
Every company wants to be more data-driven, but actually translating your insights into action and unlocking that last mile of “analytics” enablement is really difficult. Thanks to the rapid adoption of modern cloud data warehouses, there’s more data available now than ever before.
For years, these systems have only been accessible by technical data folks, but the reality is your business teams want and need access to this data, and this operational analytics need has given rise to Reverse ETL.
In this blog post, you’ll learn
- What is Reverse ETL?
- How Reverse ETL Works
- What’s the Difference Between ETL and Reverse ETL?
- Reverse ETL Use Cases
- Alternatives to Reverse ETL
- Reverse ETL Tools
- Should You Build Reverse ETL?
What is Reverse ETL?
Reverse ETL is the process of syncing data directly from a data warehouse to the operational systems used by your marketing, advertising, and operations teams. This process turns your existing data infrastructure into a composable CDP and sets the foundation for an AI-powered marketing platform, where audiences, traits, and decisions can be activated across every channel, with governance and control anchored in the warehouse. In practice, Reverse ETL helps both marketers and technical teams move faster, marketers get self-serve activation, and data teams maintain quality, security, and compliance.
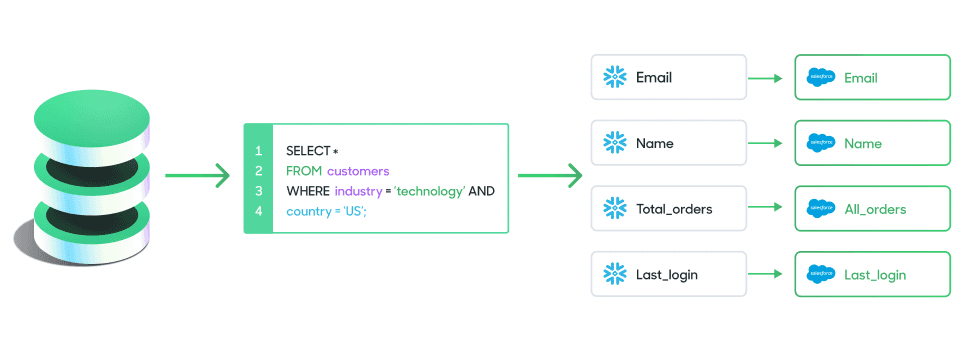
How Reverse ETL Works
Most of the time, when you want to move data out of the data warehouse, you have to submit a ticket to your IT team and wait for them to pull a manual CSV file or build a custom data pipeline for you. Reverse ETL automates this process, creating a seamless bridge between data and marketing or any other business team. For marketers, this means you can build and activate audiences without waiting on manual exports or fragile one-off pipelines. You can keep segments continuously updated, trigger journeys from fresh product and behavioral signals, and ensure every destination uses the same governed customer definition, without relying on heavy SQL or engineering support. And it means everyone across your organization can access the same rich insights and the same core customer definition that lives in your warehouse directly in the tools they use daily.
You can take the core insights and data models that live in your warehouse and sync them to any destination of your choosing in seconds. For a B2B business, this might include metrics like active workspaces, last login date, churn rate, LTV, lead score, etc.; for a B2C company, this might include traits like purchase propensity, high-spenders, shopping cart abandoners, etc. Reverse ETL puts this data directly into the hands of your business users to further unlock the value of your data warehouse so you can go beyond static reporting and take action on your data.

Syncing Data to Salesforce
What’s the Difference Between ETL & Reverse ETL?
Traditional ETL (extract, transform, load) pipelines have been around since the 1970s, and for the most part, these data pipelines have largely remained unchanged. When you hear the term ETL, you probably imagine extracting data from an external source, transforming it, and then loading it into your data warehouse. For years, ETL was thought of as the primary process of powering your analytics use cases and consolidating your disparate data across all your sources into a single unified platform.
Reverse ETL has a much different goal because the purpose of Reverse ETL is to take the rich insights that live in your warehouse and put that information into the hands of your business teams so they can drive outcomes that move the needle.
