
| org_id | created_at | |
|---|---|---|
| 3 | alice@example.com | 2023-01-18 |
| 1 | bob@example.com | 2022-05-06 |
| 3 | bob@example.com | 2022-12-13 |
| 2 | carol@example.com | 2023-03-29 |
The user bob@example.com belongs to both org_id:1 and org_id:3. Their email address is unique within each organization but non-unique across organizations. Therefore, if you were to select email as the primary key, downstream destinations receiving the data would likely reject these rows.
To ensure a sync with this type of data includes all records, you can use a hash function for the model's primary key. The hash should combine enough columns in the data to create a unique value, for example, org_id and email.
SELECT org_id,
email,
created_at,
HASH(CONCAT(org_id, '-', email)) AS composite_key
FROM users
This query selects the org_id, email, and created_at columns, and creates a composite_key column.
The composite_key column contains a hash of the concatenation of org_id and email, creating a unique value for each row.
| org_id | created_at | composite_key | |
|---|---|---|---|
| 3 | alice@example.com | 2023-01-18 | 123456780 |
| 1 | bob@example.com | 2022-05-06 | 987654321 |
| 3 | bob@example.com | 2022-12-13 | 709230458 |
| 2 | carol@example.com | 2023-03-29 | 382910382 |
You would then select the composite_key column as the primary key for the model.
Because the composite keys for the bob@example.com rows are unique, Hightouch would sync both rows to the destination.
Save a model without results
You can't save a model if your query doesn't return any results. If you need to save a model with such a query because you expect there to be results in the future, add the following SQL to the end of your query:
UNION ALL
select 'ignore', 'ignore', 'ignore'
This SQL adds a row of 'ignore' values that don't match against anything in your destination but are always present so you can save the query.
If your column datatype isn't a string, you can replace 'ignore' with a null value.
The number of 'ignore' or null values needs to be the same as the number of columns in your model.
Exclude rows with null values
Some destinations reject requests when required fields contain null values.
You can prevent syncs from sending null values using the Don't sync null values option in the advanced mapper.
If you want to exclude rows with null values at a model level, you can include the following SQL in your model defintiion:
SELECT *
FROM your_table
WHERE column1 IS NOT NULL AND column2 IS NOT NULL AND column3 IS NOT NULL;
Be sure to change column1, column2, etc. to your column names and to include any columns where you believe there could be null values.