
One of the great things about the Modern Data Stack is the interoperability with all the different components that make up the stack, but the unfortunate truth is that orchestration is still a tricky problem. Data pipelines still involve custom scripts and logic that don’t fit perfectly into the ETL workflow. Whether it’s custom internal services, or something as simple as downloading a file, unzipping it, and reading its contents, there’s still a need for orchestration tools.
While the Modern Data Stack does provide a lot of flexibility with the various components that play well with each other, being able to orchestrate workflows across the stack still isn’t a solved problem.
Enter Orchestration tools like Apache Airflow, Prefect, and Dagster. These tools are commonly used by data and marketing operations teams to keep workflows running smoothly across the modern data stack. Apache Airflow, the oldest of the three, is a battle-tested and reliable solution that was born out of Airbnb and created by Maxime Beauchemin. Back then, data engineering was a different world, largely focused on regularly scheduled batch jobs that often involved ugly systems with words like Hive and Druid. You still see a lot of this heritage in Airflow today.
Prefect and Dagster are newer products and are both supported by their cloud offerings, Prefect Cloud and Dagster Cloud. Prefect Cloud is free to start and hosts a scheduler while the hybrid architecture allows you to run your tasks locally or on your infrastructure. Dagster Cloud has just been released and is under early access!
What Is Airflow and What Are Its Top Alternatives?
Airflow is a workflow orchestration tool used for orchestrating distributed applications. It works by scheduling jobs across different servers or nodes using DAGs (Directed Acyclic Graph). Apache Airflow provides a rich user interface that makes it easy to visualize the flow of data through the pipeline. You can also monitor the progress of each task and view logs.
If you’ve ever been confused by how dates work in Airflow, you’ll have seen some of that heritage. It’s rare that someone new to Airflow doesn’t get confused by what an execution date is and why their DAG isn’t running when they expect it to. All of this bred from the days of running daily jobs sometime after midnight.
Airflow today is now an Apache project, and it’s adoption by the Apache Foundation has cemented the projects status as the status-quo open-source orchestration and scheduling tool. Today, thousands of companies use Airflow to manage their data pipelines and you’d be hard-pressed to find a major company that doesn’t have a little Airflow in their stack somewhere. Companies like Astronomer and AWS even provide managed Airflow as a Service, so that the infrastructure around deploying and maintaining an instance is no longer a concern for engineering teams.
With that said, with the changing landscape of data, Airflow often starts to come up against a few hurdles when it comes to testing, non-scheduled workflows, parameterization, data transfer, and storage abstraction.
The Benefits of Airflow
Before we dig into some of those pitfalls, it’s important to mention some of the benefits of Airflow: Without a doubt, a project that has been around for over a decade, has the support of the Apache Foundation, is entirely open-source, and used by thousands of companies is a project worth considering. In many ways, going with Airflow is the safest option out there, that community support and proven usefulness makes it such a safe choice that you might even argue that no one’s ever been fired for choosing Airflow (probably).
There are 2 orders of magnitude more questions on Stack Overflow for Airflow, for example, than any of the other competitors. Odds are if you’re having a problem, you’re not alone, and someone else has hopefully found a solution. There are also Airflow Providers for nearly any tool you can think of, making it easy to create pipelines with your existing data tools.
The Problems with Airflow
As the data landscape continued to evolve, data teams were doing much more with their tools. They were building out complex workflows to support advanced marketing automation, personalization, and AI-driven customer engagement use cases, connecting customer data from various systems to power personalized marketing experiences and real-time decision making, and orchestrating workflows that power marketing platforms and customer-facing tools across multiple data systems. For a while, Airflow was the only real orchestration tool available, and so many teams tried to squeeze their increasingly complex demands into Airflow, often hitting a brick wall.
The main issues we’ve seen with Airflow deployments fall into one of several categories:
- local development, testing, and storage abstractions
- one-off and irregularly scheduled tasks
- the movement of data between tasks
- dynamic and parameterized workflows
We’ll dive into each one of these issues by exploring how two alternative tools, Dagster and Prefect address these.