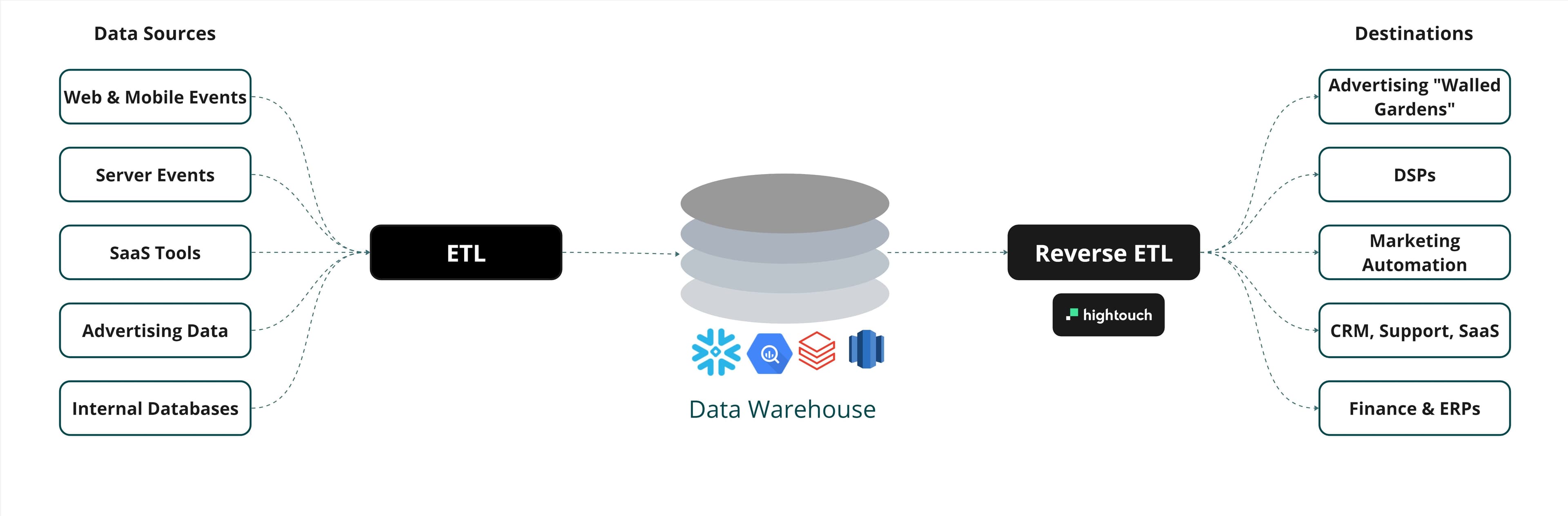
ETL & Reverse ETL
With the ETL process, you’re merging and loading data into tables using “updated_at” fields, and you’re writing to one consistent data schema that you own and manage. If you make a mistake in this process, you can simply delete the table in your warehouse and re-ingest all of your data.
The Reverse ETL process is the opposite because you’re moving data from your warehouse and writing directly to third-party APIs. Third-party tools are much more restricted compared to data warehouses because you don’t own the schema structure, which means you have to conform your data to the constraints of a third-party vendor. You also have to be really careful when you sync data because most business applications don’t have an undo or rollback button if you overwrite fields with bad data. This is why governance is a core requirement for Reverse ETL at scale. Teams need strong controls like field-level permissions, approvals, audit logs, environment separation, and reliable sync observability to ensure data is accurate, compliant, and safe to activate in business-critical systems.
To make matters worse, every third-party API comes with its own special nuance and technicality, which can cause sync failures. With Reverse ETL, you have to deduplicate your data and compare the values of your current warehouse query to what you’ve previously synced to ensure you only send fields to reduce costs and unlock faster speeds. With traditional ETL, you don’t have to worry about this because data warehouses are just more flexible.
How Does Reverse ETL Work?
Reverse ETL works by querying against your data warehouse and writing the results of that query to the downstream tool of your choice. This destination can range from anything from a CRM like Saleforce or Hubspot to an ad platform like Facebook or Google to a lifecycle marketing tool like Braze or Iterable or really any destination that you can think of.
There are four core components to Reverse ETL pipelines: sources, models, syncs, and destinations.
- Sources represent your data infrastructure or the location where your data is stored. Most of the time, this is a data warehouse like Snowflake or a data lake like Databricks.
- Models consist of SQL statements that define how your data is represented and what tables and objects you want to pull from before syncing that data to your destination.
- Syncs allow you to define the data from your model, map records to destination fields, and set a cadence for how often to sync, ranging from scheduled batch updates to near real-time activation for time-sensitive experiences.
- Destinations represent the locations where you need to send your data. The most common destinations for Reverse ETL tend to be CRMs, ad platforms, and lifecycle marketing tools.
