
What Is Data Ingestion?
Data ingestion is an essential step of any modern data stack. At its core data ingestion is the process of moving data from various data sources to an end destination where it can be stored for analytics purposes. This data can come in multiple different formats and be generated from various external sources (ex: website data, app data, databases, SaaS tools, etc.)
Why Is Data Ingestion Important?
The data ingestion process is important because it moves data from point A to B. Without a data ingestion pipeline, data is locked in the source it originated in and this isn’t actionable. The easiest way to understand data ingestion is to think of it as a pipeline. In the same way that oil is transported from the well to the refinery, data is transported from the source to the analytics platform. Data ingestion is important because it gives business teams the ability to extract value from data that would otherwise be inaccessible.
What Is Data Ingestion Used For?
The end goal of the ingestion layer is to power analytics. In most scenarios, data ingestion is used to move data from disparate sources into a specific data platform, whether that be a data warehouse like Snowflake, a data lake, or even a data lakehouse like Databricks. Once the data is consolidated into these cloud platforms data engineers try to decipher it by building robust data models to power Business Intelligence (BI) dashboards and reports so key stakeholders can use this information to drive business outcomes.
Types of Data Ingestion
In general, there are only two types of data ingestion methods, real-time and batch-based.
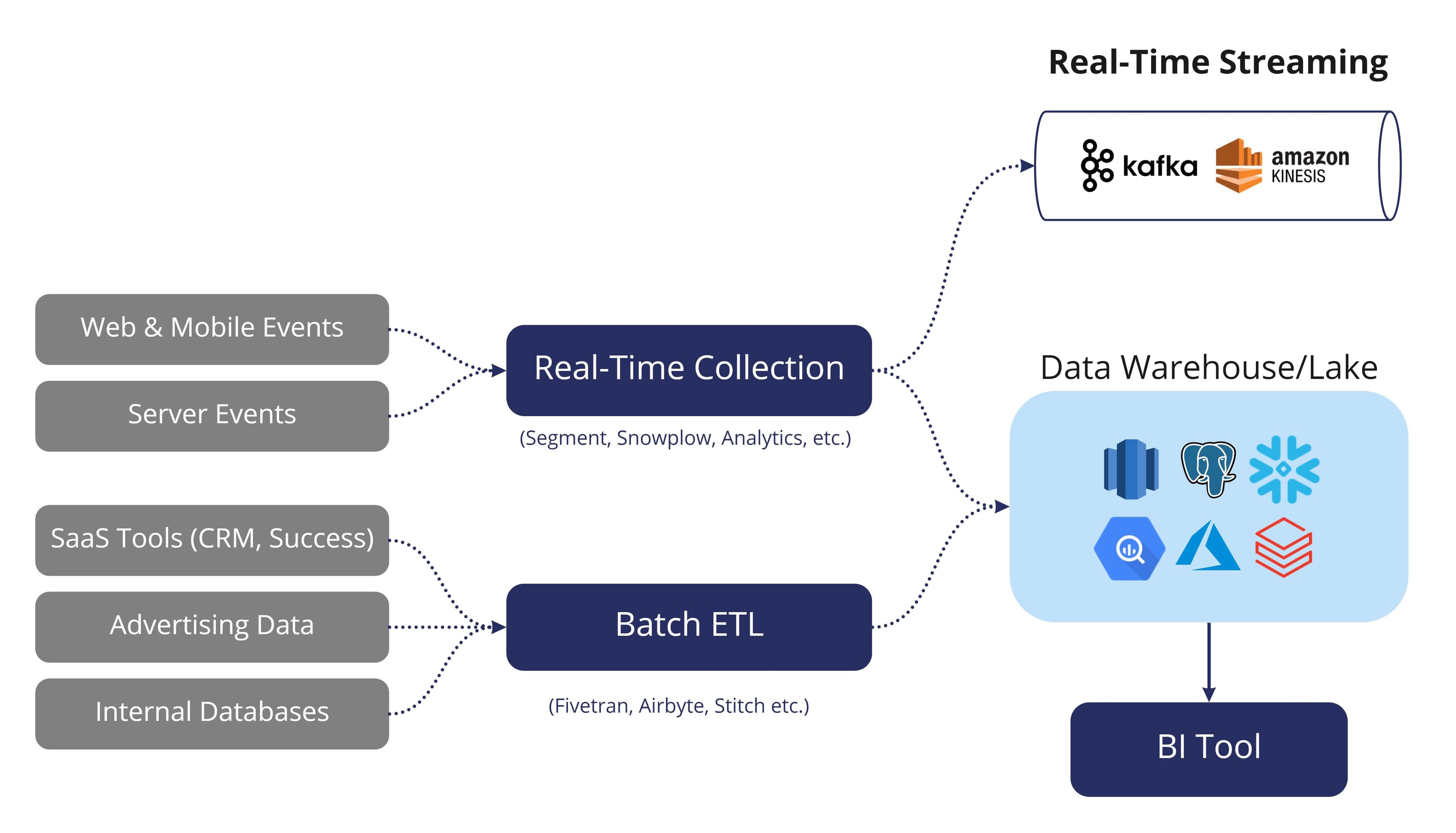
Real-time processing focuses on collecting data as soon as it has been generated and creating a continuous output stream. Real-time ingestion is extremely important for time-sensitive use cases where new information is vital for decision-making. As an example, large oil companies like Exxon Mobil and Chevron need to monitor their equipment to ensure that their machines are not drilling into rocks, so they generate large amounts of IoT (Internet of Things) data. On the same note, large financial institutions like CapitalOne, Discover, Coinbase, BankofAmerica, etc. need to be able to identify fraudulent actions. These are just two use case examples, but both of them rely heavily on real-time data ingestion.
