Activate your data in 3 easy steps


Sync data from Redshift to Salesforce
- Push lead info from your warehouse into Salesforce CRM to enable executives to go after the right accounts
- Push product data to enable account managers to know what actions are being taken in the app
- Reduce churn by syncing health scores and churn events to Salesforce CRM for account managers to track
What Salesforce objects can you sync to?
Account
Represents an individual account, which is an organization or person involved with your business (such as customers, competitors, and partners). Use the
accountobject to query and manage accounts in your org.Contact
Represents a contact, which is a person associated with an account. Use the
contactobject to manage to manage individual people who are associated with an account.Lead
Represents a prospect or lead. Use the
leadobject to manage leads in your org.Opportunity
Represents an opportunity, which is a sale or pending deal. Use the
opportunityobject to to manage information about a sale or pending deal.Campaign Member
Represents the association between a campaign and either a lead or a contact. Use the
campaignMemberobject to manage campaign members in your org.Task
Represents a business activity such as making a phone call. Use the
taskobject to manage to-do items for your org.Case
Represents a case, which is a customer issue or problem. Use the
caseobject to manage customer cases for your org.Asset
Represents an item of commercial value, such as a product sold by your company or a competitor, that a customer has purchased. Use the
assetobject to manage assets for your org.User
Represents a
userin the organization. Use this object to query information about users and to provision and modify users in your organization. Unlike other objects, the records in the User table represent actual users—not data owned by users.Custom Salesforce Objects
We support custom Salesforce objects to ensure our integration supports all your organization’s unique workstreams.
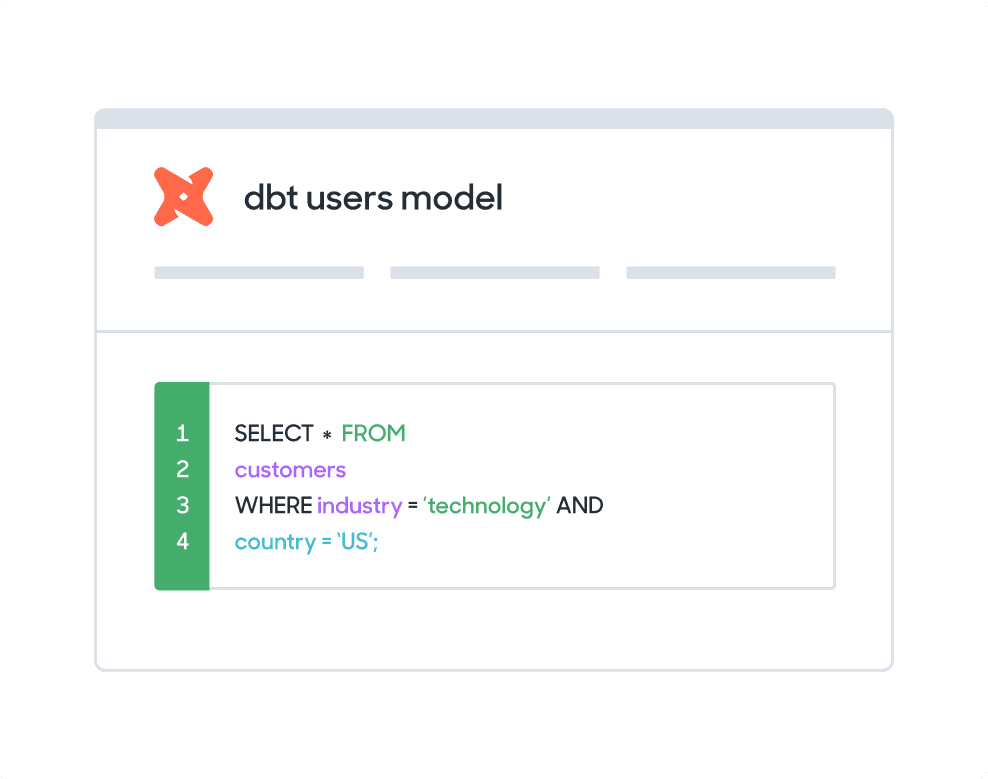
What methods can I use to model my Redshift data?
dbt model selector
Sync directly with your dbt models saved in a git repository.

Looker
Query using Looks. Hightouch turns your look into SQL and will pull from your source.

SQL editor
Create and Edit SQL from your browser. Hightouch supports SQL native to Redshift.
Sigma model
Hightouch converts your Sigma workbook element into a SQL query that runs directly on Redshift.
Table selector
Select available tables and sheets from Redshift and sync using existing views without having to write SQL.

Customer Studio
For less technical users, pass traits and audiences from Redshift using our visual segmentation builder.