
Hightouch uses the power of Reverse ETL to transform your core business applications from siloed data islands into powerful integrated solutions that boost your organization’s effectiveness.
Fine-tuning when Hightouch syncs kick-off, visualizing their dependencies, and monitoring the steps in your data activation workflow is about to get easier with today’s launch of Hightouch’s native integration in Dagster, the data orchestration platform for the modern data stack.
The Modern Data Stack
It’s been very exciting watching the modern data stack evolve over the last decade. The pace of innovation has been staggering and large and monolithic data integrations platforms (like IBM, SAP, and Informatica) have proven too bulky to keep up.
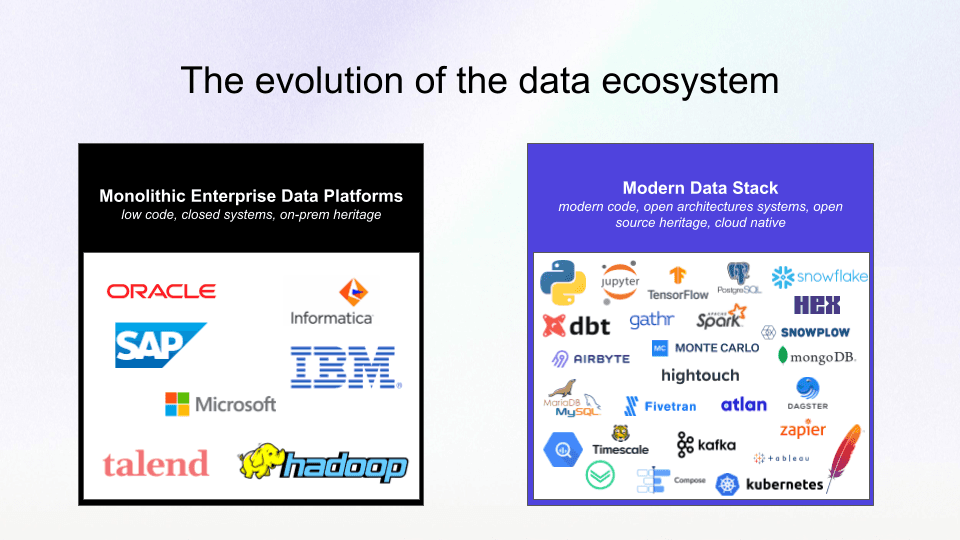
The Evolution of the Data Ecosystem
Today—with the power of elastic compute, advanced connectivity, and more affordable cloud storage—your data teams are picking best-of-breed solutions and building their own customized, lean, high-performance data platforms.
They synchronize all their data applications from SaaS tools and internal apps into data warehouses, push that data through ML models and data analytics, up into data visualization and reporting, and back out to your company’s business applications—all to get an always-up-to-date and 360-degree view of your customer. This modular, bespoke approach maximizes the value of your data. To tightly synchronize and monitor all the steps required for moving data throughout the modern stack, orchestrators were developed.
Orchestrating the Modern Data Stack
Workflow orchestration is not a new concept. Early solutions like Luigi and Apache Airflow have been around for a decade or so. But the data stack has evolved rapidly since then, and engineers require new approaches that support their new way of working: namely, evolving from a basic task-focused module to a centrally-managed and robust development framework that accounts for the multi-faceted dependencies of today’s environments.
We’re really excited about tools like Dagster, the data orchestration project backed by the company Elementl, that was purpose-built for orchestrating the modern data stack. Dagster takes a first-principles approach to data engineering and was built with the full development lifecycle in mind (from development, to deployment, all the way through monitoring and observability). Dagster provides both a development framework and a single operational pane of glass for the orchestration layer of the modern data stack.
If you’re looking to learn more about today’s leading orchestration platforms you can check out our recent rundown of the workflow orchestration space here.
