
These days there’s a ton of emphasis on “the modern data stack.” Every company seems to be trying to build or implement one, and every SaaS vendor claims to be part of the solution. With countless data tools available, and so much noise in the market, it’s becoming harder and harder to decipher the true definition of a modern data stack.
A Quick History of the Modern Data Stack
Before 2010, the cloud was basically non-existent. Building out a data-centric organization meant purchasing and provisioning legacy hardware or servers. For a long time, Oracle had a monopoly in this area as the first company to create a mainstream relational database. And with the rise of open-source frameworks built around Hadoop and Postgres, companies quickly realized that they had options for managing and storing their data.
The problem was these platforms were innately slow and cumbersome. As a result, operating them efficiently was extremely time-consuming, making it nearly impossible for marketing and business teams to act on their data in a timely way.
However, in 2012 the world witnessed what is now called “the first Cambrian explosion” and the adoption of cloud infrastructure with AWS Redshift (Amazon’s cloud data warehouse.) Redshift changed the entire data landscape because it was the very first cloud MPP (massively parallel processing) data warehouse run entirely in the cloud. The key difference between Redshift and other MPP platforms at the time was the price and the performance.
Because Redshift was hosted entirely in the cloud, suddenly any organization could afford to do analytics. Whereas most relational databases at the time were row-oriented, Redshift was built on a columnar structure, making it ideal for storing large amounts of data in various formats from various systems. Prior to Redshift, performing any type of analytics was costly and time-consuming – which meant that only the largest organizations with the deepest pockets even had access to data warehouses.
In 2016, the market shifted again with the rise of Snowflake, a data warehouse inspired by Redshift. Snowflake took what Redshift built to an entirely different level, creating the first fully managed SaaS platform for analytics. Snowflake removed all of the underlying maintenance that came with Redshift, and successfully separated storage and compute resources. The result was a platform that was dramatically faster and cheaper than Redshift.
With the rapid adoption of Snowflake and the speed and capabilities that came with the platform, marketing and data teams quickly realized that they no longer needed to rely on conventional ETL tools to unlock the value of their data. With platforms like Snowflake, data engineers could cost-effectively load raw data into the warehouse and transform it afterward. This gave rise to a new process known as ELT (extract, load, transform), where data is transformed using the computing power of the warehouse – and thus the modern data stack was born, enabling platforms like customer data platforms (CDPs) to empower marketing teams with real-time, actionable customer data, along with a new suite of tools and an onset of cloud technologies.
Legacy Data Stack vs. Modern Data Stack
The core differentiator between a traditional data stack and a modern data stack is the difference between on-premises hardware and cloud-native tools. Legacy data stacks are hosted entirely on-premises, meaning the hardware has to be individually provisioned, managed, and scaled as the needs of the business change.
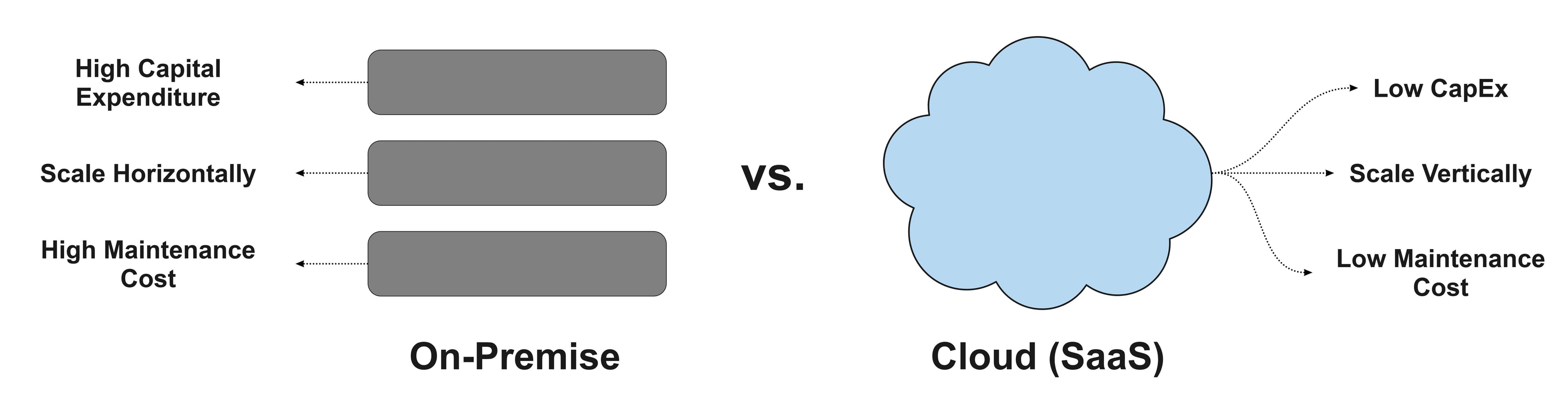
On-Premise vs. Cloud
By contrast, modern data stacks are hosted entirely in the cloud, which means all of the underlying maintenance that comes with managing hardware is done automatically as a service. Cloud and SaaS-based tools remove a huge burden on users because it gives them the ability to focus on business outcomes rather than technology.