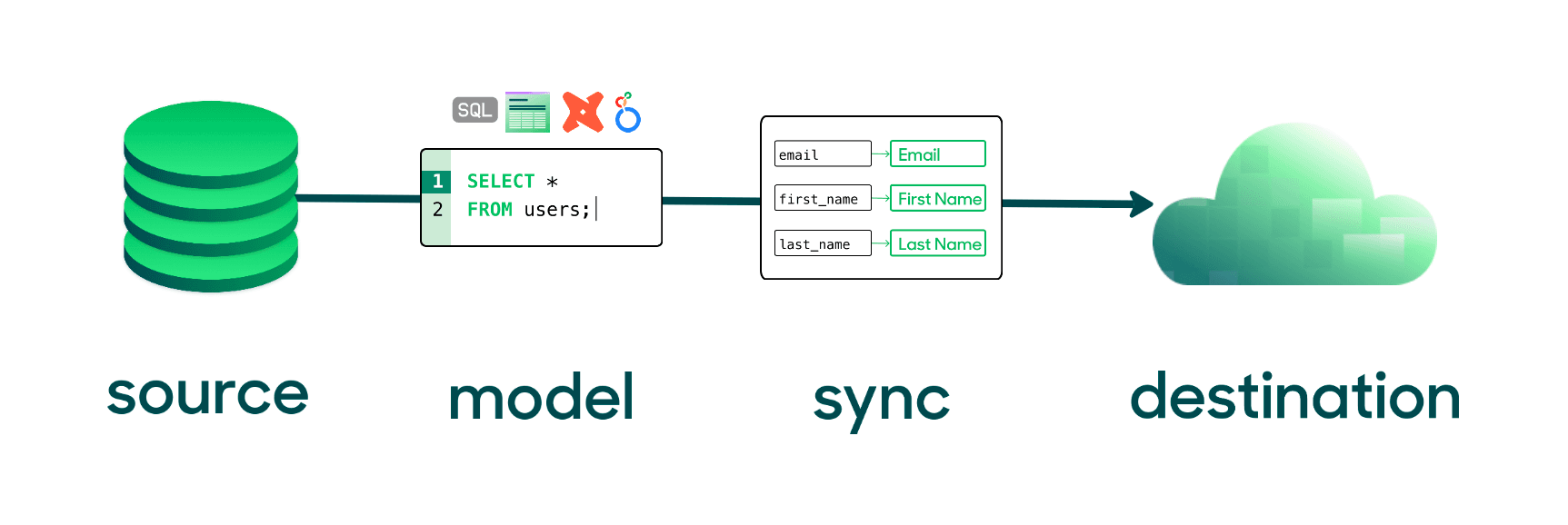
The 4 Components of Reverse ETL
The easiest way to understand Reverse ETL is to think of it as a pipeline that connects your data warehouse to the rest of your organization. This function allows you to easily provide the rich customer data that lives in your warehouse broadly across your business for teams to actually use.
Reverse ETL Use Cases
At a high level, Reverse ETL exists to reliably, scalably, and efficiently move data out of your warehouse so you can power personalization across all the tools in your tech stack. With that in mind, here are a few of the biggest use cases that force companies to adopt and implement Reverse ETL:
- Advertising: Advertising is one of the largest use cases for Reverse ETL because, in many cases, your marketing team is the one requesting access to audience segments to upload and use for creating lookalike audiences, suppressing existing customers/users, and retargeting existing users. With Reverse ETL, you can manage all of these audiences centrally in your warehouse and replicate them across all of your ad platforms. If you manage audience exclusion in your warehouse, this can also have huge implications because you can ensure all of your audiences are up-to-date to protect spend and compliance across all of your ad platforms. You can even sync enriched conversion events from your warehouse to your ad platforms to increase match rates across your marketing campaigns and ultimately boost your return on ad spend (ROAS).
- Lifecycle Marketing: Lifecycle marketing is probably the second biggest use case for Reverse ETL because to deliver personalized communications to your customers, you need to know everything about them. With Reverse ETL, you can sync core attributes (e.g., location, age, gender, income, etc.), traits (e.g., cart abandoners in the past 7 days), or custom data models your data science team has built (e.g., users with a high propensity to purchase). By syncing customer profiles directly to your lifecycle marketing tools like Iterable or Braze, you can trigger journeys in real time based on product behavior and build hyper-personalized journeys and touchpoints unique to each customer.
