Prepare your data to build a customer identity graph
Audience: Platform admin, data or analytics engineer
Prerequisites: IDR overview →, Setup steps →
Before you can resolve identities in Hightouch, you'll need to prepare your source data. This article walks you through how to structure and configure your data for use in an Identity Resolution (IDR) project, which powers your customer identity graph.
What is a customer identity graph?
A customer identity graph connects identifiers (like emails, device IDs, and phone numbers) across your datasets to form unified customer profiles. Each graph is built from an IDR project that defines:
-
Which source tables to include
-
Which columns represent identifiers
-
How records are matched across models
-
Whether to use deterministic, probabilistic, or hybrid matching strategies
The result is a set of deduplicated identities, each with a unique HT_ID, that you can use across Hightouch for targeting, analytics, and personalization.
What you'll prepare
| Element | Description |
|---|---|
| Input model | A primary table where each row represents an individual (e.g. users) |
| Identifier mappings | Map model columns (e.g. email, phone_number) to identifier types used for matching |
| Input models | Supporting datasets (e.g. orders, devices, web events) joined via shared identifiers |
| Match strategy | Select deterministic, probabilistic, or both based on your data |
| Confidence thresholds | (Optional) Define match strength tiers (Exact / Strict / Loose) for probabilistic matching |
| Golden Record | (Optional) Rules for selecting the most trusted value per trait |
Choose a match strategy
Your data quality and structure will determine which match strategy to use:
| Use case | Recommended strategy |
|---|---|
| Stable IDs, clean login events | Deterministic |
| Messy, user-entered data (e.g. lead forms) | Probabilistic |
| Mixed-quality data across systems | Hybrid |
You can use deterministic matching alone—or enable probabilistic matching to improve coverage.
Probabilistic matching uses similarity across multiple identifiers (e.g. name, email, phone) and assigns confidence scores to each match.
Step-by-step: prepare your data for Identity Resolution
-
Go to Identity Resolution and click Add identity graph