Modern data stacks are also much more cost-efficient because users pay solely for usage rather than needing to procure the underlying resources themselves. This is possible because large SaaS platforms power them with huge economies of scale.
What Makes a Modern Data Stack Unique?
Everyone in tech uses the term “modern data stack” interchangeably and there’s not exactly a universal definition; however, there are several common themes that all modern data stacks share.
They’re built around a centralized analytics platform. Modern data stacks are also designed to be composable, meaning each product or SaaS tool should be a separate, configurable, and interchangeable component of the larger architecture. Individual tools should be chosen based on simplicity, speed, and scalability.
- Simplicity: How easy is the tool to use? Is it fully managed/SaaS and accessible to both technical and non-technical users, including marketers?
- Speed: How fast and performant is the tool?
- Scalability: Does the tool scale with the desired use cases?
The entire premise behind a modern data stack is to create an end-to-end flow of data from acquisition, to integration, to persistence — where every layer is centered around the analytics platform. Ultimately, the architecture and cloud infrastructure of a modern data stack should look something like this.
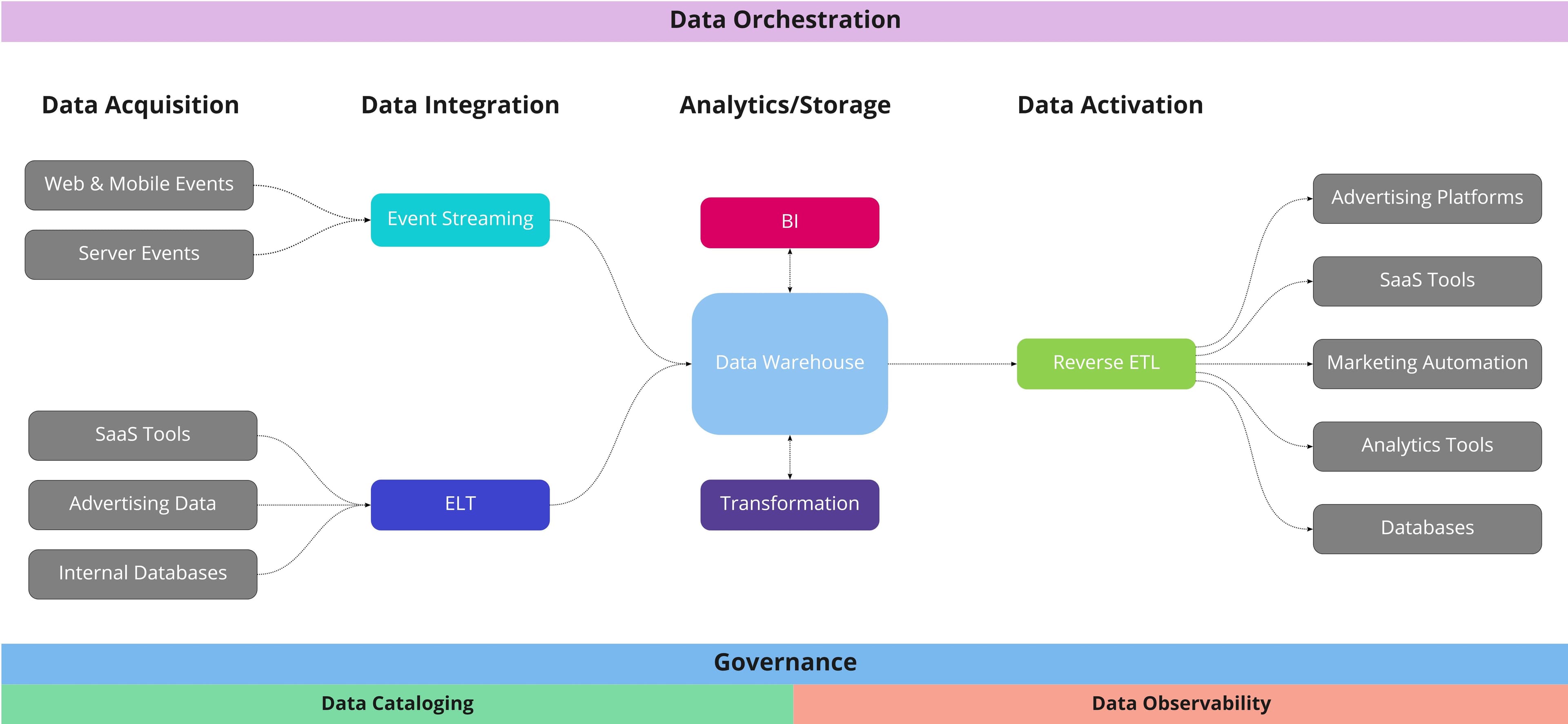
The Components in a Modern Data Stack
Modern Data Stack Architecture
Although the architecture and tools used might differ from company to company, there are several core components within every modern data stack.
Data Acquisition
Data acquisition is the initial collection point of data and the source where it is generated. Most of the time this data is collected from SaaS tools, advertising platforms, IoT devices, internal databases, server events, or even web and mobile events.
Event Tracking
Event tracking specializes in capturing and collecting important behavioral data pertaining to customers or users. Events can include anything from pages viewed, last login date, items added to cart, etc. In the past, event tracking was handled entirely by web pixels and third-party cookies, but with recent consumer privacy changes, this has become less feasible, and more major companies are beginning to implement an event tracking solution directly within their architecture.
Data Integration