Workflow Orchestration: An End-To-End Example
At Hightouch, we’re committed to providing the best experience possible for data practitioners. That’s why we integrate with the data tools you know and love. Our native integration with Dagster helps your modern data teams more effectively orchestrate the last mile of data analytics—bringing that data from the warehouse back into the SaaS tools your business teams live in. With our Dagster integration, Hightough users have more granular and sophisticated control over when data gets activated. Let’s look at an example.
Let’s say you’re an analytics engineer who partners closely with the marketing team, and they’re running an account-based marketing (ABM) campaign as part of their quarterly strategy. The ABM manager wants up-to-date account maps to more strategically identify which decision-makers to target so they can build downstream campaigns that reach them in the right place, at the right time, with the right message.
You need to automate account mapping in your company’s customer relationship management (CRM) tool so they can hit their campaign goals. Oh, and they needed this, like, yesterday.
Data is flowing into your warehouse nightly via an ETL tool like Fivetran. That data is getting transformed in the warehouse with dbt, and now you need it to flow back into your CRM tool—all while keeping that data fresh and accurate. Without automated orchestration, that workflow looks something like this:
- Schedule Fivetran to ingest data to the warehouse daily at 1 am
- Schedule your dbt model to run at 3 am (hoping that nothing went wrong with Fivetran and the import is completed)
- Customize your Hightouch syncs to start at 5 am with 30-minute buffers between each of your 4 syncs (Contacts, Accounts, Workspaces, Organizations)
Technically, this works–but it has a lot of lags and dependencies. It hinges on the assumption that everything upstream is completed successfully and on time. This could be so much more efficient.
This example is quite possibly the simplest workflow. Imagine doing this with a complex nested DAG with dozens of steps and upstream dependencies. It gets unwieldy very fast.
As Nick Schrock at Elementl put it:
It’s like having a production line with three different workstations handing off components to each other. But each workstation is siloed and can’t communicate with the next. As each station packages and pushes components to the next, they have no clue if what they’re sending is updated or correct. The next station gets what it gets, or sometimes gets nothing at all. If the production line stops suddenly, it takes a while to figure out where the problem lies.
The Hightouch Dagster integration alleviates this problem by orchestrating the flow of data from Fivetran into your warehouse, refreshing the models via dbt Cloud, and syncing your data to your CRM using Hightouch.
What’s more, with the Dagster interface, you gain deep visibility into each step of the process: from the time it takes to refresh your models, to the number of rows that were successfully sent to your CRM. Equipped with those insights, you can prioritize and tackle engineering work to continuously improve your data pipelines.
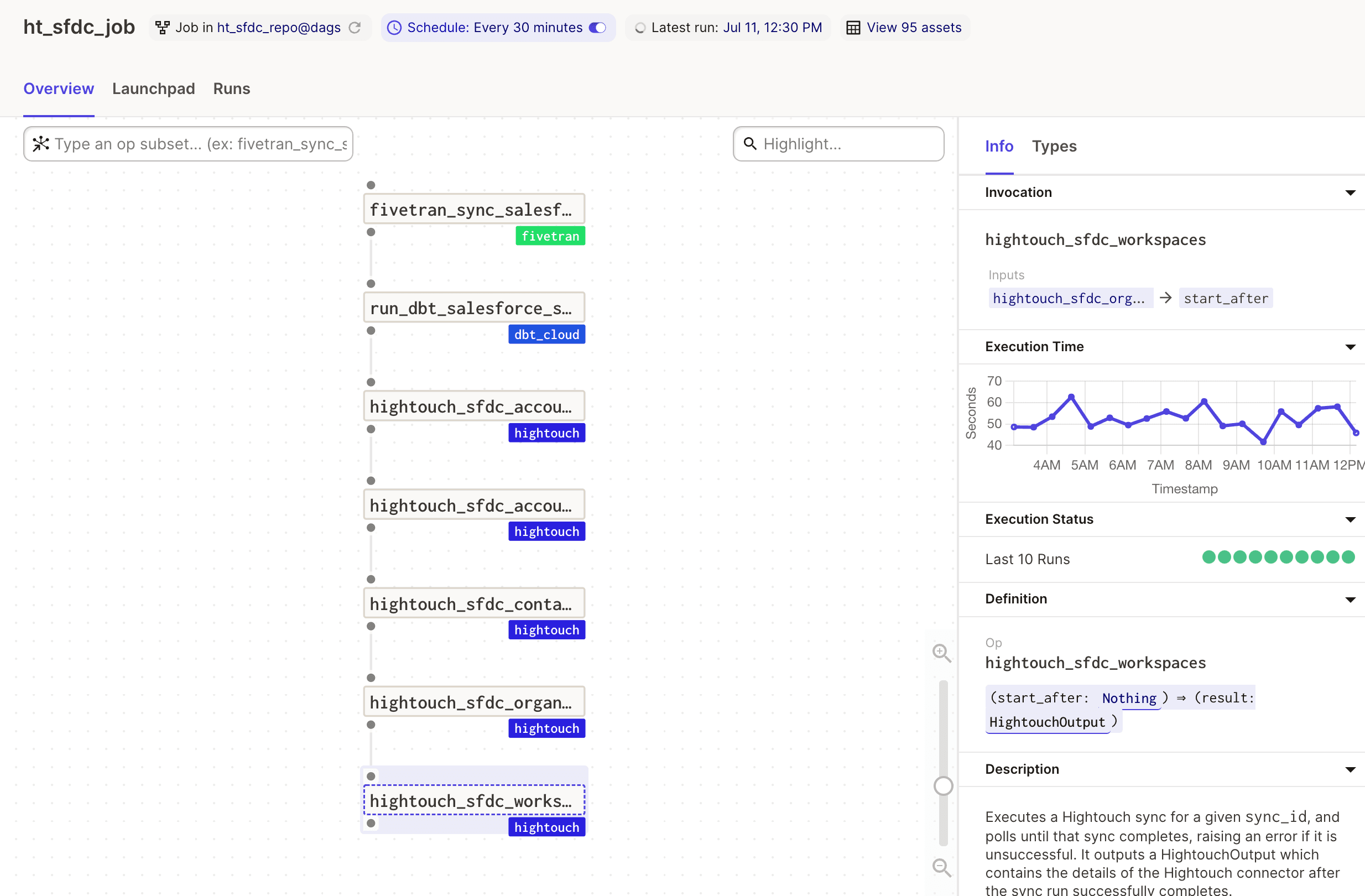
Dagster Processes
This approach has many benefits for both engineering and business teams:
- Data freshness: The total time it takes to move customer data through the end-to-end pipeline shrinks from hours to as little as 15 minutes.
- Workflow automation: By centrally managing robust orchestration pipelines, your data teams can focus on more proactive work
- Operational efficiency: Your teams avoid using compute credits on redundant transformations or calculations.
As the modern data stack rapidly evolves, it is essential that leading data tools integrate seamlessly. With the great work done by both our teams, Dagster can now make Hightouch operate seamlessly and robustly, ensuring that the right data goes into the right app at exactly the right time. - Nick Schrock, Founder and CEO, Elementl
Setting up the Hightouch Integration
Configuring the Hightouch integration in Dagster is a streamlined process:
- Install the Hightouch Dagster Library
- Configure the Library to use your Hightouch API Key
- Write the code that defines your syncs and their dependencies
As you can see from the code sample below, there’s very little code required.
