
Thanks to the explosion of cloud-based services, there are more SaaS platforms, and software tools than ever before. In fact, in 2021 it was estimated that the average organization had around 110 SaaS apps.
If you’re reading this post, you’re probably in a similar boat, trying to figure out how you can send data from one tool to another. In this post, we’ll cover everything you need to know about API integrations – including API types, authentication, reading, writing, deployment, monitoring, and scheduling. We’ll also tell you how you can start integrating with third-party APIs.
What is an API?
Chances are you’re already familiar with APIs, but for the uninitiated, API stands for Application Programming Interface. At its core, an API is an interface that enables different applications, systems, and SaaS tools to interact with one another via a connected system. Today, basically every platform offers an API to automate repetitive processes so you can build better customer experiences.
However, the key factor to understand about APIs is that they let you seamlessly share data between applications to automate business processes. APIs handle communications with other separate applications and process requests from external clients. There are two parts to an API: the server and the client. The server houses the resources or information and the client accesses it. APIs establish a set of rules that define how the client and the server can talk to one another to perform specified tasks.
The Types of APIs
There are really only 3 API frameworks, REST (representational State Transfer), SOAP (Simple Object Access Protocol), and RPC (Remote Procedural Call).
REST APIs
REST APIs specialize in transferring data from a server to a client. There’s a distinct separation between the two because the client generates a request and the server generates a response. All valid requests and responses must follow HTTP protocol and responses are formatted in JSON to ensure compatibility.
The interactions between the two are stateless and the server never stores data from the client request. REST APIs are designed so that neither the client nor the server can tell whether it’s communicating with the end application, or rather with another intermediary layer like an API gateway or a load balancer. As a rule of thumb, all REST APIs have a layered architecture to ensure the client and the server go through several intermediary layers in the communication loop. REST APIs also make resources cacheable to improve performance.
SOAP APIs
SOAP APIs are focused on highly secure internal data transfers. The SOAP framework has been around since the 1990s and it defines how messages should be sent and what resources should be included in them. They’re more secure than REST APIs, but also much more code-intensive and difficult to implement. All SOAP APIs use XML to encode information. The main advantage of SOAP APIs is that they work over any communication protocol, not just HTTP.
RPC APIs
RPC APIs use both JSON and XML protocols and they’re used to execute scripts on a server. They’re mainly used for internal systems and remote services/networks. Whereas the previous two API frameworks focus on transferring data, RPC APIs invoke processes and actions.
What is an API Integration?
Every API is somewhat different, and in order to use one, you first need an API integration so you can connect your applications together. An API is basically a doorway, and an API integration is a hallway that connects that doorway to other doorways. API integrations power processes throughout your business and keep your data in sync so you can empower your business users. However, integrating with APIs either requires you to adopt an off-the-shelf solution, or to hire a software developer to write custom scripts for every SaaS tool or system in your data stack. This can be very challenging because there are so many factors you have to consider.
Understanding the API Interface
The first step in integrating with any third-party API and building a custom integration app is having a deep understanding of the API endpoints. This is sometimes easier said than done. A good place to start is the available documentation from the third-party application. In the best-case scenario, there will be plenty of examples of clearly-documented endpoints and return values, fully explained rate limits, and authentication that’s easy to implement. In the worst-case scenario, a lot of this will be trial and error as you kludge along on your journey to understand how the API works.
You’ll want to set up a dummy account and have some test data ready so that you can start API testing (reading from and writing to the integration.) Most applications have a trial account which should be enough to get started, but some will require a paid subscription or even a discussion with a sales rep before you can get going.
API integration tools like Postman or Insomnia can help you catalog the endpoints you’ll be using and make authentication simpler by storing cookies and headers. Capturing the API requests and responses up-front will make the development process much easier after you get started.
