Sync data from your warehouse to any tool
Get data into more hands throughout your organization. No messy scripts or CSV uploads — just SQL.
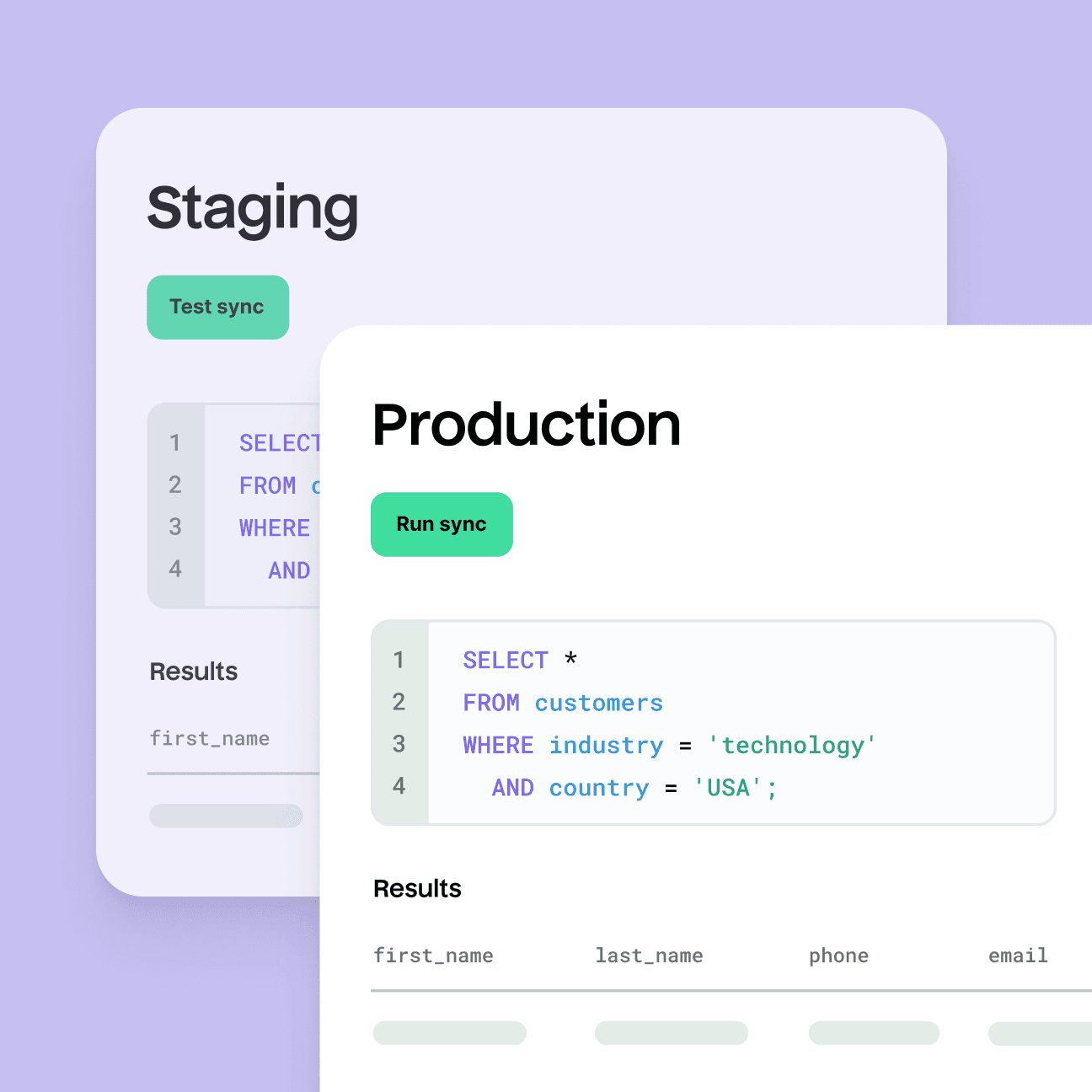
Connect to any data warehouse, lake, or other source. Define the records to sync by selecting a table or writing SQL.