-
Choose a Lightning-supported data warehouse (Snowflake, Databricks, and BigQuery) that contains the data you want to use.
Info: Identity graphs are warehouse-specific. To build graphs across multiple sources, create one per warehouse.
- Choose your input model (e.g.
users,customers,contacts).- Each model must include a timestamp column for incremental processing:
- Use an event timestamp for event models
- Use a
last_updated_ator similar field for static records - If no timestamp exists, define one in your model SQL (e.g.
CURRENT_TIMESTAMP)
- Each model must include a timestamp column for incremental processing:
Within each model, map relevant columns to standard identifier types. These mappings determine which identifiers Hightouch uses when evaluating record matches.
What Are Identifiers?
Identifiers are fields that help link records across systems. Common examples include:
-
Email address
-
Phone number
-
Full name
-
User ID or customer ID
-
Anonymous ID (e.g. session ID)
-
Mailing address or postal code
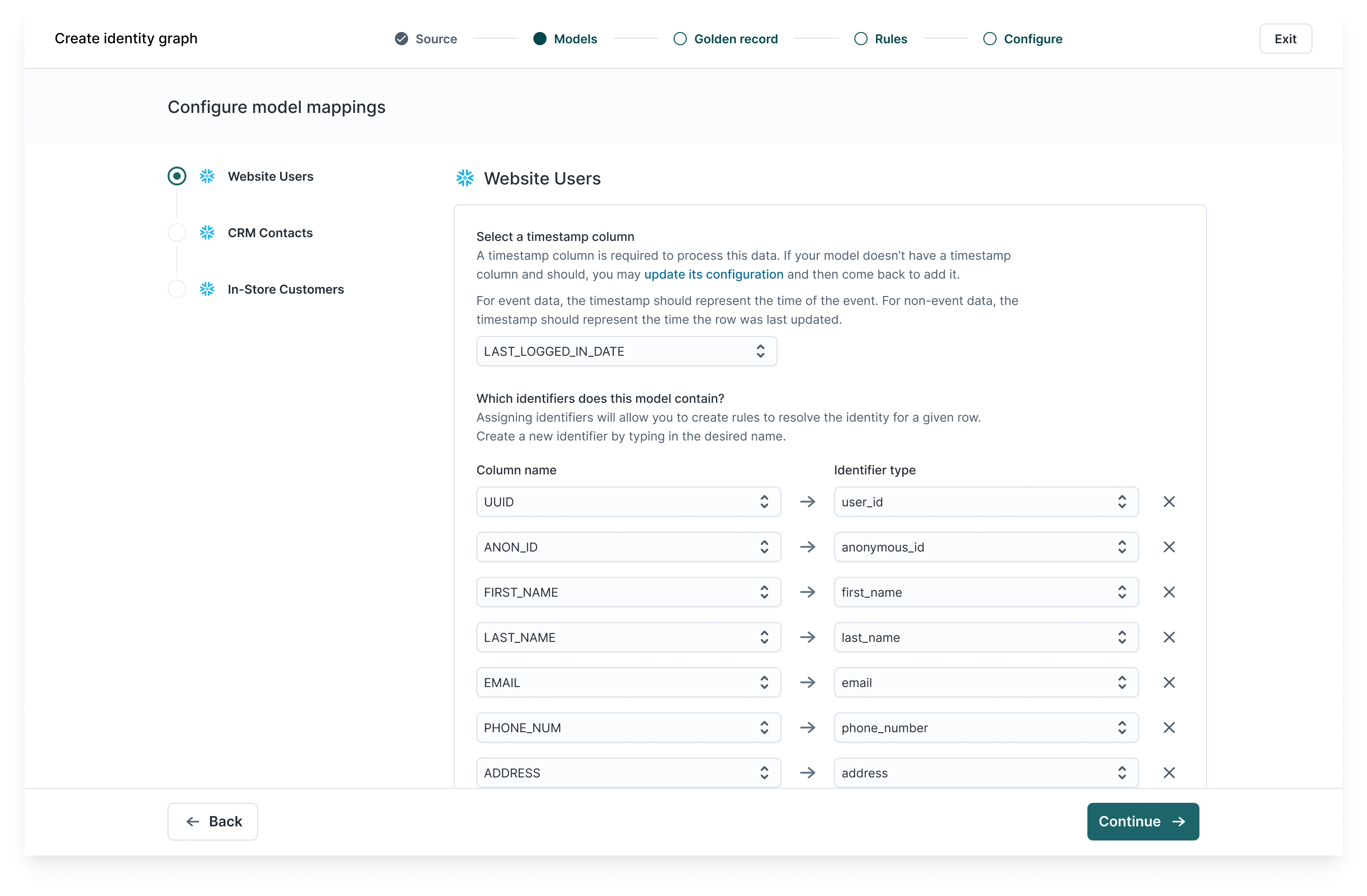
Once you've mapped identifier columns, configure identifier rules to control how each field contributes to matching.
What Are Identifier Rules?
Identifier rules determine how Hightouch uses your mapped identifiers in deterministic and probabilistic matching.
For deterministic matching, you'll define:
-
Priority order: Which identifiers should be used first when evaluating exact matches
-
Limit rules: Optional boundaries to prevent identifiers from over-linking across unrelated people (e.g. shared devices or generic emails)
For probabilistic matching, identifiers are automatically combined into a weighted model that calculates match confidence.
Supported Identifier Types
| Identifier Type | Example Fields | Matching Supported |
|---|---|---|
email, user_email | Deterministic + Probabilistic | |
| Phone | phone_number | Deterministic + Probabilistic |
| Name | first_name, last_name | Probabilistic only |
| Address | street_address, state, city, postal_code | Probabilistic only |
| User ID | user_id, customer_id | Deterministic only |
| Anonymous ID | anonymous_id | Deterministic only |
Tip: Probabilistic matching works best when each record has at least a few identifiers.