A Look at Dagster and Prefect
Dagster is a relatively young project, started back in April of 2018 by Nick Schrock, who previously was a co-creator of GraphQL at Facebook. Similarly, Prefect was founded in 2018 by Jeremiah Lowin, who took his learnings as a PMC member of Apache Airflow in designing Prefect.
Both projects are approaching a common problem but with different driving philosophies. Dagster takes a first-principles approach to data engineering. It is built with the full development lifecycle in mind, from development, to deployment, to monitoring and observability. Prefect, on the other hand, adheres to a philosophy of negative engineering, built on the assumption that the user knows how to code and makes it as simple as possible to take that code and built it into a distributed pipeline, backed by its scheduling and orchestration engine.
Both projects are gaining a lot of traction and rapidly improving. Let’s look at how these two projects handle some of the challenges Airflow struggles with.
Local Development and Testing
With Airflow, local development and testing can be a nightmare. If your production Airflow instance uses Kubernetes as an execution engine, then your local development will then need Kubernetes locally as well, as a task written with the S3Operator requires a connection to AWS S3 to run: not ideal for local development.
# In Airflow, the task writes to S3, using the S3 hook, and the function doesn't take any arguments.
def to_s3():
path_file = 'test.csv'
df = pd.read_csv(path_file)
csv_buffer = StringIO()
df.to_csv(csv_buffer)
s3 = S3Hook(aws_conn_id='my_s3')
s3.get_conn()
s3.put_object(Body=csv_buffer.getvalue(),
Bucket=BUCKET_NAME,
Key='test.csv')
task_to_s3_op = PythonOperator(
task_id='UploadToS3',
provide_context=True,
python_callable=to_s3,
dag=dag
)
With Dagster, compute and storage are two different concerns and can be abstracted away. Instead of explicitly providing a particular Kubernetes instance to your DAG, your functions accept inputs and outputs and its up to the resources that are configured at run-time to persist the data, whether that’s a local temp file for development, or an encrypted object store in the cloud in production.
# In Dagster, a function is explicit about data frames as inputs and outputs. How these are persisted is defined at run-time, not in the code itself.
@solid
def filter_over_50(people: DataFrame) -> DataFrame:
return people.filter(people['age'] > 50)
# Resource definitions can be swaped out depending on the environment through code
calories_test_job = calories.to_job(
resource_defs={"warehouse": local_sqlite_warehouse_resource}
)
calories_dev_job = calories.to_job(
resource_defs={"warehouse": sqlalchemy_postgres_warehouse_resource}
)
Prefect also supports a level of abstraction on storage although through RunConfigs.
from prefect import Flow
from prefect.run_configs import KubernetesRun
# Set run_config as part of the constructor
with Flow("example", run_config=KubernetesRun()) as flow:
...
This doesn’t provide the same level of abstraction as Dagster, however, which can make local development more tricky. For Prefect, parametrization is the focus of local development. By being able to parametrize your Flows, you can provide smaller datasets for local development and larger ones for production use.
Scheduling Tasks
In Airflow, off-schedule tasks can cause a lot of unexpected issues and all DAGs need some type of schedule, and running multiple runs of a DAG with the same execution time is not possible.
With Prefect, a Flow can be run at anytime, as workflows are standalone objects. While we’re often waiting 5-10 seconds for an Airflow DAG to run from the scheduled time due to the way its scheduler works, Prefect allows for incredibly fast scheduling of DAGs and tasks by taking advantage of tools like Dask.
Similarly, Dagster allows a lot of flexibility for both manual runs and scheduled DAGs. You can even modify the behavior of a particular job based on the schedule itself, which can be incredibly powerful. For example, if you want to provide different run-time configurations on weekends vs weekdays.