Map fields between your source and destination. Configure syncs in the app or take control via API.
Sync to 300+ destinations in real-time or on a recurring schedule. Spin up new data pipelines in minutes — not weeks.

Connect to any data warehouse, lake, or other source. Define the records to sync by selecting a table or writing SQL.
High performance pipelines out of Snowflake, Databricks, BigQuery, and Redshift

Real-time syncing from the warehouse
Hightouch makes it easy to build low-latency pipelines. Under the hood, the sync engine listens for fresh data using your warehouse's native change data capture (CDC). No architectural puzzles — it just works.
Ultra-fast and efficient batch jobs
Harness the compute horsepower of your warehouse to accelerate batch syncs. Every sync is optimized for speed, whether it's a small incremental update or a massive backfill.
On-demand scalability
Deploy bursty workloads at a moment’s notice. No hidden concurrency limits, ever.
1 Million+daily sync jobs
Unlimited volume
Sync your largest models without breaking a sweat (or breaking the bank).
2 Trillion+rows synced annually
High availability
Keep your production data pipelines flowing 24/7/365.
99.99%global uptime

“Data is now accessible to every stakeholder within the company regardless of their technical abilities.”
Remi Paulin
Data Architect at PrestaShop
Built for modern data teams
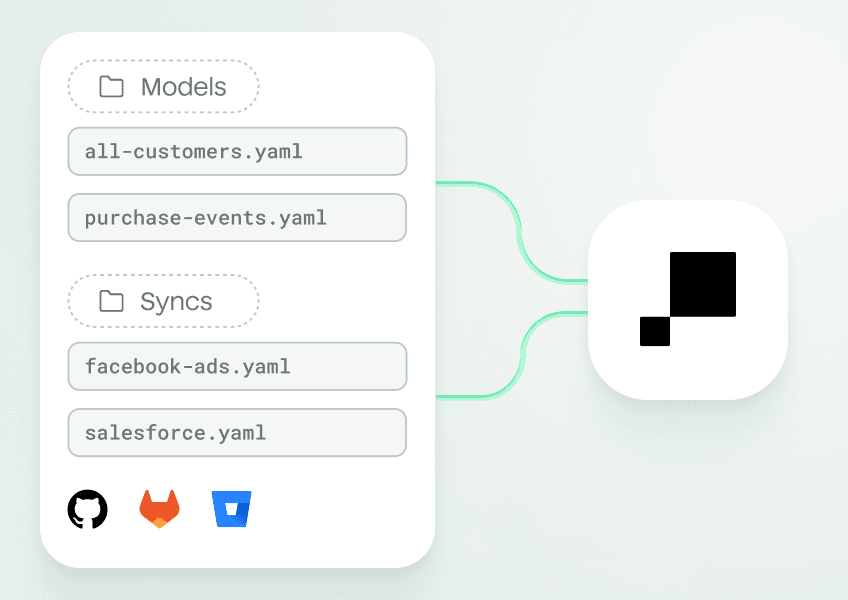
Version control with Git allows you to manage pipelines using YAML files in a repo that syncs bidirectionally with Hightouch.
