Activate your data in 3 easy steps


Sync data from Redshift to HubSpot
- Target customers to upsell based on the product features they currently use
- See a customer's Stripe and NetSuite invoices directly from HubSpot
- Personalize content in marketing emails based on a customer's product usage
- Send lifecycle emails to customers based on their recent activity in the product (like abandoning a shopping cart)
- Send tips to customers on valuable features they haven't used yet
- Congratulate customers for reaching milestones within the product
What HubSpot objects can you sync to?
Contacts
Contacts store information about individuals. From marketing automation to smart content, the lead-specific data found in contact records helps users leverage much of HubSpot's functionality.
Companies
The companies object is a CRM object. You can use individual company records to store information about businesses and organizations within company properties. The companies endpoints allow you to manage this data and sync it between HubSpot and other systems.
Deals
A a deal represents an ongoing transaction that a sales team is pursuing with a contact or company. It’s tracked through pipeline stages until won or lost. The deals endpoints allow you to manage this data and sync it between HubSpot and other systems.
Tickets
In HubSpot, a ticket represents a customer request for help or support. The tickets endpoints allow you to manage this data and sync it between HubSpot and other systems.
Custom Objects
To represent and organize your CRM data based on your business needs, you can create custom objects. Use the custom objects API to define custom objects, properties, and associations to other CRM objects before syncing data from Hightouch.
Events
A marketing event is a CRM object, similar to contacts and companies, that enables you to track and associate marketing events, such as a webinar, with other HubSpot CRM objects. Below, learn more about working with the marketing event API to integrate marketing events into an app.
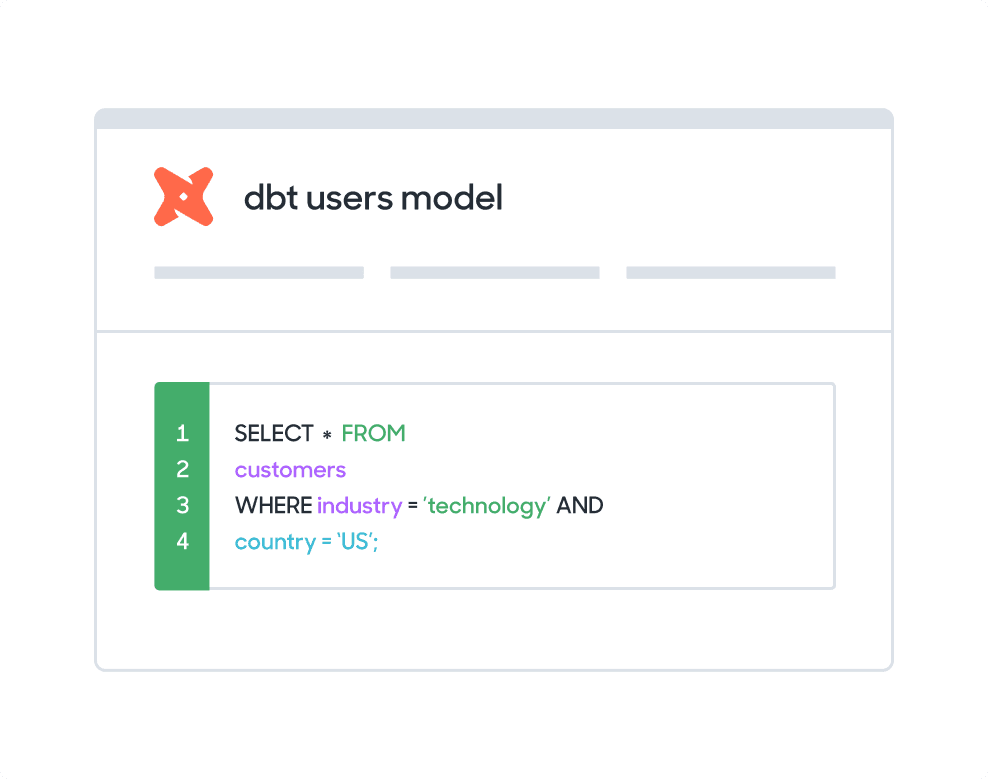
What methods can I use to model my Redshift data?
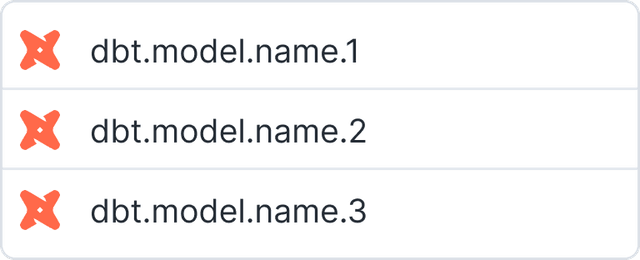
dbt model selector
Sync directly with your dbt models saved in a git repository.

Looker
Query using Looks. Hightouch turns your look into SQL and will pull from your source.

SQL editor
Create and Edit SQL from your browser. Hightouch supports SQL native to Redshift.
Sigma model
Hightouch converts your Sigma workbook element into a SQL query that runs directly on Redshift.
Table selector
Select available tables and sheets from Redshift and sync using existing views without having to write SQL.

Customer Studio
For less technical users, pass traits and audiences from Redshift using our visual segmentation builder.