
AI Decisioning is a new class of marketing technology that delivers 1:1 personalization. Instead of relying on journeys or static segments, it uses AI agents to continuously learn which experiences drive the best outcomes for each customer. In this four-part series, we’ll explain some of the core technologies: reinforcement learning, multi-armed bandits, and contextual bandits. By the end, you’ll understand how these technologies fit together to create 1:1 personalization that works at scale.
In our last post, we examined the gap between expectations and reality in marketing personalization and noted how current paradigms (calendars and journeys) are tied to predefined rules and segments. Most marketing teams want to deliver 1:1 experiences, but segments, rules, and journeys just don’t get there. They group people together by design, while customers want experiences that reflect their individual patterns and preferences.
To bridge this gap, we need personalization that works at the individual level. This requires a system that can:
- Learn which actions (content, timing, frequency, etc.) lead to desired outcomes.
- Balance exploring new messages and experiences with exploiting what’s already working.
- Make decisions for each customer based on their individual characteristics.
In this post, we’re addressing the first requirement. We can’t know what will work for every individual in advance, so we need a system that learns which offers convert for specific customers, which send times drive engagement, and which channels each customer prefers. Reinforcement learning (RL) is a type of machine learning that automates this discovery through experience. AI agents systematically test actions, observe outcomes, and continuously refine their approach. This framework lets AI agents test and optimize decisions for each customer automatically.
Learning through experience
Before we get into the technical concept of reinforcement learning, let’s build a feel for it through a familiar experience: working on marketing campaigns.
We’re familiar with the campaign lifecycle: design and develop a campaign, launch it to an audience, measure results, adjust the approach, and then try it again. We iterate, and over time develop an intuition for what works for different audiences.
Along the way, we discover patterns about our customers:
- Our premium customers ignore discounts, but act on early access
- B2B buyers engage with business value content most on Tuesday mornings
- Customers who abandon cart only respond to nudges within 2 hours
We learn through experience. We take actions, observe outcomes, and gradually refine our mental model for our customers and what drives business results.