Data integration is the process of moving data from the source to the analytics layer. However, depending on the source, the method for data integration can vary. Generally, there are two types of data integration: batch-based and real-time.
Batch-based ingestion loads large quantities of data at a scheduled interval or after a specific event has been triggered using ELT tools. It’s more cost-effective and efficient than real-time ingestion and the data is usually pulled from SaaS tools, internal databases, advertising platforms, etc.
Real-time ingestion is used for event streaming and it’s based on the behavioral event data from users and customers. This type of data includes web, mobile, and server events.
Storage/Analytics
The storage and analytics layer is the resting place for data after it has gone through the integration process. Usually, this is a data warehouse, but it could also be a data lake or a data lakehouse. The premise behind this layer is to consolidate all data from every disparate source into a centralized platform for analysis and create a single source of truth. A cloud data warehouse eliminates the need to hop back and forth between systems and gives engineers and analysts the ability to leverage data in a single platform, to analyze and drive more value.
Data Transformation
Data transformation takes place in the data warehouse, and it’s focused on properly formatting and validating data to make it easier to consume. Data transformation is often used to standardize data, replicate data, delete data, or even restructure data as it’s ingested into the warehouse.
The main focus of data transformation is often data modeling. Data models represent specific data elements and connections. Often, they are unique to the business – but they can include anything from LTV, ARR, lead score, playlists, subscriptions, etc.
BI (Business Intelligence)
With data models in place, analysts need a way to consume that data and visualize it in a way that makes sense to the business. BI is the process of persisting the data within the analytics layer to a visualization tool that can summarize it in a way that makes sense to the business.
In many cases, BI tools simply connect directly to the data warehouse. BI is focused on leveraging the data in the analytics layer to gain insights and inform business decisions. Usually, this means building reports and dashboards that automatically refresh after the transformation jobs finish running in the warehouse.