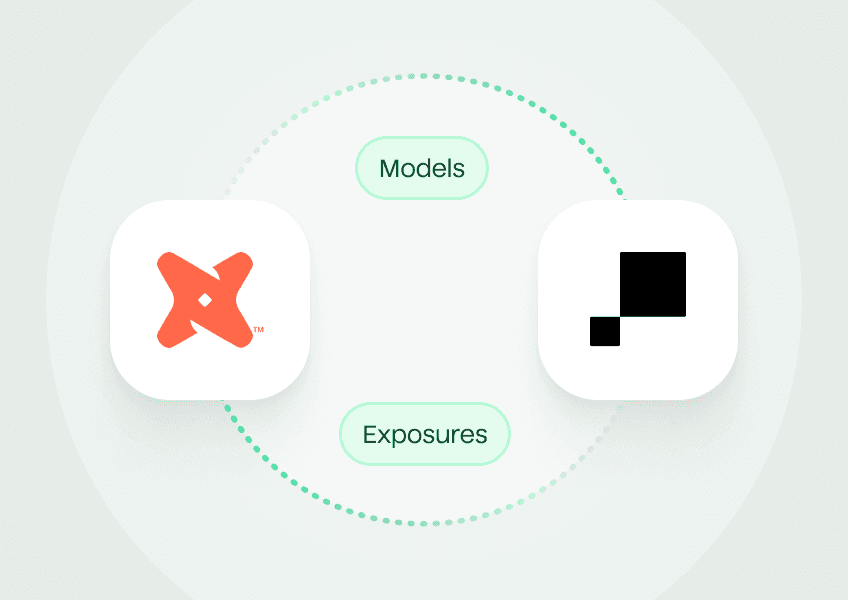
Integrate directly with dbt to import your models, publish exposures back to dbt, and trigger syncs as soon as dbt jobs finish.

Write logs back to the warehouse for auditing or analysis, giving you full control and unlimited retention.
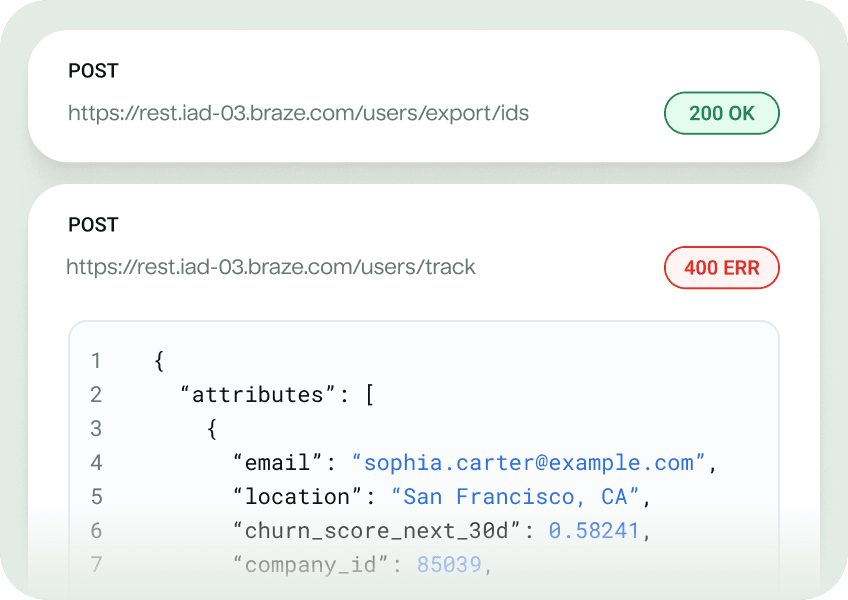
Step into the row-level debugger to trace every operation that occurs during a sync, including API calls for each processed row.