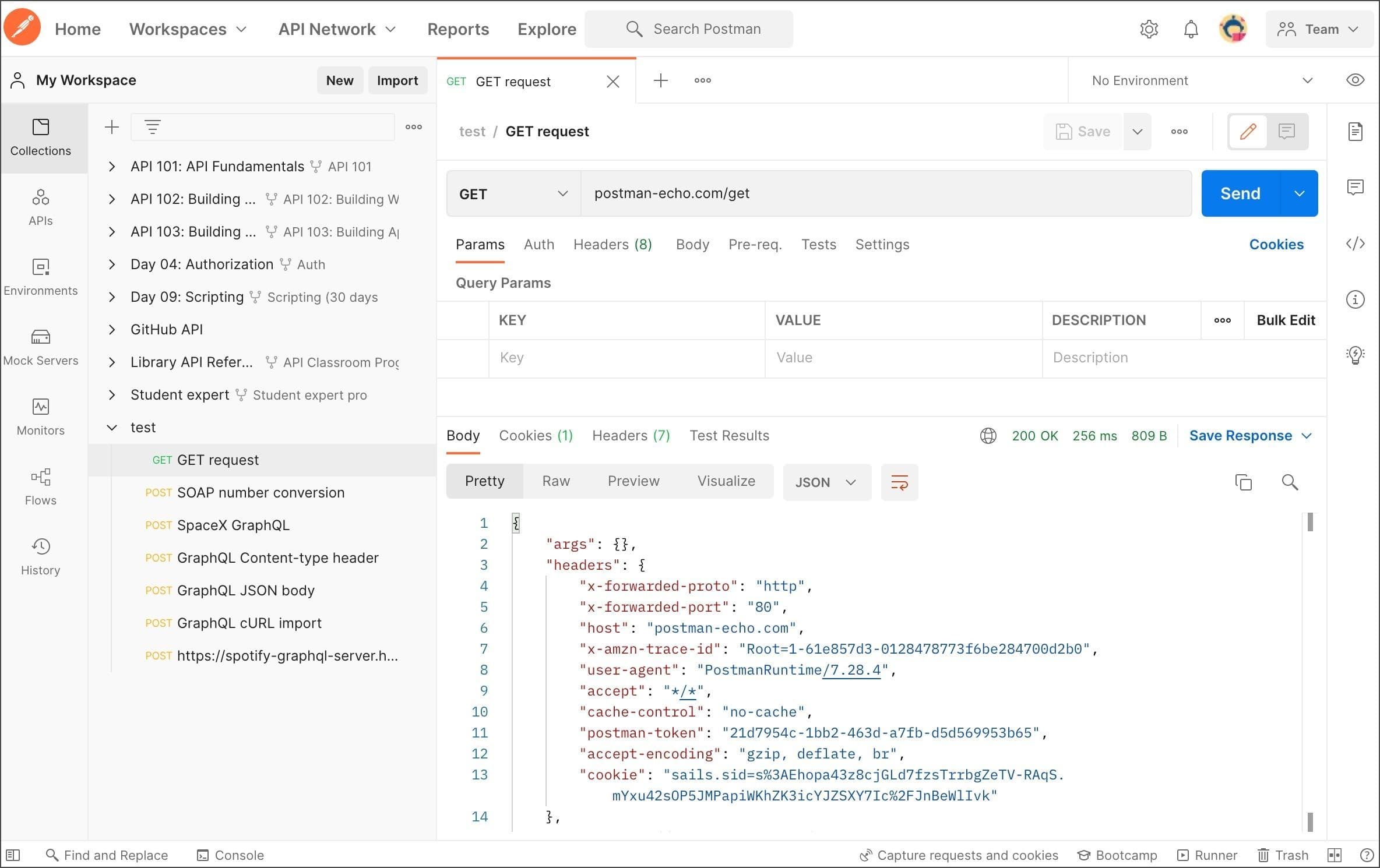
Postman UI
Authenticating the API
Once you’ve gained a basic understanding of the API, you’ll immediately want to find out how authentication to the API works. Some APIs may work with a simple API token, such as a Bearer Token provided in the header.
Other applications may have more complex automated workflows. Providing access grants using OAuth may grant particular permissions to specific resources. These may return tokens that are only valid for a set time and will need to be refreshed periodically.
It’s best practice to read secrets from the environment, rather than hard-coding them into the application configuration. To aid in development, consider having multiple accounts, one for development and one for production usage.
In more complex applications, you may wish to allow the user to set their own tokens, as these can change frequently, and some security policies may require you to regularly change access tokens. For example, Hightouch supports both tokens and OAuth authentication depending on the destination. For HubSpot, both methods are supported, as seen below.