While most teams or individuals test one or two hypotheses a week across segments, reinforcement learning systems can test thousands of combinations of messages, timings, and channels at the individual customer level.
The future of marketing is autonomous
Take your marketing beyond human scale with AI Decisioning. Instead of manually orchestrating campaigns, AI agents learn from your data, run limitless experiments, and deliver the best experience for each customer. Discover how to automate decision-making, drive repeat purchases, enable upsells, and increase loyalty with continuous learning loops.

How reinforcement learning works
While marketers develop their intuition over months and years, reinforcement learning automates the process through a systematic framework.
The learning framework
Here’s the basic feedback loop for reinforcement learning. An agent:
- Selects an action
- Interacts with the environment
- Receives a positive or negative response
- Chooses the next action based on its experience and desired outcomes
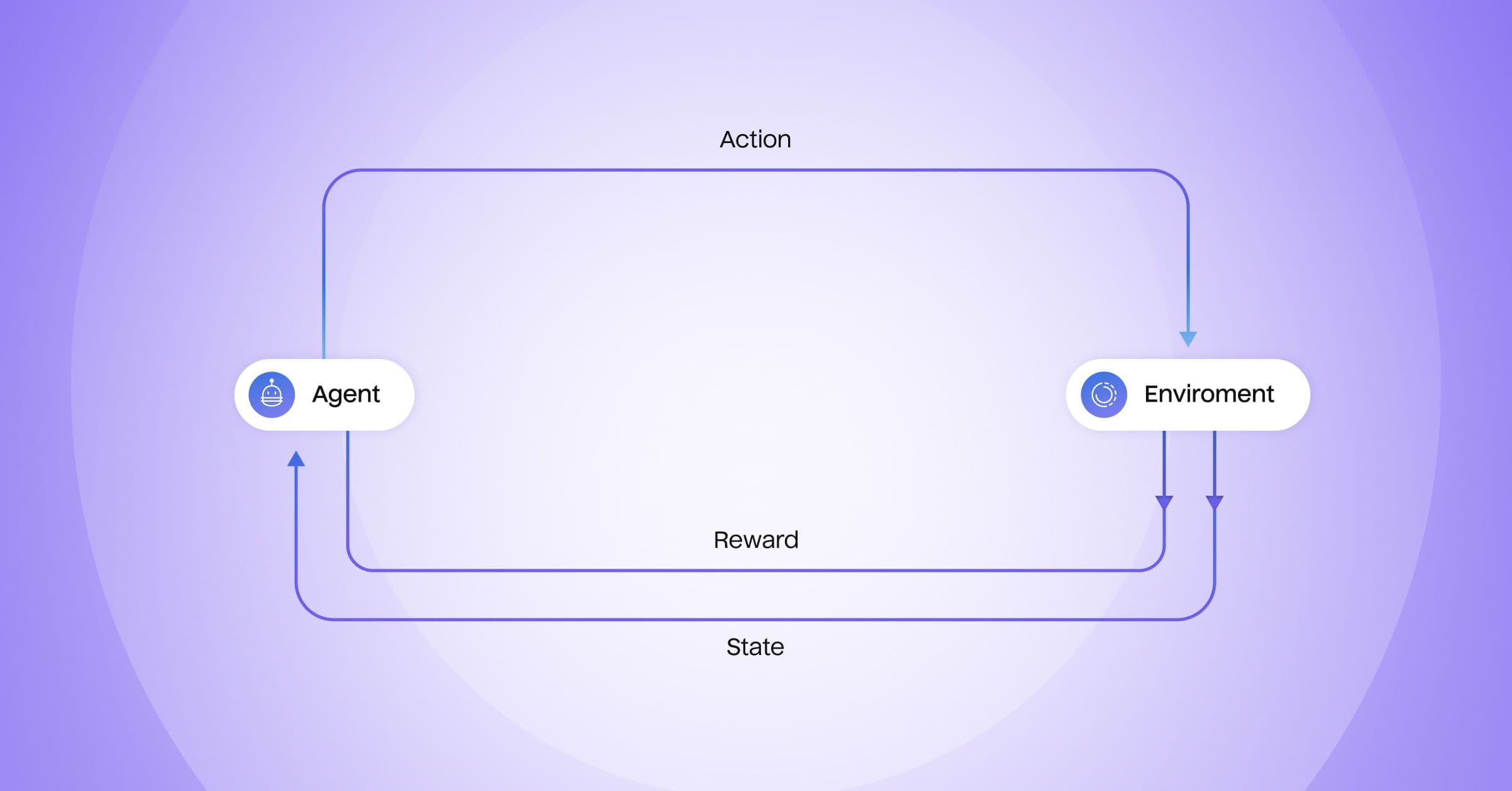
Continuous experimentation allows the reinforcement learning model to choose actions that maximize the desired outcome more effectively.
Understanding the components with marketing examples
We’ll use a cross-sell campaign as an example to understand what each part of the reinforcement learning system does.
Here’s what the concepts are in marketing terms:
An agent is the AI system that decides what, when, and how to send to each customer.
Actions are all the possible decisions the agent can make, such as:
- Whether to send a message
- Which channel to send it through (email, SMS, in-app)
- When to send it (Tuesday at 8 AM vs Friday at 4 PM)
- Which cross-sell offer to send (complementary products, bundles, new category)
- Which message type to send (value-focused, social proof, feature-focused)
The environment is what the agent interacts with, in this case, your customers and their data.
Rewards are the outcomes that the agent optimizes for, tailored to your business goals. For cross-sells, this could include new category purchases, cart additions, and product page visits. For winback goals, this could be reactivation purchases, return visits, or email opens. Agents can optimize for multiple rewards, balancing immediate engagement (e.g., clicks) with high-value outcomes (e.g., purchases or lifetime value).
Let’s see how this works in practice. Imagine that we’re marketers at a retail company, and we’re running a cross-sell campaign with AI Decisioning. The agent decides on a specific cross-sell message and how and when to send it, such as an office furniture email with a 10% off offer to a customer who has bought a computer monitor.
The customer receives this email, clicks through, and purchases a desk. The agent records this positive outcome and updates its understanding.