@schedule(job=configurable_job, cron_schedule="0 0 * * *")
def configurable_job_schedule(context: ScheduleEvaluationContext):
scheduled_date = context.scheduled_execution_time.strftime("%Y-%m-%d")
return RunRequest(
run_key=None,
run_config={"ops": {"configurable_op": {"config": {"scheduled_date": scheduled_date}}}},
tags={"date": scheduled_date},
)
And running a job in Dagster is as simple as:
dagster job execute -f hello_world.py
Data Flow in Airflow, Prefect, and Dagster
One of the biggest pain points with Airflow is the movement of data between related tasks. Traditionally, each task would have to store data in some external storage device, pass information about where it is stored using XComs (let’s not talk about life before XComs), and the following task would have to parse that information to retrieve the data and process it.
In Dagster, the inputs and outputs to jobs can be made much more explicit.
import csv
import requests
from dagster import get_dagster_logger, job, op
@op
def download_cereals():
response = requests.get("<https://docs.dagster.io/assets/cereal.csv>")
lines = response.text.split("\\n")
return [row for row in csv.DictReader(lines)]
@op
def find_sugariest(cereals):
sorted_by_sugar = sorted(cereals, key=lambda cereal: cereal["sugars"])
get_dagster_logger().info(
f'{sorted_by_sugar[-1]["name"]} is the sugariest cereal'
)
@job
def serial():
find_sugariest(download_cereals())
It’s clear in the above example that the download_cereals op returns an ouput and the find_sugariest op accepts an input. Dagster also provides an optional type hinting system to allow for a great testing experience, something not possible in Airflow tasks and DAGs.
@op(out=Out(SimpleDataFrame))
def download_csv():
response = requests.get("<https://docs.dagster.io/assets/cereal.csv>")
lines = response.text.split("\\n")
get_dagster_logger().info(f"Read {len(lines)} lines")
return [row for row in csv.DictReader(lines)]
@op(ins={"cereals": In(SimpleDataFrame)})
def sort_by_calories(cereals):
sorted_cereals = sorted(cereals, key=lambda cereal: cereal["calories"])
get_dagster_logger().info(
f'Most caloric cereal: {sorted_cereals[-1]["name"]}'
)
In Prefect, inputs and outputs are also clear and easy to wire together.
with Flow("Aircraft-ETL") as flow:
reference_data = extract_reference_data()
live_data = extract_live_data()
transformed_live_data = transform(live_data, reference_data)
load_reference_data(reference_data)
load_live_data(transformed_live_data)
The transform function accepts the outputs from both reference_data and live_data. For large files and expensive operations, Prefect even offers the ability to cache and persist inputs and outputs, improving development time when debugging.
Dynamic Workflows
Another great feature of both Dagster and Prefect that is missing in Airflow is an easy interface to creating dynamic workflows.