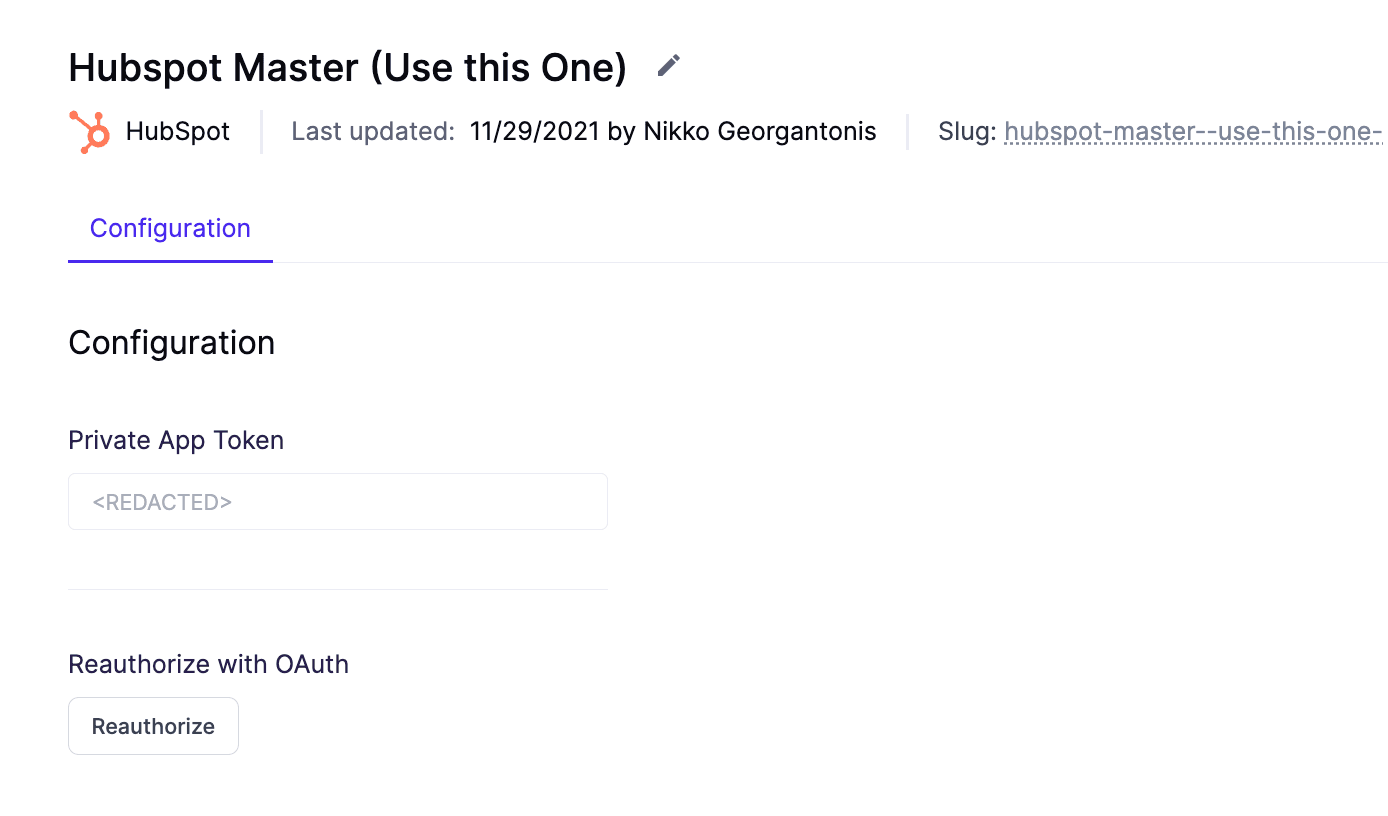
Hubspot API Configuration
Reading From and Writing to the API
Most APIs tend to follow a REST-like interface, where data resources can be fetched using an HTTP GET request, while information can be updated using POST, PATCH, and PUT methods. When updating data, JSON is a common format used for sending data.