Batch processing focuses on bulk ingestion at a later point (i.e. loading large quantities of data at a scheduled interval or after a specific triggered event.) This method of data ingestion is largely beneficial when data is not needed in real-time. It’s also much cheaper and more efficient when it comes to processing large amounts of data collected over a set period of time.
In many scenarios, companies choose to leverage a combination of both batch and real-time data ingestion to ensure that data is constantly available at low latency. In general, real-time should be used as sparingly as possible because it is much more complex and expensive compared to batch-based processing. Every company has a slightly different standard as to what “real-time data” actually is. For some, it’s every ten seconds, for others, it's every five or ten minutes. However, real-time data ingestion is really only ever needed for sub-minute use cases. For anything equal to or greater than five minutes, batch-based data ingestion should work just fine.
Data Ingestion Processes
The core definition of data ingestion is relatively narrow as it only refers to moving data from one system to another, so it’s better to understand data ingestion through the overarching lens of data integration. Instead of solely being focused on moving data from one system to another, data integration focuses on combining data from external systems into a centralized view for analytics. However, before this can be achieved data needs to be extracted, loaded, and transformed. For ingestion technology, there are two core processes are used to tackle this problem, ETL and ELT.
ETL (extract, transform, load) is an older method of data ingestion. There are three components to all ETL solutions. Extraction focuses on aggregating the data once it has been generated. Transformations are used to manipulate the data into a consistent and usable format that can be leveraged for analysis. Loading refers to the process of ingesting the data directly into an analytics platform or database.
ELT is similar to ETL, but it stands for extract, load, and transform. The process is nearly identical, but the core difference lies in the fact that the data is ingested in its raw and unchanged format. The data is then transformed in the analytics layer before it is used for analysis. This method of data ingestion has become the standard for all modern data stacks because it is faster and cheaper than conventional ETL. In addition to this, it establishes the analytics layer (i.e. the cloud data warehouse) as the single source of truth for all data and business logic.