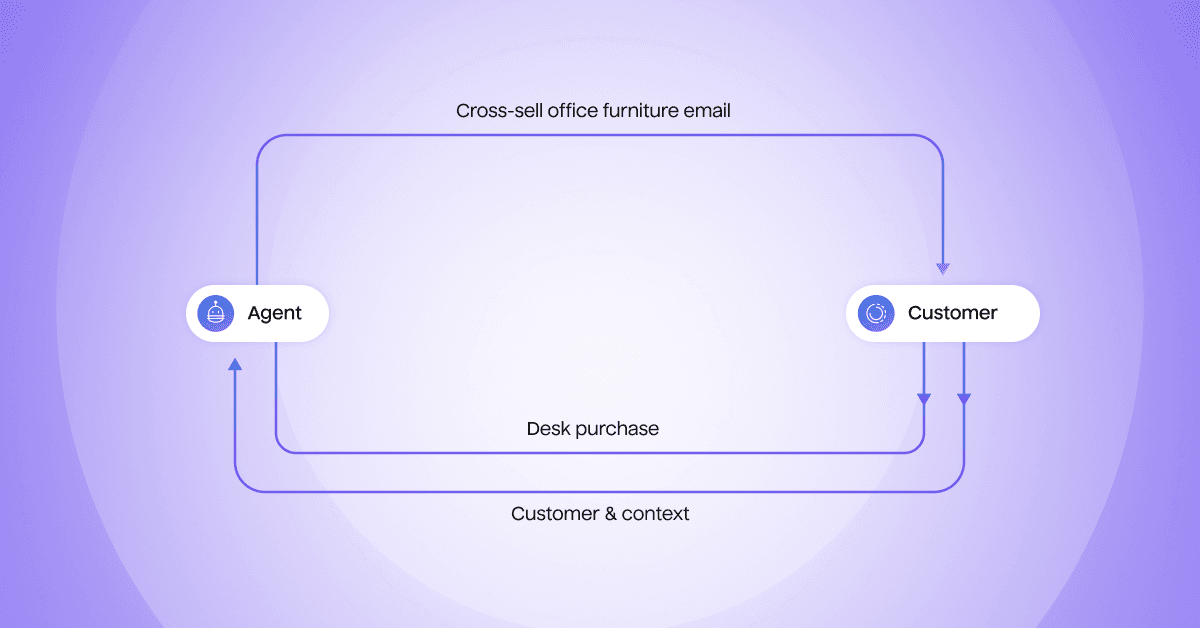
Through thousands of interactions like this, the agent builds an increasingly sophisticated understanding of this specific customer and their preferences while learning from patterns across all customers.
Maybe it discovers that our customer responds best to furniture emails on Tuesday morning and prefers email to SMS, while also identifying patterns like:
- Recent monitor buyers respond best to ergonomic furniture offers
- Morning email sends are more effective for remote workers
- SMS messages during lunch hours work well for gaming enthusiasts
A reinforcement learning agent excels at learning at both levels. It can discover individual customer patterns and responses that no marketer could manually track while also identifying broader patterns across customers.
Segment-based marketing vs. agentic marketing
With the context of high-scale experimentation and rapid learning loops, we can see the contrast between segment-based marketing and reinforcement learning-based marketing.
A marketer’s segment-based workflow
- Form hypothesis: "Electronics buyers might want furniture"
- Define segment: "Purchased electronics in the last 90 days"
- Build journey: Map decision paths for different responses (opened vs didn’t open, clicked vs didn’t click)
- Create campaign assets: Multiple messages, offers, and timings across journey branches
- Run A/B test: Test one variable (maybe subject line) across journey entry points
- Wait for results: Check performance after a week, analyzing journey paths
- Manually adjust: Update based on winning variant across journey branches
- Repeat: Test the next variable
The AI agent approach works differently
How does this compare to the AI agent approach?