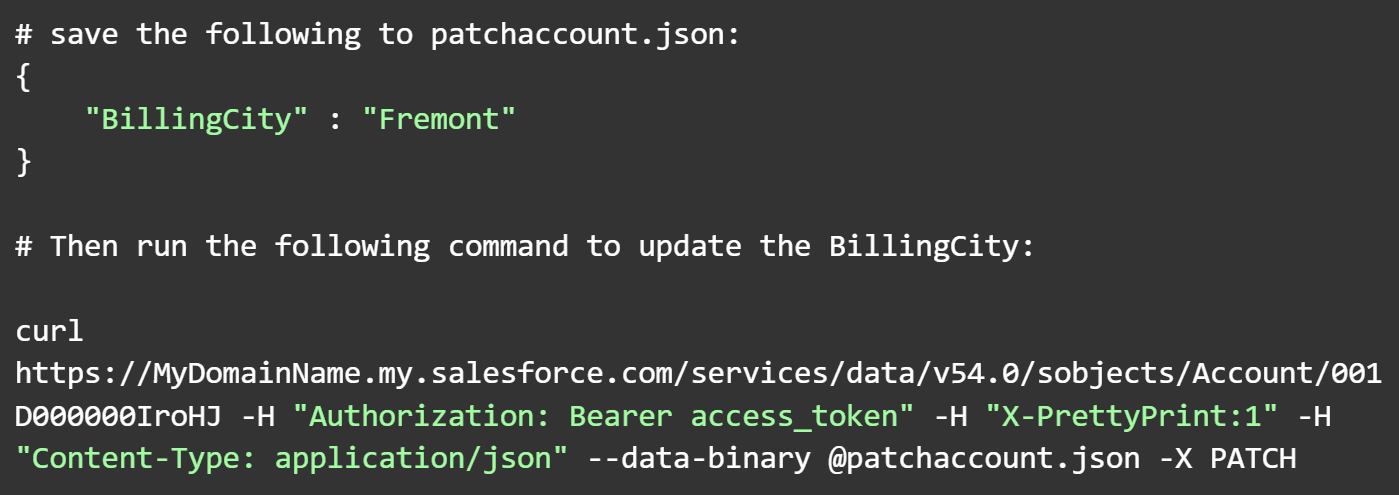
REST API Interface Using JSON
Depending on the development language, you may have to resort to using HTTP requests to fetch and send data. Many APIs will paginate data for you in order to avoid very large payloads. For these, you’ll often get a URL or a page number as part of the response, but sometimes you may have to iterate through the pages until nothing is returned.
In some cases, you’ll have client libraries available for your application. Python and Java are very common, but JavaScript is also available sometimes. For the largest applications, there may be client libraries in a number of other languages, but for many smaller APIs, you’ll have to resort to writing your own custom library.
Querying Source Data
You’ll likely have internal data you will want to write to a third-party system. One important question is how you will query that data. There are many different models. You could rely on an event-based system that responds to particular actions in your application; and if a user registers for your application, you could fire a UserCreated event, which is processed by your integration service and used to write the new user to the third-party system.
Event-based models are simple to implement but can be difficult to reason about. If a user changes their name or email, you will need a way to capture that change and ensure the downstream systems are kept up to date. If the data changes outside of the application itself, during a data migration or a backfill, then you will quickly see the weakness of event-based systems.
Another option is to query the data directly from the database or data store. In a database, you could rely on change-data-capture to get a feed of events directly from the database and monitor for relevant changes in order to write those back to the third-party application. Another option is a batch job that queries the data using a query language like SQL, and then writes the entire contents back to the application. More complex systems could keep a history of what was written previously, so that only new or changed rows are sent to the third-party application, reducing the number of API calls required.
Fetching Destination Data
In some cases, you will need to fetch data before you can write to it. Perhaps in your source data you have a person on your team who owns the relationship to a particular contact. However, your third-party system doesn’t allow you to assign ownership of contact by name or email, but only by an internal ID. You would first need to query the list of owners from the third-party system, fetch the ID by matching on email, then use that ID to write the contact back to the system with the owner.