Challenges With Data Ingestion
Depending on an organization's business requirements and the total number of distinct data sources, handling data ingestion in-house might make sense. However, as data volume increases this is nearly impossible to maintain especially since the average organization has well over 100 SaaS applications today. Building a homegrown custom data pipeline poses several ingestion challenges because it’s time-consuming and resource-intensive to build. Fivetran actually provides a really good estimation for the cost of building a data pipeline in their Data Integration Guide.
Aside from the expense, data ingestion pipelines also require companies to integrate with third-party APIs which poses several more challenges. To make matters worse, data engineering teams constantly have to check for upstream or downstream changes because APIs are constantly changing. With the ever-changing data ecosystem, this is quite difficult as it’s nearly impossible to future-proof anything.
In addition to this, companies have to worry about data privacy and data protection regulations like GDPR and HIPAA. Security is also a major concern and robust measures have to be implemented to fend off outside attacks trying to steal sensitive data. Even if all of this is taken care of, engineers still have to decide how the data will be formatted, whether that be structured, semi-structured, or unstructured. The frequency at which data is loaded, and the volume at which data is loaded is also a concern.
Data Ingestion Tools
Most if not all of the challenges discussed above can be avoided with an actual data ingestion tool. Dedicated ingestion tools address the problems discussed by automating the manual processes involved with building and maintaining data pipelines. Today there are a wide range of ELT solutions and ETL tools available on the market, whether it be a cloud-native offering like Azure Data Factory, an ETL tool like Informatica, or a dedicated SaaS tool like Fivetran, Airbyte, or Stitch for ELT.
When it comes to real-time data ingestion, tools like Apache Kafka, Amazon Kinesis, and Snowplow tend to dominate the market because they are specifically designed to tackle real-time streaming workloads.
How to Get Started With Data Ingestion
The easiest way to get started with data ingestion is to implement a consistent end-to-end flow between data acquisition, data integration, and data analytics. There are a ton of products available in the market today that all claim to fulfill a different part of the modern data stack, but Fivetran is definitely the best data ingestion tool available. As a SaaS-based ELT solution, Fivetran offers fully managed data connectors to numerous source systems and SaaS applications, automatically handling everything behind the scenes so organizations can focus on driving business outcomes.