- Sales: With Reverse ETL, you can also supply your sales teams with rich information that doesn’t natively exist in their tools. For example, you may want to sync modeled data from your warehouse that includes key attributes like product behavior to showcase how your customers are interacting with your app or what pages and products they’re looking at. With Reverse ETL, you can also send alerts directly to messaging tools like Slack to notify your sales reps when specific accounts or users reach certain thresholds or take certain actions so they can proactively reach out in real time.
- Product: Another core use case for Reverse ETL is syncing warehouse aggregations back into your production database to power in-app experiences with fresh user context, in-app dashboards, or even other internal tools at your disposal.
- Finance: Your finance teams can also benefit from Reverse ETL because you can sync reconciled financial information like revenue, invoices, orders, transactions, payment details, etc., directly to your ERP systems or even external locations like SFTP, Google Sheets, or wherever else you need that data.
- Data: From a data team perspective, the main value that Reverse ETL provides is in the automation and reliability of moving data out of the warehouse. Reverse ETL platforms are essentially “set it and forget it” because they don’t store any data; they simply read from your warehouse and write to your destination. Rather than focusing on building and maintaining custom integrations or exporting manual CSV files every time your marketing team wants to run a campaign, with Reverse ETL, all your data team has to do is ensure that the appropriate data is available and servable in your warehouse.
Reverse ETL Alternatives
Reverse ETL is not a new technology by any means, and companies have been trying to activate their data for years via Customer Data Platforms (CDPs) and point-to-point solutions.
Point-to-Point Solutions
Point-to-point solutions like Zapier, Tray, and Workato have been around for a long time, and they can be an attractive option for moving data between systems. These solutions don’t actually enable Reverse ETL because they simply connect systems in a 1-1 capacity. They’re not actually designed to integrate with your existing data infrastructure. The downside to this approach is that it creates an intricate web of pipelines and complex workflows that aren’t scalable.
For example, if you have four applications, you can quickly find yourself with 16 pipelines (4x4 = 16). Actually, getting data to flow to and from your systems requires you to build and manage complex workflows and manage various if/then clauses along with intricate dependencies and complex business logic for every single workflow–and you have to do this for every single one.
Customer Data Platforms
CDPs are marketing-friendly tools that offer a number of features like event tracking, audience management, identity resolution, and activation, but these platforms are also not designed to integrate with your data warehouse. Traditional CDPs collect behavioral data and then route that data to your chosen destination. These platforms tend to be more efficient than point-to-point solutions because you don’t have to manage complex workflows and replicate one-off pipelines. You simply have to route your data through the platform and point it toward your end destination.
However, the platforms are very rigid and inflexible when it comes to how your data is stored and modeled, and they also only give you access to a subset of your data (e.g., the data that lives in your CDP), whereas Reverse ETL gives you access to all of your data. This is one of the many reasons why companies are using Reverse ETL to create a Composable CDP around their existing data warehouse rather than adopt a separate solution that creates a second source of truth and runs in conflict with it. In other words, Reverse ETL lets companies keep the warehouse as the source of truth, and build a marketing-ready activation layer on top, instead of moving data into another black box.
Reverse ETL Tools
While there are many different data integration tools that specialize in moving data, most traditional ETL companies don’t actually provide Reverse ETL offerings. Here’s a quick summary of the top three companies solving Reverse ETL.
- Hightouch is a composable CDP and AI platform built for marketers, with real-time activation at its core. It syncs governed warehouse data into the tools teams use every day, powering audiences, personalization, lifecycle journeys, and AI-driven decisioning without creating a second source of truth. With 300+ destinations and a no-code audience builder, Hightouch is easy for both marketers and technical teams to use, and enterprise-ready with strong security, governance, observability, and reliability.
- Census is a Reverse ETL platform that offers a number of features for moving data from your warehouse to various destinations, but it’s not as flexible as Hightouch when it comes to developer-friendly and marketing-friendly features.
- Segment is a traditional CDP that offers some Reverse ETL capabilities, but given the black-box nature of the platform, the features are tightly coupled together, and the capabilities are still lacking.
Should You Build Reverse ETL?
Building custom Reverse ETL pipelines can become complicated very quickly. Every third-party API is constantly updating, which means you have to closely monitor each and every pipeline or custom integration you build because a single update can break your entire data flow. This isn’t even accounting for all of the other obscure things you have to account for as it relates to authentication, batching, rate limits, field mapping, parallelizing, error handling, monitoring, etc.