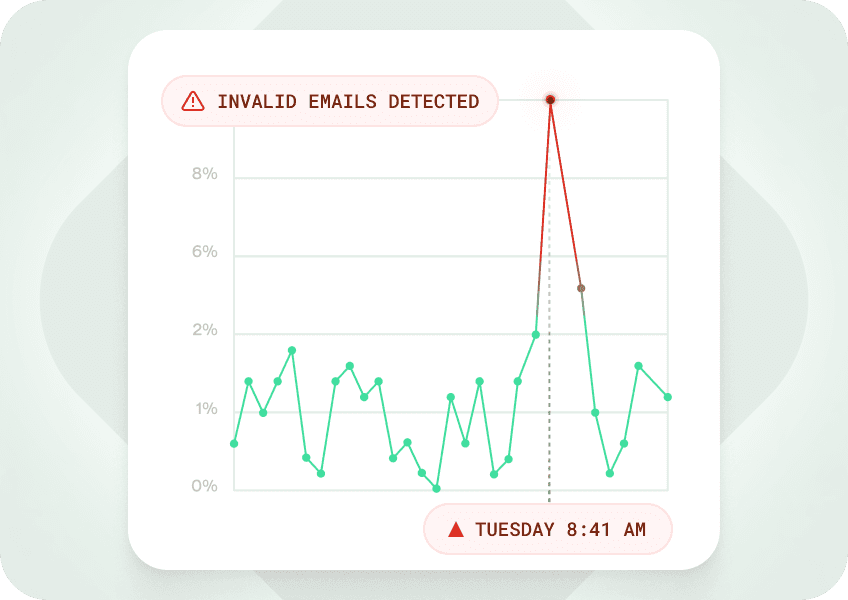
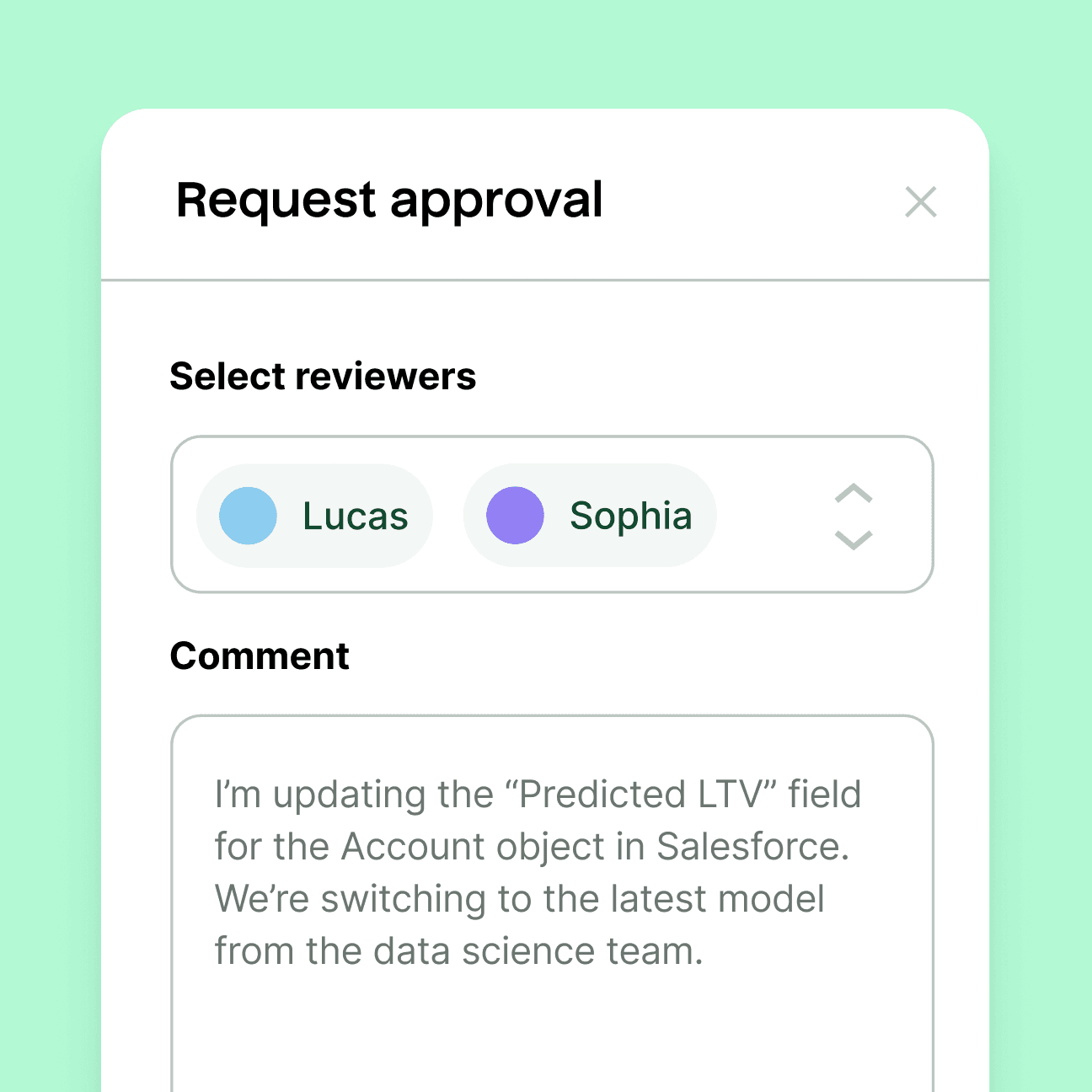
Detect anomalies and proactively receive alerts on sync throughput, data quality, destination errors, and other problems.