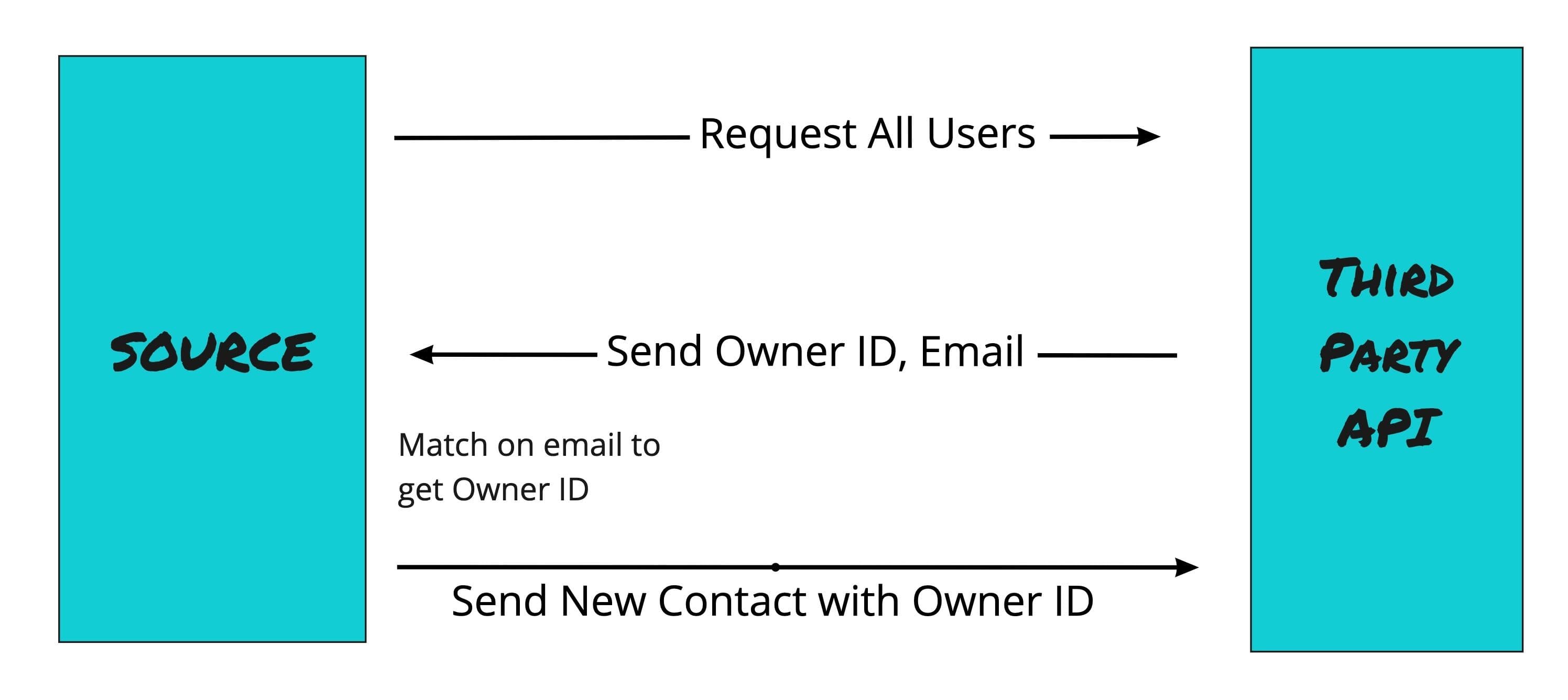
Third-Party API Architecture
Relationships are often tricky to get right, and it’s important to not make assumptions about the quality of the data coming in. You might think emails are unique, but that may not be the case, so matching on them needs to be done carefully.
Mapping Fields
In order to write data from a source to a destination, you’ll need some type of mapping between the name of the fields in the source and the names in the destination. You may have a field called user_email in your source database, but in the destination, that field may be named ContactEmail. For one or two fields, it can be tempting to hard-code these – but consider making field mappings configurable as it’s likely that your business needs will evolve and more data will be required for the integrations in the future. Being able to avoid a code change every time a field changes can help reduce the time it takes to respond to business needs. Dynamic field mapping can make it easy to avoid spelling mistakes that can result in corrupted data.