Data Orchestration
With all of the layers in a modern data stack and the various data pipelines that come with it, managing dependencies between various layers, scheduling data jobs, and monitoring everything can be quite difficult. Data orchestration solves this problem by automating processes and building workflows within a modern data stack. With data orchestration, data teams can define tasks and data flows with various dependencies.
Data orchestration is based on a concept known as DAG (direct acrylic graphs), or a collection of tasks that reflect the relationships and dependencies between various data flows. Data engineers use data orchestration to specify the order in which tasks are completed, how they’re run, and how they’re retried (e.g. when X data is ingested trigger Y transformation job). Anastasia Myers wrote a great blog on this exact topic. With data orchestration, engineering teams can easily author, schedule, monitor, and execute jobs in the cloud.
Data Governance
Data governance is all about monitoring and managing data assets. When it comes to governance, there are really only two pillars: data observability and data cataloging.
Observability is entirely focused on monitoring the health of data through monitoring, alerting, and triaging. This is done by analyzing data freshness, data ranges, data volume, schema changes, and overall data lineage. The purpose of data observability is to provide real-time visibility into data pipelines so that users can troubleshoot and debug to ensure data is always accurate and up-to-date.
On the other hand, data cataloging seeks to understand exactly what data exists and where it exists. For many organizations, there are often multiple data sources in the analytics layer in addition to a data warehouse, and identifying where data lives can be challenging. The easiest way to understand data cataloging is to think of it as a search engine for data assets.
Data cataloging helps data teams tag their data assets using metadata so they can easily search and find relevant information across large volumes of data. Data cataloging automatically organizes every data asset across every data source so that teams can more easily consume data.
Data Activation
Data Activation focuses on solving the “last-mile problem” in a modern data stack. Once data has been persisted into the warehouse, the only other place it lives is in a dashboard or a report. Visualizations are useful for decision-making but less applicable to various business teams.
Business users and teams don’t live in the warehouse; they all work with a different set of tools where a holistic view of the customer is not readily available. Data Activation democratizes the data within the warehouse using Reverse ETL to sync it back to downstream tools, and it enables a number of use cases:
- Marketing: sync custom audiences to ad platforms for retargeting and lookalike audiences
- Sales: enrich data in Salesforce or Hubspot (e.g. lead score, LTV, product usage data, etc.)
- Success: use product engagement data to reduce churn or identify upsell opportunities
- Finance: update ERPs with the latest inventory numbers and sync customer data into forecasting tools
Modern Data Stack Benefits
Aside from greatly lowering the technical barrier to entry, there are several benefits to a modern data stack. Firstly, modern data stacks are built with business users in mind. The composable cloud-based architecture eliminates vendor lock-in, removes data silos, and consolidates everything into a centralized data warehouse. Secondly, SaaS tools are extremely scalable and cost-effective. Instead of having to provision hardware and estimate usage over the next year, companies can simply pay for usage and scale resources up or down in real-time based on demand. Data engineering and analytics teams free up significant time by using off-the-shelf connectors and can instead focus their energy and attention on driving business outcomes.
Tools In the Modern Data Stack
With such a large ecosystem of tools and so many different technology vendors to choose from, it’s difficult to know how to build a modern data stack. Below are a few general recommendations.