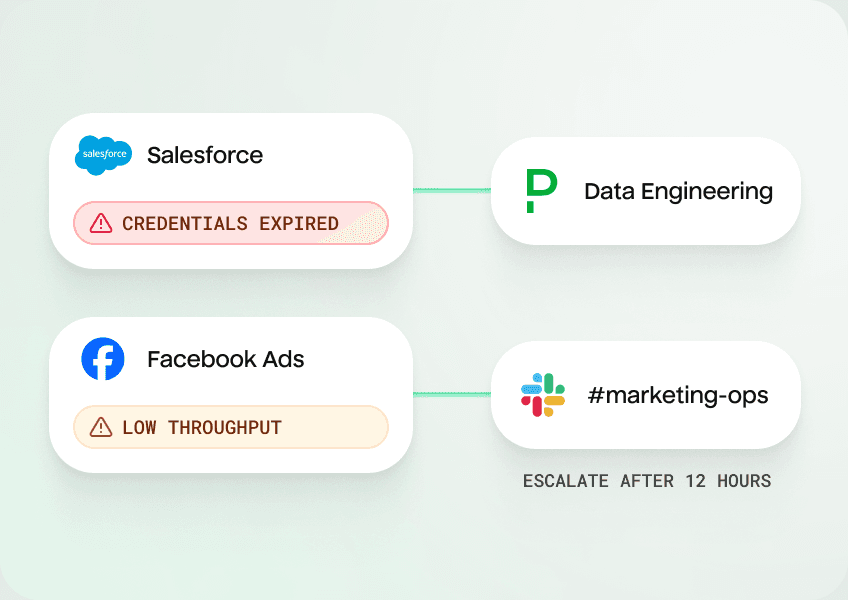
Build escalation flows with custom alerts that loop in stakeholders and help resolve data incidents more quickly.

Connected to your whole data stack
Hightouch integrates with the tools you already use for data observability, lineage, orchestration, business intelligence, ETL, and more.
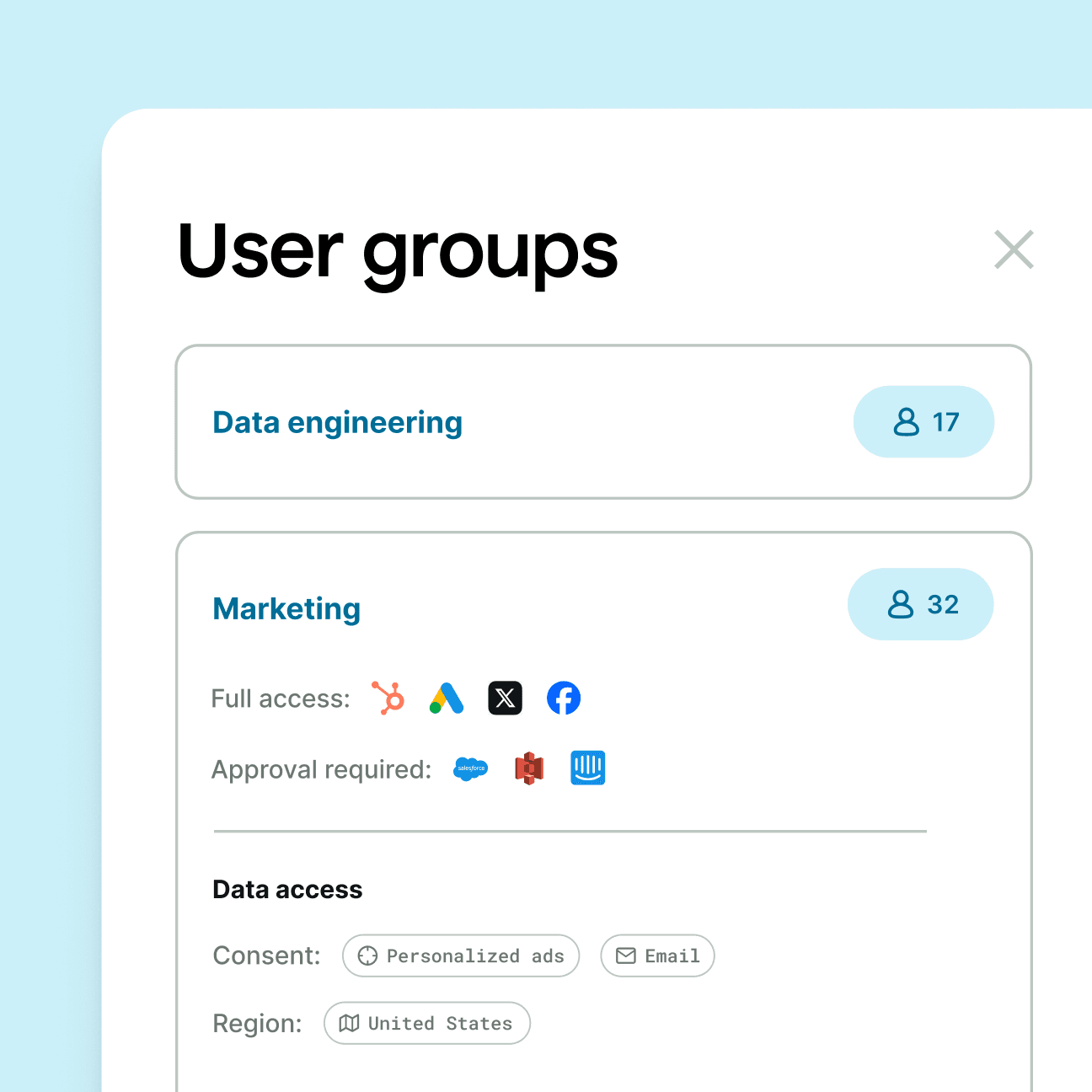
Enterprise-grade governance
Hightouch makes it easy for teams to collaborate across your business, without sacrificing control or compliance.

Secure by design
Hightouch never stores your data
We don’t store a single byte of your customer data (not even logs). Bring your own bucket and keep all storage at rest in your own infrastructure.
Choose your region and cloud
Hightouch syncs are processed by ephemeral workers that live in a cloud of your choice. We support AWS, GCP, and Azure.
Private networking
Connect securely using AWS PrivateLink, GCP Private Service Connect, or Azure Private Link, with SSH tunneling also available for on-prem environments.
Extend the Hightouch platform with developer-friendly tooling
Hightouch is built with extensibility in mind. Data teams can use the REST API for complete, headless control — transforming Hightouch into the backbone for internal tools and embedded apps.