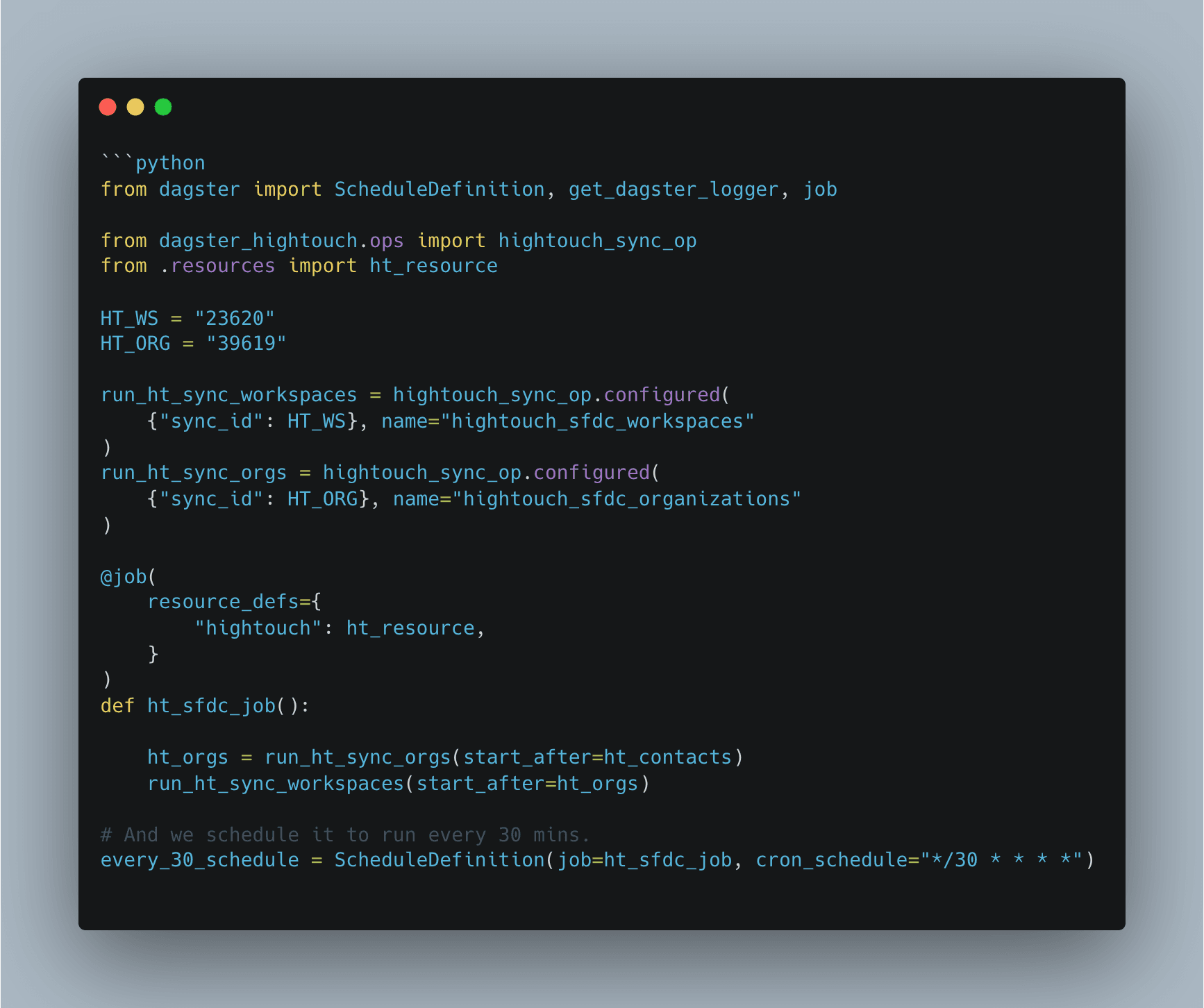
Code Dependencies
And that’s it! On top of integrating natively with all of the other orchestration steps in your modern stack, you can:
- See and schedule all of your Hightouch syncs
- View sync execution trends over time
- Get a birds-eye-view of execution status and recent runs.
You can run this pipeline as often as you want to ensure your data is constantly refreshed. You can also quickly view all of the destinations that Hightouch writes to as Dagster Assets, including the objects we write to. In addition, you can see a snapshot of your latest run (how long it took, rows added/changed/removed), and track these trends over time.