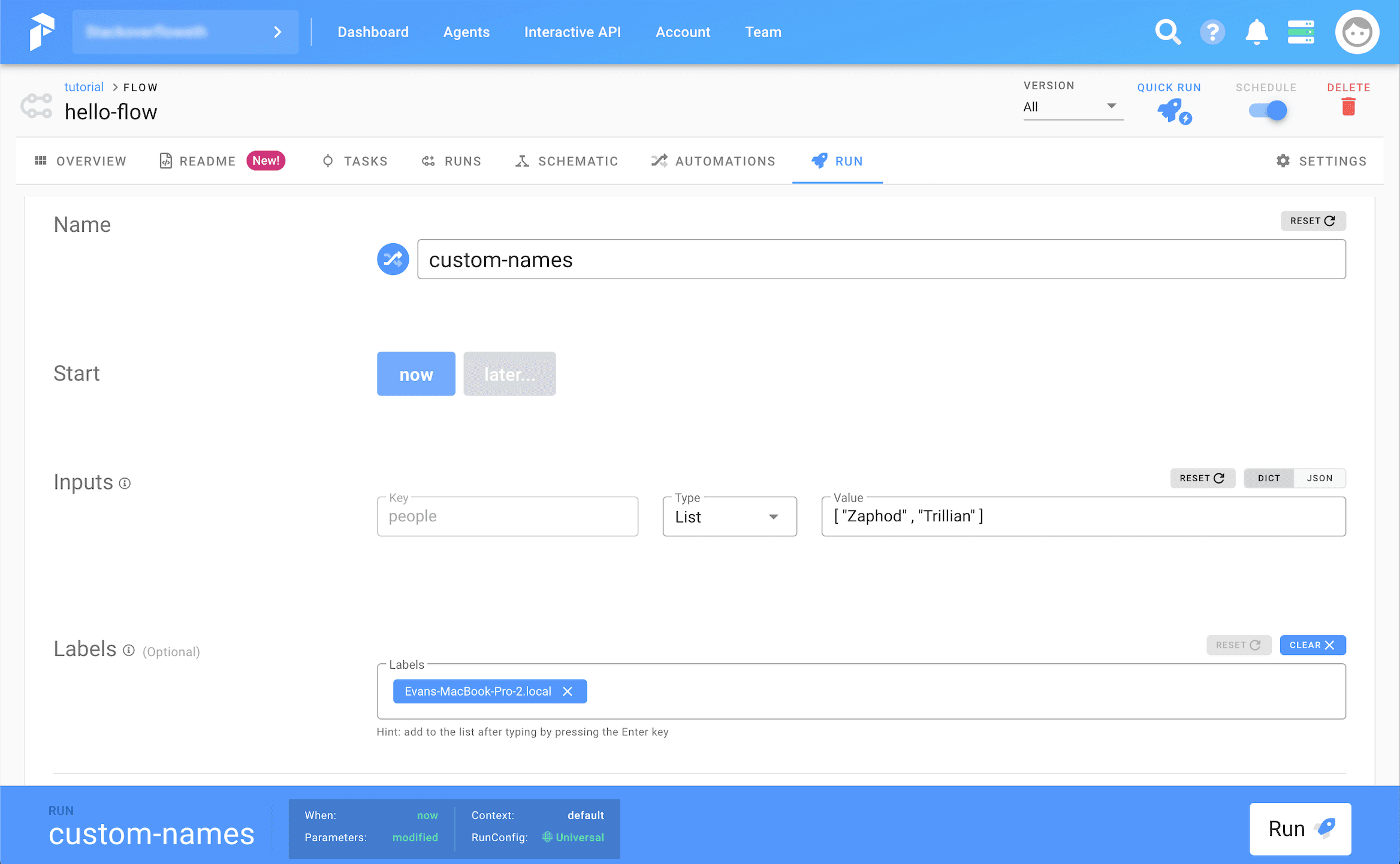
In Prefect, parameters can be specified in the Cloud Interface or provided to the Flow runner explicitly. This makes scaling out to large complex computations easy, while allowing for sane initial development as you work on your pipelines.
In Dagster, you can define a graph and then parametrize the graph to allow for dynamic configurations, which the ability to fully customize resources, configurations, hooks, and executors.
from dagster import graph, op
from dagster import ResourceDefinition
@op(required_resource_keys={"server"})
def interact_with_server(context):
context.resources.server.ping_server()
@graph
def do_stuff():
interact_with_server()
prod_server = ResourceDefinition.mock_resource()
local_server = ResourceDefinition.mock_resource()
prod_job = do_stuff.to_job(resource_defs={"server": prod_server})
local_job = do_stuff.to_job(resource_defs={"local": local_server})
Wrapping Up
I hope this was a helpful exploration of some of the new orchestration tools that have started to gain traction in the data landscape. Despite the shortcoming of Airflow, it still is a solid and well-architected platform that serves many people well. However, competition in this space will only help improve all the tools as they learn and improve from each other. I’m excited to see how this space develops and would love to know what you think.

