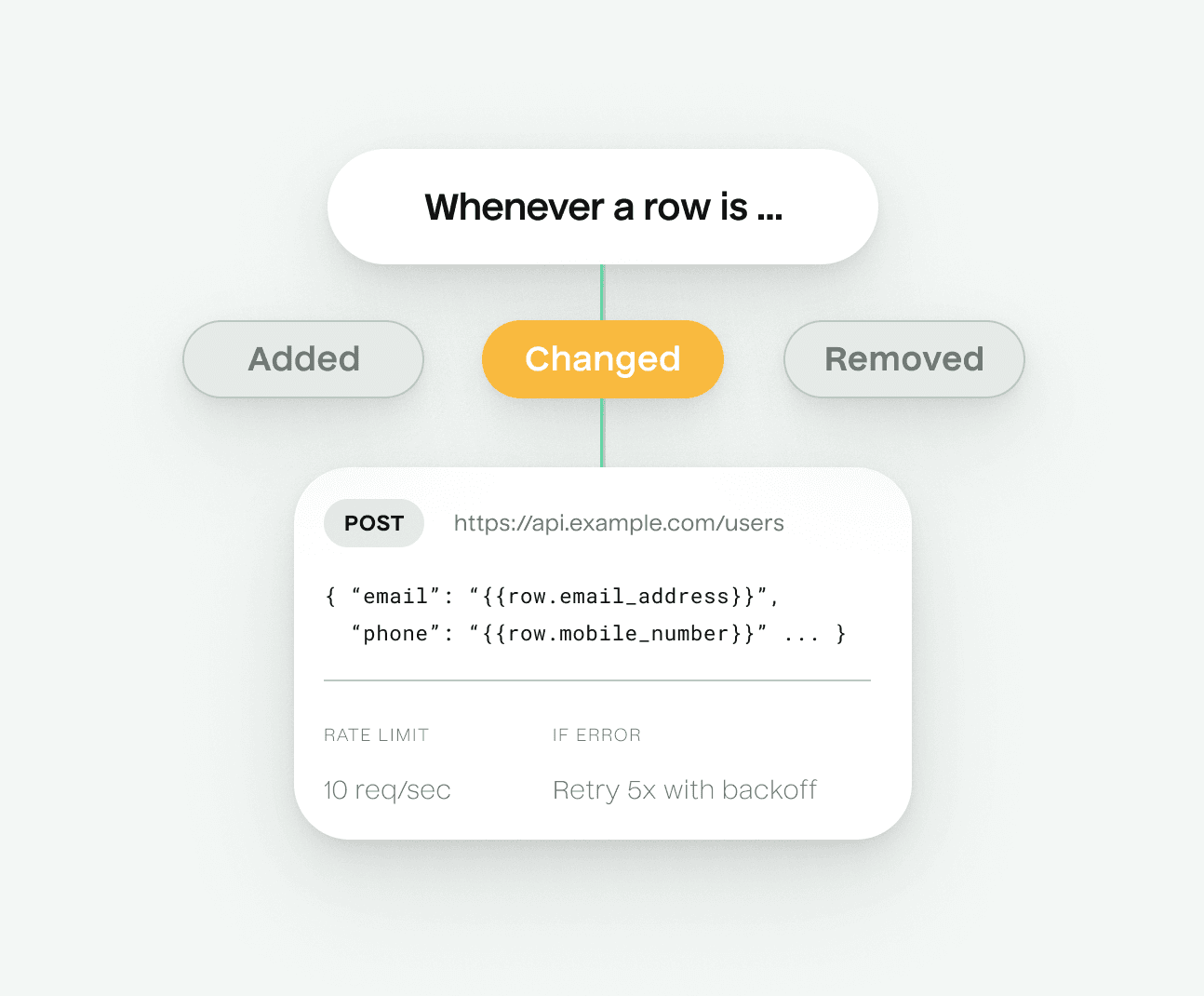
Build your own custom integrations
Connect to any API with granular control over endpoints, payloads, rate limits, error handling, and more. No code required.
