Sync data from Redshift to Reply.io
Connect your data from Redshift to Reply.io with Hightouch. No APIs, no months-long implementations, and no CSV files. Just your data synced forever.
Activate your data in 3 easy steps


Name
Name
Total_orders
All_orders
Last_login
Last_login
Name
Name
Total_orders
All_orders
Last_login
Last_login
Sync data from Redshift to Reply.io
- Keep your Reply contact lists up to date with the freshest data from your warehouse
- Sync customer and lead data to build out and automate email campaigns with a personal touch at scale
- Create a more unified view of your Reply contacts by incorporating data from other touchpoints
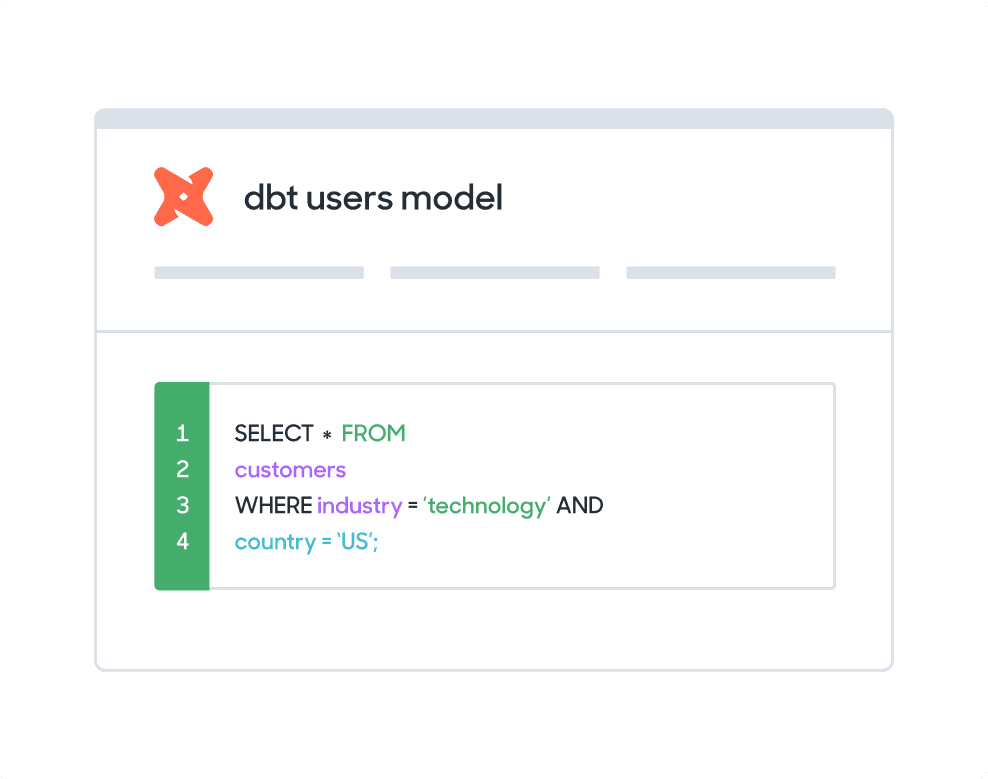
What methods can I use to model my Redshift data?
dbt model selector
Sync directly with your dbt models saved in a git repository.

Looker
Query using Looks. Hightouch turns your look into SQL and will pull from your source.

SQL editor
Create and Edit SQL from your browser. Hightouch supports SQL native to Redshift.
Sigma model
Hightouch converts your Sigma workbook element into a SQL query that runs directly on Redshift.
Table selector
Select available tables and sheets from Redshift and sync using existing views without having to write SQL.

Customer Studio
For less technical users, pass traits and audiences from Redshift using our visual segmentation builder.
FAQs
There are several options to sync data between sources. You can manually build and maintain a data pipeline, use a point-to-point solution such as Zapier, or you can manually upload CSVs.
With Hightouch, you get:
- Automation: You do not need to build and maintain custom data pipelines and you do not have to have your team do manual work
- Simplicity: You avoid a complex web of integrations caused by point-to-point solutions by syncing data from your source
- Speed: You can get set up in quickly - the average Hightouch customer starts syncing data in 23 minutes
- Control: companies of all sizes have access to enterprise-level controls including observability, dbt integrations, and version control
- Security: Hightouch never stores your data and is HIPAA, GDPR, CCPA, and SOC-2 compliant
90% of all Hightouch syncs complete in 30 seconds or less, and the platform enables non-technical users to self-serve.
With Hightouch, you can sync data as frequently as it changes within your Redshift. You can trigger data syncs manually or schedule them to run at an interval or custom recurrence as often as once per minute.
Hightouch offers a basic mapper or advanced mapper that allows you to visually match columns from your Redshift to fields in Reply.io.
Yes, if you integerate Redshift and Reply.io using Hightouch, in-warehouse planning is supported.
Great, but what is in-warehouse planning?
Between every sync, Hightouch notices any and all changes in your data model. This allows you to only send updated results to your destination (in this case Reply.io). With the baseline setup, Hightouch picks out only the rows that need to be synced by querying every row in your data model before diffing using Hightouch’s infrastructure.
The issue here is this can be slow for large models.
Warehouse Planning allows Hightouch to do this diff directly in your warehouse. Read more on how this works here.