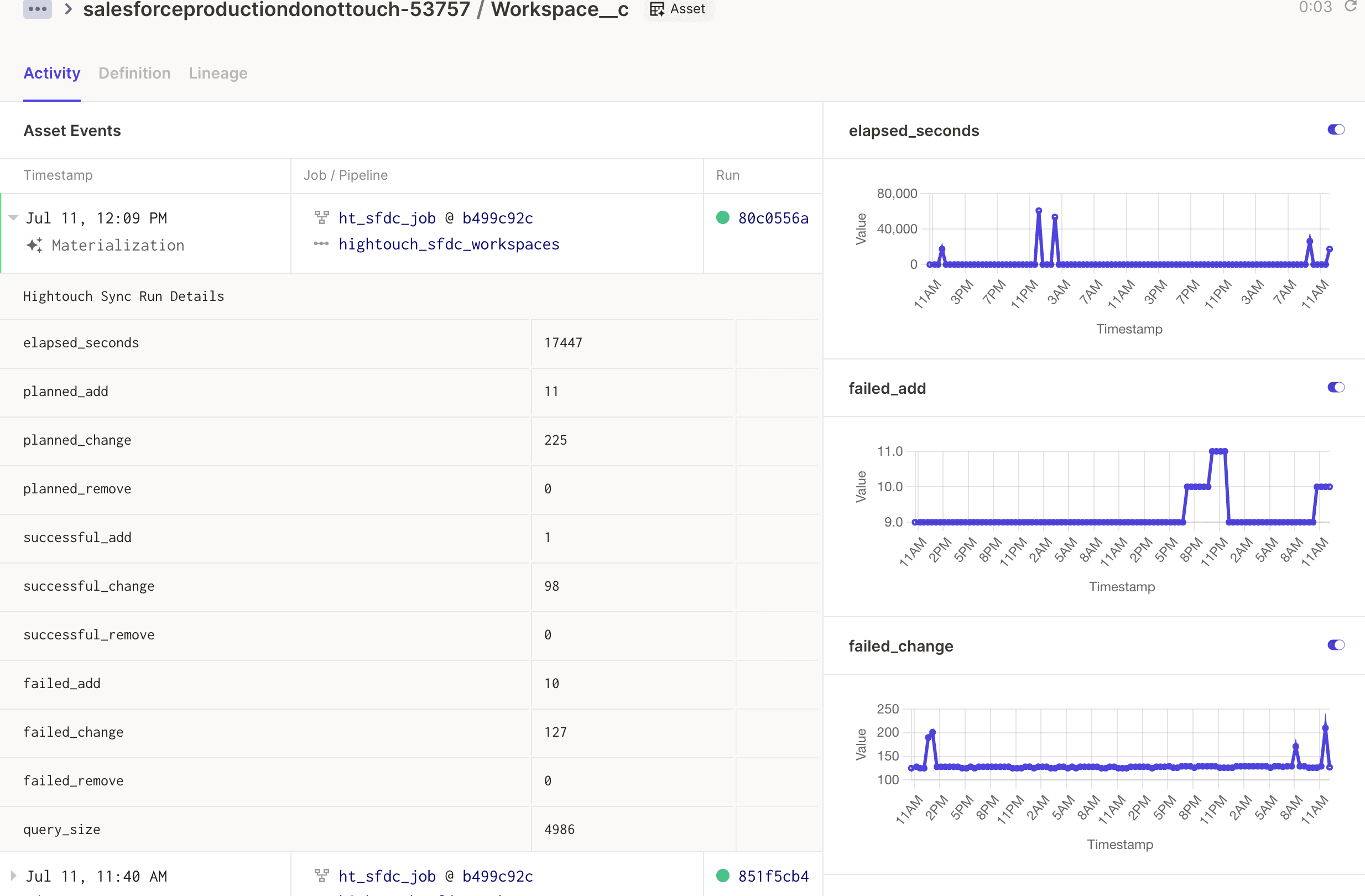
Dagster Assets
Next steps
The Hightouch Dagster integration is available now! If you’re not a Hightouch customer yet, you can sign up for a free account.
If you’re new to Dagster, it’s available as an open-source solution today and Dagster Cloud will be GA in August. Contact the Dagster team for details, or check out the growing Dagster community.

