- Deterministic only (exact matches, enabled by default)
- Probabilistic Matching (similarity scoring, must toggle on)
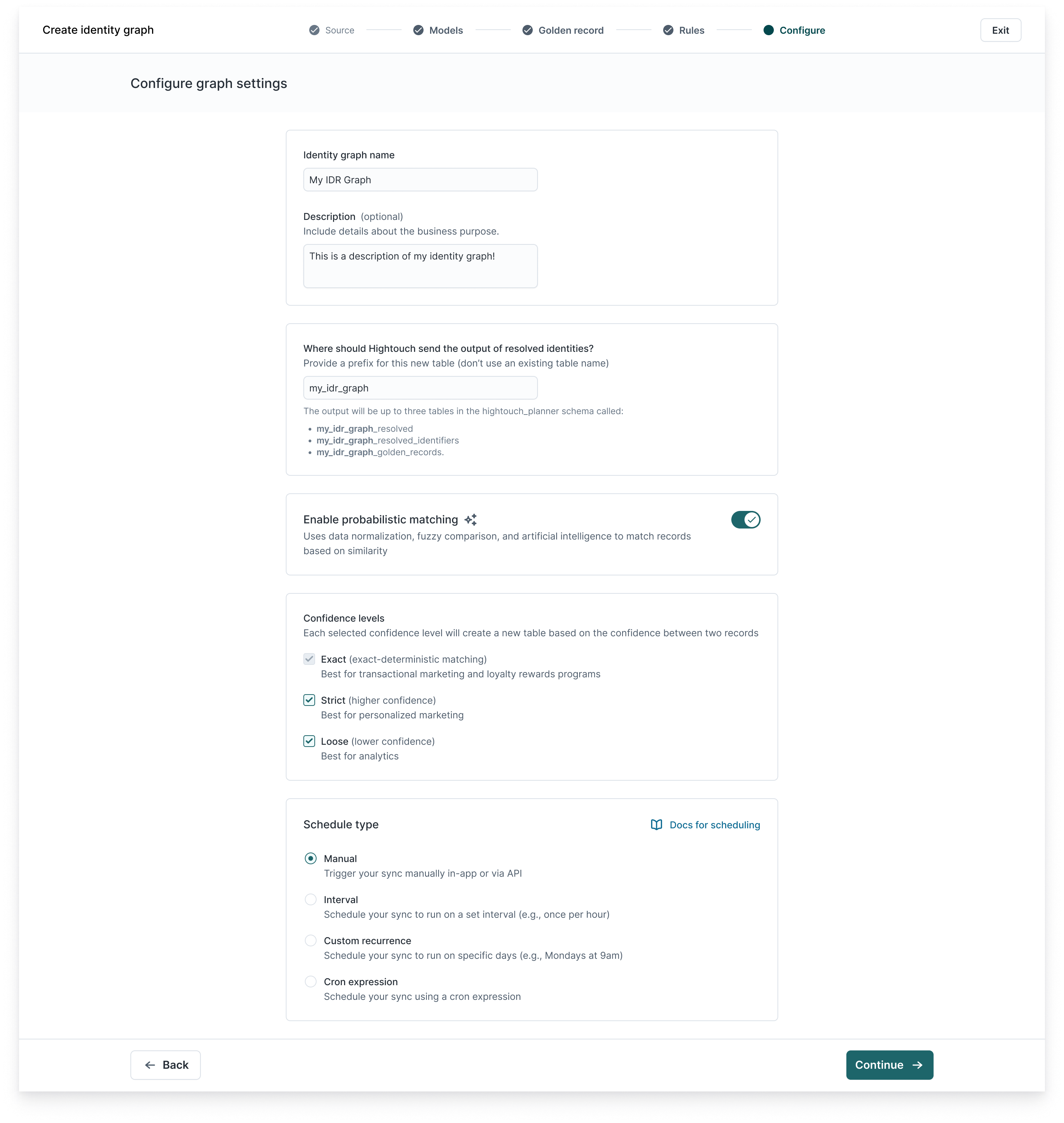
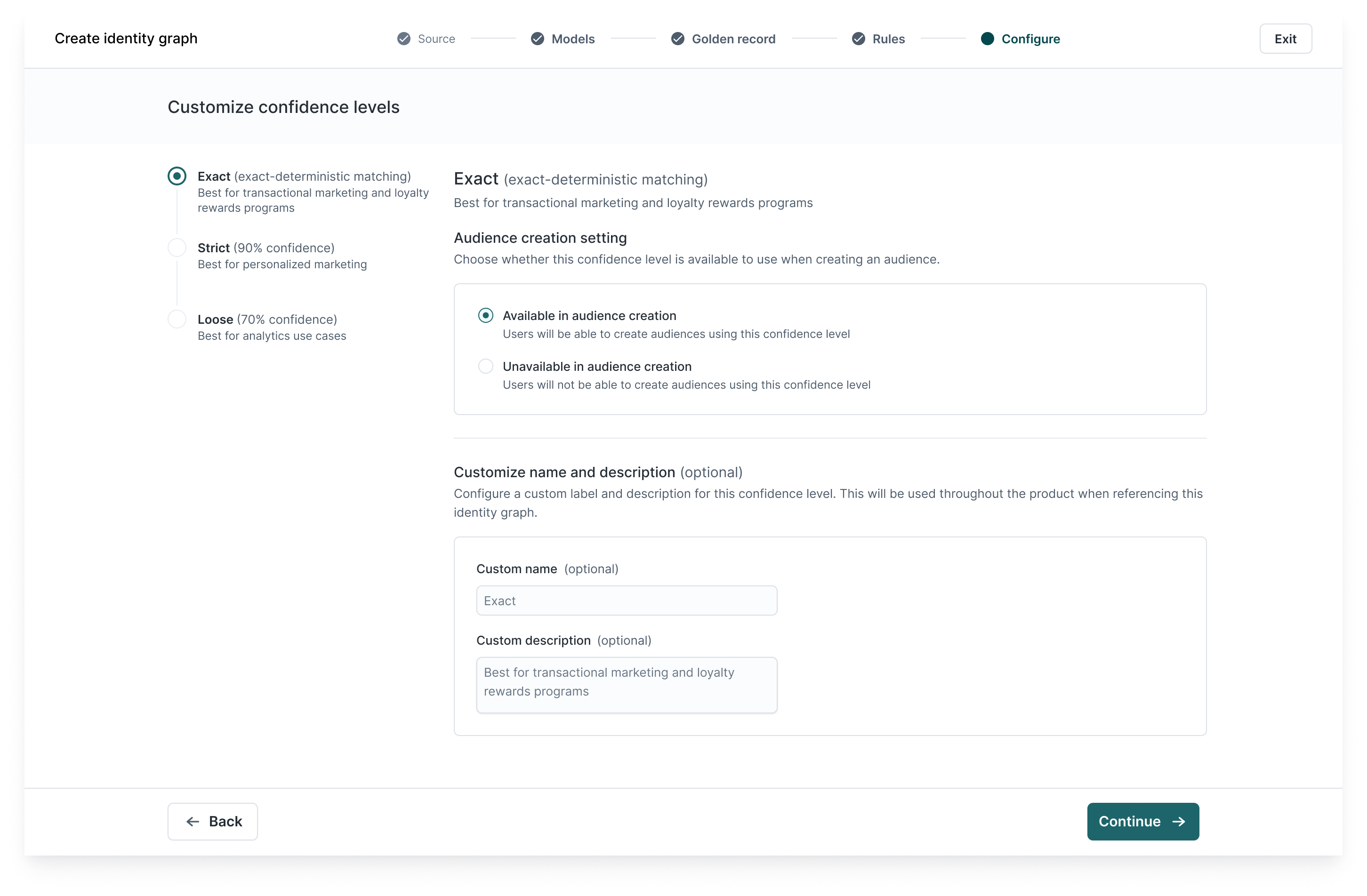
If using probabilistic matching, set your confidence thresholds:
-
Exact: High precision, e.g. for transactional use cases
-
Strict: Balanced precision and recall, e.g. for personalization
-
Loose: High recall, e.g. for analytics
These can be adjusted over time as you monitor match quality.

6. Save and build your graph
Click Save to create your identity graph. Hightouch will generate a unique HT_ID for each resolved profile.
What's next?
Once your data is prepared and your graph is built, you can:
- Define a Golden Record for trusted traits
- Review and QA your matches using Summary and Profiles views
- Build audiences using unified profiles
- Sync identities to downstream tools with confidence-based filters