It is important to note that Fivetran does not offer any transformation abilities, its core competencies lie in extracting and loading data, so a transformation tool is needed to format the data into a usable state. This is exactly where dbt (data build tool) comes into play; dbt is a data transformation and data modeling tool that runs on top of the data warehouse and it’s often considered the standard for simple and complex transformations. For real-time streaming data, Snowplow is a great option. Snowplow is a behavioral data platform that makes it really easy to collect and ingest events into the warehouse.
For the modern enterprise, a typical data stack usually looks something like this:
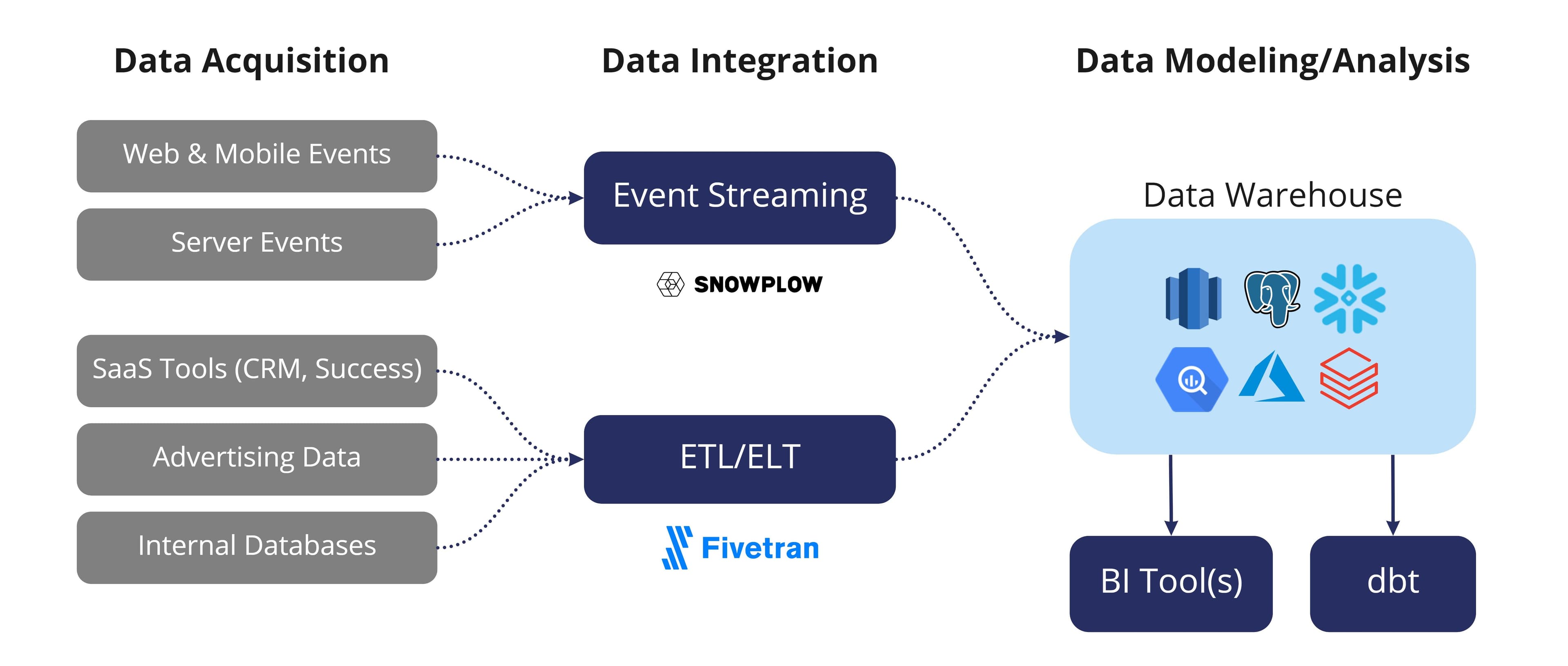
Fivetran and Snowplow are used to collect and ingest data into a data platform and dbt is used to transform and model that data for analysis. This transformed data is then pushed into reporting tools and BI dashboards for analysis so business stakeholders can leverage it to make high-level decisions.
What Comes After Data Ingestion?
Data ingestion focuses solely on moving data into the analytics environment to power advanced analytics use cases. There’s a problem though, all of this information is only accessible to technical users who know how to write SQL, and it’s not actionable in a dashboard/report. Usually, this information includes things like LTV, ARR, product qualified leads, shopping cart abandonment, subscription type, items in cart, session length, last login date, messages sent, etc.
Democratizing this data and making it accessible to business teams like Marketing, Sales, and Support is challenging, but it’s important because these teams are the frontline between customers.
- Sales teams want to know which leads to prioritize
- Marketing teams want to build custom audiences for ad platforms
- Support teams need to know which tickets are the highest priority
Unfortunately, conventional ELT tools like Fivetran only read from the source and write to the warehouse, so moving information out of the analytics layer can be quite challenging because it requires engineers to build an entirely new data pipeline or custom integration.
Thanks to Reverse ETL, there is finally an easier solution. Reverse ETL is similar to ETL and ELT, but it's a functionally very different process altogether because it reads from the warehouse and writes to external sources.
This article gives a great breakdown of the technical differences between Reverse ETL and ELT.
Reverse ETL focuses on activating the data within the data warehouse by syncing it back into the tools of business users and this is the exact problem Hightouch solves. Hightouch runs on top of the data warehouse without ever storing any data. With Hightouch it's easy to use SQL or existing models to sync data to any destination. Users simply have to define the data and map it to the appropriate columns/fields in the end destination. Better yet, the first integration with Hightouch is completely free.
To learn more about Reverse ETL, download the Complete Guide to Reverse ETL today!

