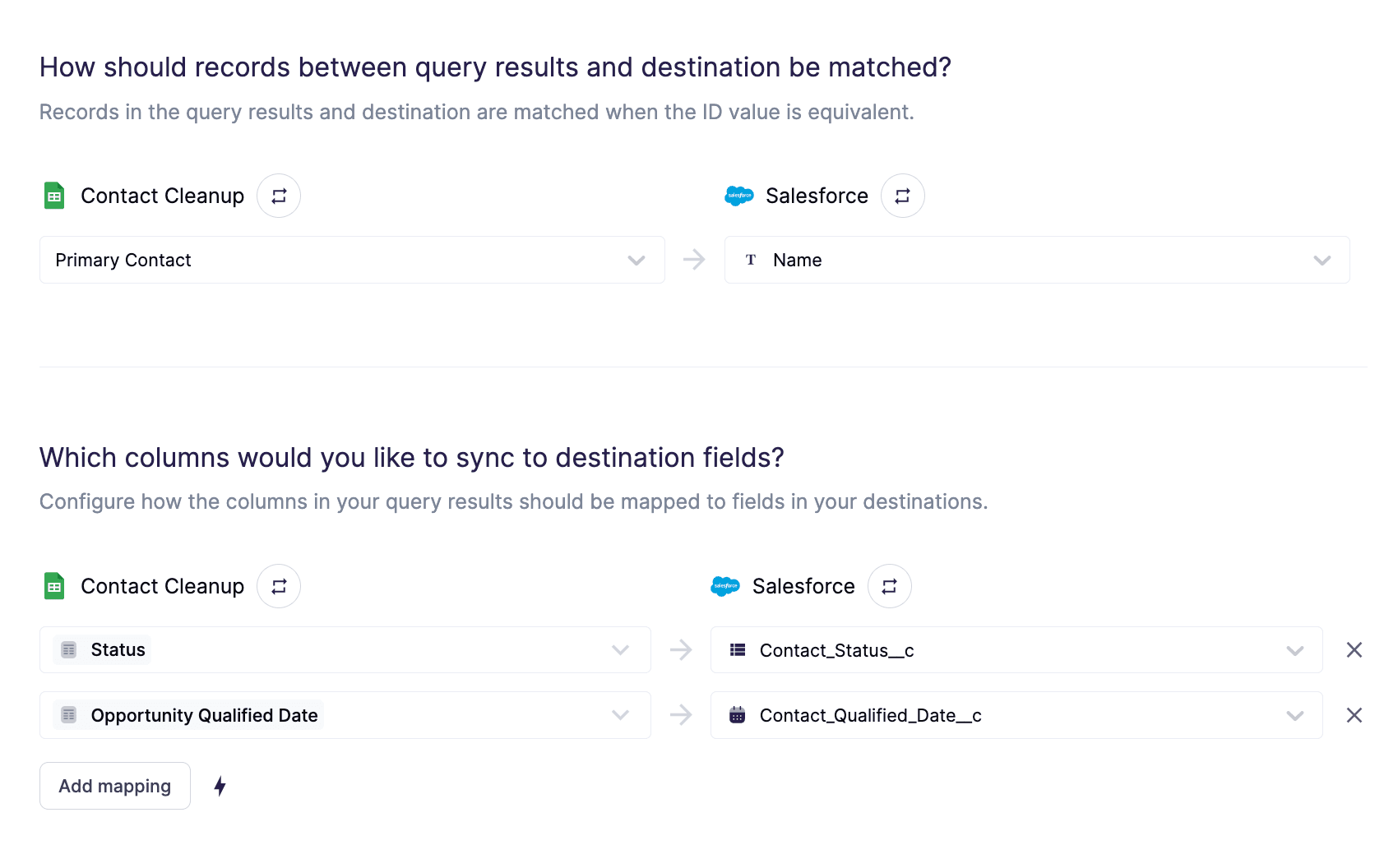
Hightouch Sync to Salesforce
In the Hightouch application, there are drop-down fields for both the source and target. Field metadata is fetched from both applications and the user is provided with a drop-down selector for mapping between systems. As an additional bonus, the Automapper will suggest mappings based on fields that share a common name, reducing further the manual input required from the user.
Rate Limits, Batching, and Parallelizing
Many APIs often have rate limits that limit the number of calls you can make to a given endpoint. These rate limits often encourage the use of a Batch API over event-based ones, especially for larger workloads. It can be difficult to get rate limits right, as your application may respond more slowly in development than it does in production.
One way to control rate limits is to utilize batches of a fixed size. The larger the batches, the fewer the calls you will have to make. Take care though because a large batch may result in an error as well, as some APIs also limit the size of data you can send in a single request. Being able to tune the batch size can be helpful as you experiment to find the right balance.
You’ll often (but not always, because that would be too easy) receive a 429 HTTP status code, which represents too many requests. Usually, the header will include a Retry-After, which is a good way of knowing how long to pause before trying a request again. In absence of that, you may want to simply retry with an exponential back-off, hoping that the application request eventually works if you wait long enough. Tuning the back-off and the maximum number of retries is also largely experimental and will depend on the particular destination you are writing to.