Buying a fully managed Reverse ETL tool completely solves these problems because instead of managing API integrations you can simply declare how your data should appear in your end destination. This “write once, use anywhere” architecture lets you send the same data to multiple destinations through one centralized interface.
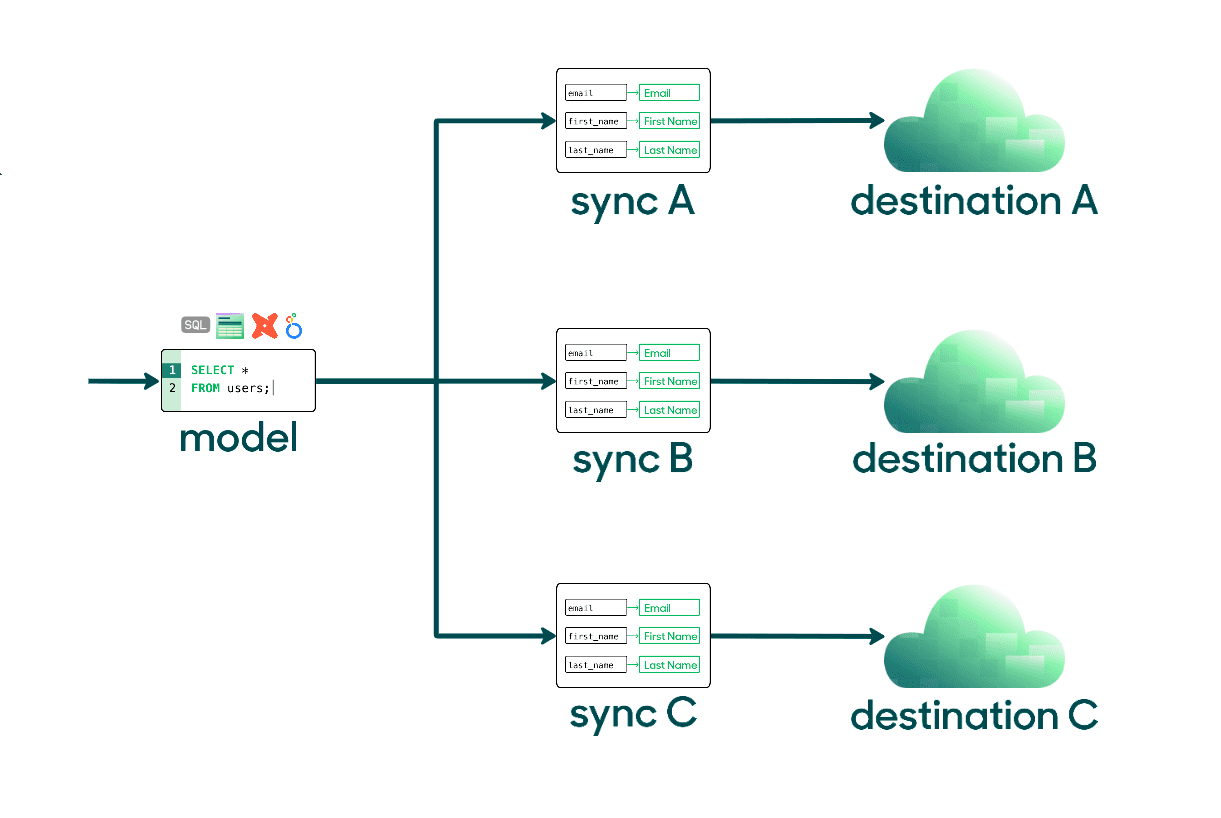
Write once, use anywhere
For example, imagine you want to upload a list of shopping cart abandoners to your ad platforms to run a retargeting campaign. If you built your own Reverse ETL pipelines for this use case, you’d have to create a custom integration for every ad platform in your stack. However, with a Reverse ETL tool, those integrations are already in place and managed for you, and that means you can just copy that same audience across all of your ad platforms. The question you have to ask yourself is, do you want to spend your time building and maintaining integrations or driving business value?
Final Thoughts
Reverse ETL has become the foundation of the modern composable CDP. It provides marketers with real-time activation on top of governed warehouse data, enabling AI-powered personalization without sacrificing control or maintainability. If you’re looking to invest in best-in-class tools and want to have a fully managed Reverse ETL solution up and running in a matter of minutes, schedule a demo with one of our solution engineers today!

