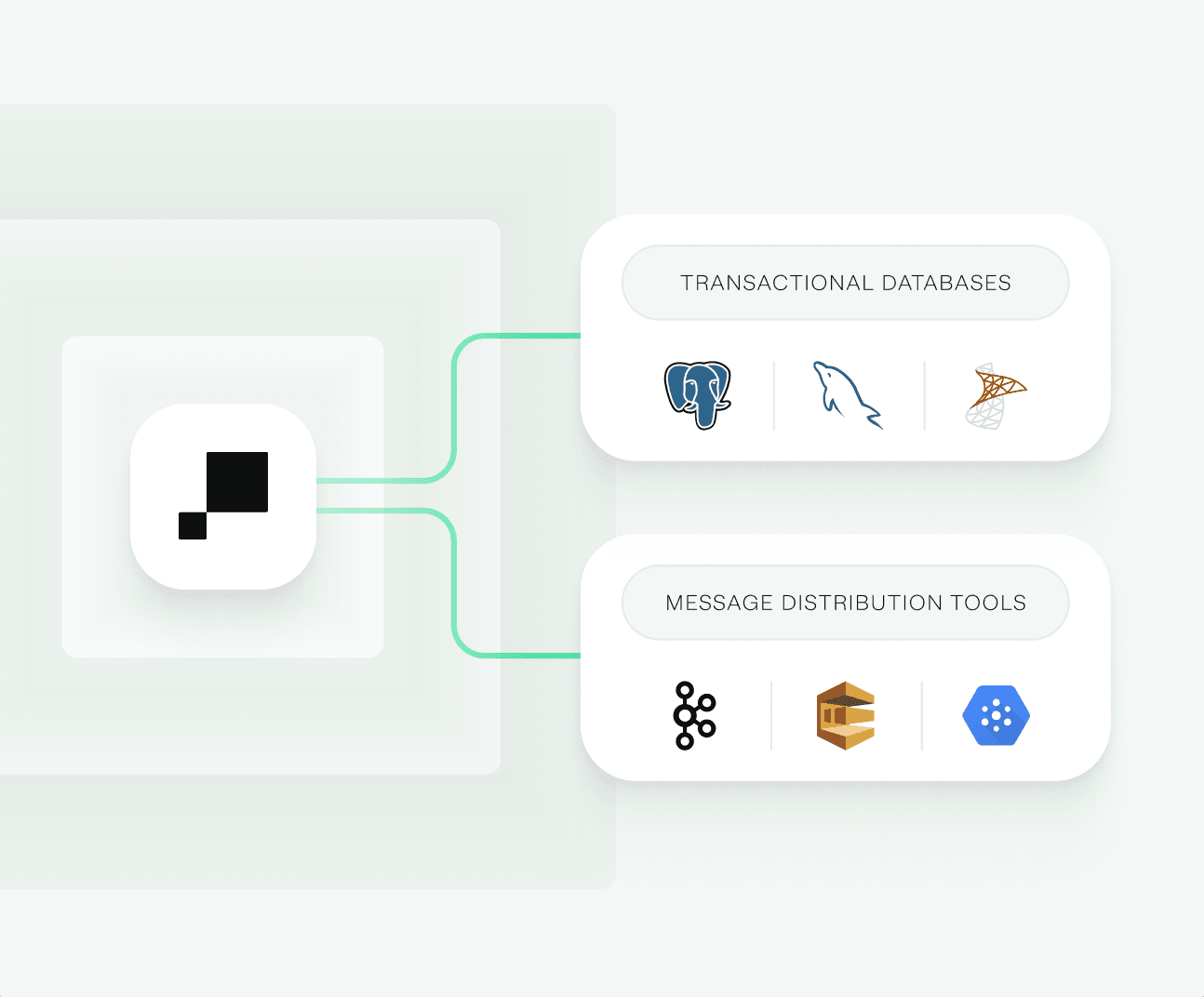
Sync to internal tools and databases
Use Hightouch to update transactional databases or publish messages into queues and streaming platforms.
Write your own functions to enrich, transform, and sync data
Add custom logic to your pipelines by executing functions using AWS Lambda, Google Cloud Functions, or Azure Functions — all hosted in your own infrastructure.
300+ fully-managed connectors
Hightouch helps your data warehouse become the hub that keeps everyone connected across marketing, sales, finance, and more.






")