For some systems, you may benefit from increased throughput by parallelizing requests. Some APIs don’t have rate limits that would affect your data writes but may be slow enough that parallelizing requests would improve throughput. Breaking your data out into batches and sending multiple batches out at once to the same endpoint can help improve the overall time it takes to write the data to the end systems.
Handling Errors
There are many possible errors that could occur when writing to third-party systems. Network issues could mean that either the system never got your request, or did get it but never responded successfully. If your systems are idempotent, then retrying is a perfectly valid solution, but if not, then careful thought needs to be taken into how requests are retried for errors.
Often errors will come from the third-party API itself. Some will use HTTP status codes to indicate particular errors, while others (like GraphQL) may return a successful status but have error details in the response itself. If the documentation for the third-party system is well-written, these errors will be explained in detail and you’ll be able to create logic for handling it. If not, then it may be worth sending bad data and invalid requests to see how errors are handled by the system. It’s better to find out upfront than when it really matters.
Errors may occur for the entire request, or on a row level. For example, Salesforce may return errors for a batch of requests where some rows failed but others succeeded. Exposing row-level errors can be useful for users to debug issues, or to know when errors can be safely ignored.
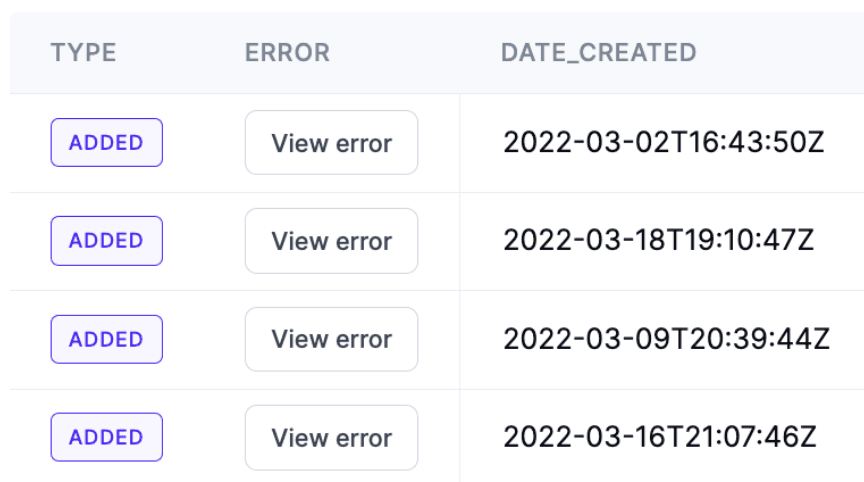
Hightouch Sync Errors
Classifying errors is difficult but can be really helpful. Some errors can be solved by a simple retry, but others are more fatal. Being able to expose relevant errors back to the users of your systems can help with the debugging process and can give your users more observability into the system. Perhaps a permission change is causing errors in your application, and the business user simply needs to enable a new permission set. Exposing that error in your application in a friendly way to the user can help them solve issues without escalating to the engineering team.
Logging your progress
Good logging is one of those things that you don’t realize you need until it is too late. Having a good system for logging requests and responses can help your users better debug potential issues. If data is missing from a destination system, being able to search the logs for the primary key to see if the request was ever made and if it was successful can help narrow down where the failure occurred.
Logging also can help your users understand the progress of active syncs, especially for long-running syncs. Capturing the timestamp of when the various steps of the integration occurred can also help with timing and profiling integrations to better understand how long integration runs take. Monitoring these can help identify potential issues before they turn into larger problems.
Deploying integrations
Once you’ve finished developing your integration service, the next step is to find a way to deploy it. There are many different designs here, and some of these will depend on how you built your application.
For event-based integrations, lambdas are a good starting point, as they’ll respond quickly to single events before terminating. You can configure most cloud lambdas to read from a message bus or queue, making it easy to scale up to meet demand and scale down when there’s no load.
For batch-processing, you may wish to leverage orchestration tools like Airflow, Dagster, and Prefect. These can be scheduled to run at an hourly or daily cadence and can also capture application output for logging, with built-in capabilities for retrying on failures.
If your needs are more complex, you may want to consider deploying an entire application, which can benefit from containerization. As your needs evolve, you may wish to have more fine-grained control over scheduling and orchestration, but be mindful that even a basic scheduler is hard to implement correctly. Consider, for example, what happens if the time it takes your application to run is longer than the interval between schedules, or if have a requirement to backfill data following a fix. These can be tricky to get right, and often it’s better to use a solution that has these edge cases already accounted for.