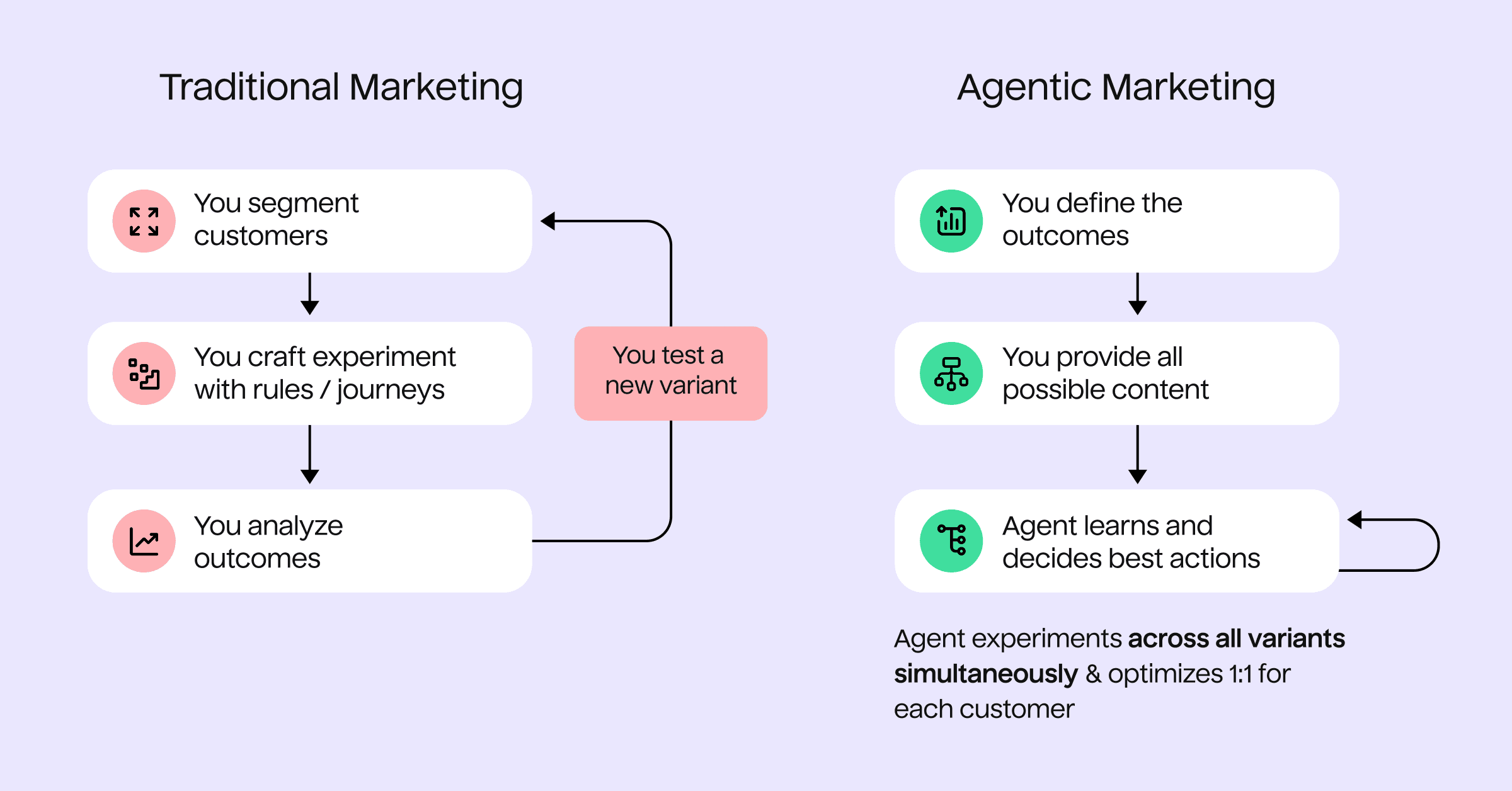
Instead of building complex journeys and testing one variable at a time across static segments, an AI agent continuously experiments with multiple variables for individual customers. For example, when someone shops for a monitor, the agent may send them a furniture bundle email on Tuesday at 2 pm based on similar customers. It tracks the results and updates its understanding of that specific customer and similar patterns, so the next monitor buyer gets a refined approach based on what’s worked.
While marketer workflows using batch & blast emails or triggered journeys run into slowdowns from complexity and limits to how much can be tested at once, reinforcement learning-based tools like AI Decisioning experiment incredibly quickly and with more variables. This enables them to discover and activate patterns at the segment level, like “buyers of monitors respond well to furniture offers,” and the individual level: “Sarah responds to office furniture and accessory emails on weekday evenings, but only after she’s purchased a tech item and the discount is at least 10%.”
From learning to optimization
Reinforcement learning gives AI agents a systematic way to discover what works for individual customers through continuous experimentation, beyond the scale of what marketers can manually do. Learning is only part of the solution, though. How do we decide which actions to try in the first place?
How long do we keep sending messages that seem to work, and when do we experiment with new messages, times, and more?
Testing every message equally wastes resources and can deliver poor customer experiences, but sticking only with what works means missing opportunities to discover what might work even better.
In our next post, we’ll look at multi-armed bandits, a specific type of reinforcement learning that provides an approach to balancing exploitation of what we’ve learned with exploration of new options.
If you're interested in AI Decisioning, unlocking more value from your existing marketing channels, and increasing the velocity at which you can experiment and learn, book some time with our team today!

