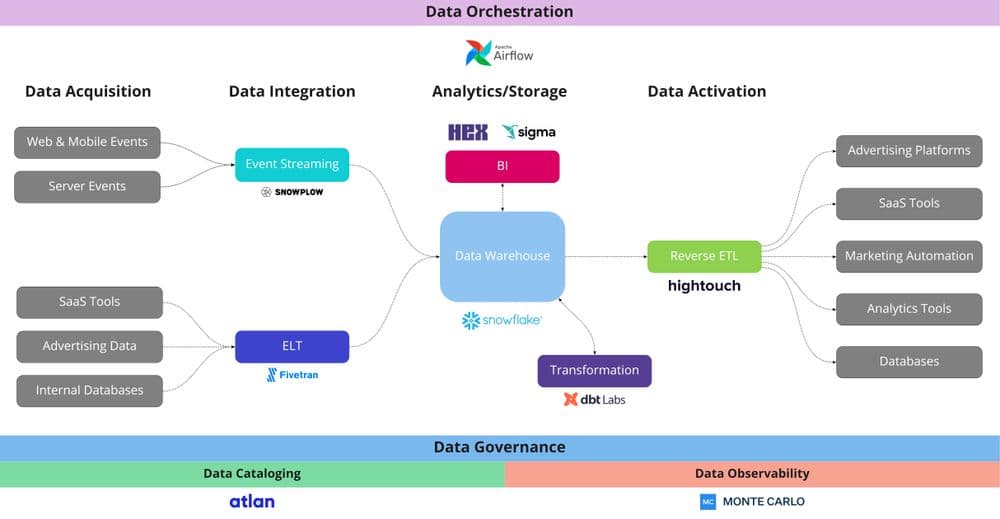
Modern Data Stack Technologies
- Event Tracking: There are a variety of ways to tackle event collection. In the context of a modern data stack, Snowplow is a great event tracking vendor. As an open-source behavioral data platform and event tracker, Snowplow is used to collect and ingest behavioral data (e.g. web, mobile, and server events).
- Data Integration: When it comes to data integration, Fivetran is a great integration tool. It’s a SaaS platform that offers pre-built connectors to extract data from hundreds of sources and load it into the desired destination. It eliminates the engineering effort associated with ELT.
- Storage/Analytics: There are a ton of analytics tools, but Snowflake is by far the best option. It’s a fully managed SaaS data platform that runs on SQL and is deployable across any cloud. Currently, Snowflake is mainly used for analytics and batch-based workloads but its capabilities are rapidly expanding. Databricks alternatively, is a data lake and it's mainly used to address real-time and AI/ML use cases. Another platform to consider is Google BigQuery because it’s similar to Snowflake and it offers all of the capabilities of Google Cloud Platform (GCP) and integrates natively with Google Analytics.
- Transformation: When it comes to data transformation tools, dbt is the only one worth looking at. dbt makes it easy to build templated SQL queries with various dependencies that can be used for data modeling and scheduled to run on a regular basis within the data warehouse.
- BI (Business Intelligence): BI is still an evolving space within the MDS, companies like Sigma Computing are building modern BI Reporting tools built for the cloud-native data warehouse, while tools like Hex enable collaborative knowledge-sharing that makes analysis more intuitive than traditional data notebooks.
- Data Orchestration: Airflow is probably the most widely known and used orchestration tool, but Dagster or Prefect are compelling alternatives. Airflow is an open-source platform run by Apache for building, running, and maintaining entire workflows to automate data flows.
- Data Governance: There are a lot of data governance tools available, but two companies making waves in the space are Atlan and Monte Carlo. Atlan is an impressive catalog tool that makes it easy to search for data assets like tables, columns, dashboards, etc., and run queries across different tools in a single platform. Monte Carlo is an observability platform focused on eliminating data downtime, proactively identifying data-related issues, and preventing broken pipelines.
- Data Activation: As a Data Activation platform powered by Reverse ETL, Hightouch queries directly against the data warehouse and automatically syncs data back to various SaaS tools and operational systems (e.g. CRMs, ad platforms, marketing automation tools, etc.) This ensures business teams always have the most up-to-date data directly in the tools they use every day.
What’s Next for the Modern Data Stack?
There’s really no such thing as the ideal “ modern data stack”. Every company uses different technologies and modern tools to solve a different set of problems. While the tools used may differ from company to company, the individual layers which make up a modern data stack remain the same. Technologies are constantly evolving; what was relevant five years ago is much less relevant today (Hadoop is a great example), and this trend will likely continue.
For a long time, the data warehouse was considered the final piece in a modern data stack. However, the data warehouse is no longer the final resting place for data because it’s only accessible to technical teams who know how to write SQL. Non-technical users across marketing, sales, success, etc. want to activate the unique data that lives in the warehouse in the tools that they use on a daily basis via Reverse ETL – and that means syncing data from the warehouse back into operational tools. Luckily this is the exact problem Hightouch solves and best of all, the integration is completely free.

