Monitoring integrations
Being able to monitor the progress of your integrations is critical to ensure that they’re operating as expected. Outside of having access to logs, you may wish to expose metrics on the integrations themselves. Some high-level metrics that could be useful are the total rows queried in the source, the total operations performed on the destination, and the time it took for the query and writes to complete. You may also wish to break down this data by type of operation, for example, adding a row versus updating an existing one.
Deciding how to expose these metrics is case-dependent. Some teams use tools like Datadog to monitor their infrastructure. By writing these metrics to a Datadog instance, you can quickly create summary dashboards and even monitors to alert when certain thresholds are exceeded.
Alerting is also an important feature to consider. If a system goes down but requires someone to actively monitor that it’s working, then it’s easy to miss an outage. Being able to alert when an integration fails, or when a threshold of rows does not write properly, is critical for ensuring the health of your pipeline. Slack and other instant messaging platforms are often used for alerting, but sometimes tools like PagerDuty are also useful.
Some integrations are more business-critical than others, so the ability to configure alerting by integration can be important to avoid notification fatigue.
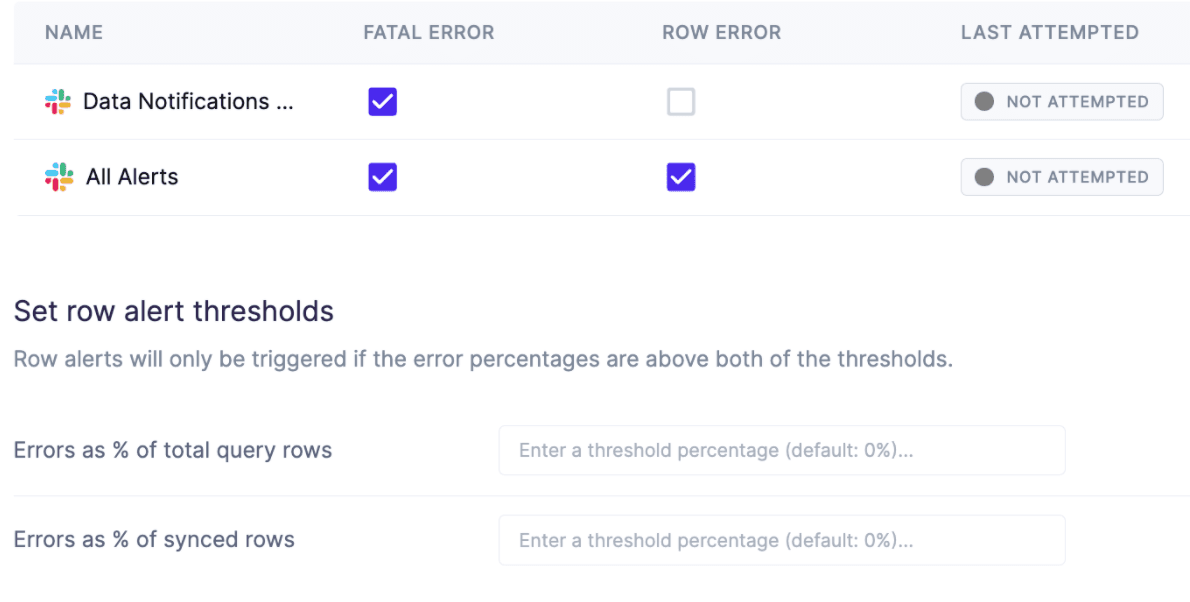
Hightouch Alerting
Wrapping Up
As you can see, building third-party integrations might appear simple at first, but the hidden complexity behind moving data between systems means there are many concerns and trade-offs to consider.
In today’s marketplace, third-party APIs are ubiquitous, and as your company grows and becomes more sophisticated, the demands for your data teams to integrate with third-party applications will continue to scale.
If you’d like to take a deeper look into this topic, check out: The Data Engineers Guide to 3rd Party APIs to learn more about the core challenges with third-party APIs, the three concerns with data systems, architectural patterns for data ingestion, and why you should build on top of a data warehouse.
If you’d like to use a platform that takes care of these concerns so you can focus exclusively on delivering value from your data, then sign-up for a free account at hightouch.com
















