
If you're setting up a new cloud infrastructure or data team today, dbt, which stands for data build tool, should be a non-negotiable part of your stack. Fishtown Analytics (now known as dbt Labs) raised $150 million in a Series C round of funding, bringing its total valuation $1.5 billion. dbt plays a key role in transforming and preparing your data so it's ready to power customer experiences and marketing campaigns. However, it only handles the "T" or transformation process (it is not an ETL tool like Fivetran). At its core, dbt is a production environment tool that is extremely efficient at scheduling jobs for transformation in your cloud environment.
If you’re still on the fence, or are wondering what the hype is all about, here’s why dbt is experiencing such rapid adoption: it helps analytics engineers to more effectively leverage their time and effort by bringing software engineering best practices to the data world.
dbt Cloud is the SaaS component that accompanies and extends the open-source Core product. By combining an IDE, scheduler, hosted docs and easy interoperability, it’s even easier for a fledgling team to rapidly get momentum. dbt is a complementary tool that fits nicely within any technology stack
A faster development loop with a dedicated IDE
The traditional way to build a dbt project is to use a text editor on your computer. You build models (individual templated SQL queries that can depend on one another) and then use the dbt command line tool to compile the SQL (dbt compile). When you're happy with your results, you materialize the models to your data warehouse (dbt run). The setup process is fast and straightforward, enabling teams to get up and running quickly without heavy engineering resources.

This is a powerful flow, but the CLI doesn't come with a way to preview your query results as you develop. At each stage, you need to copy your compiled code over to your query runner to check if everything works.
Live query results
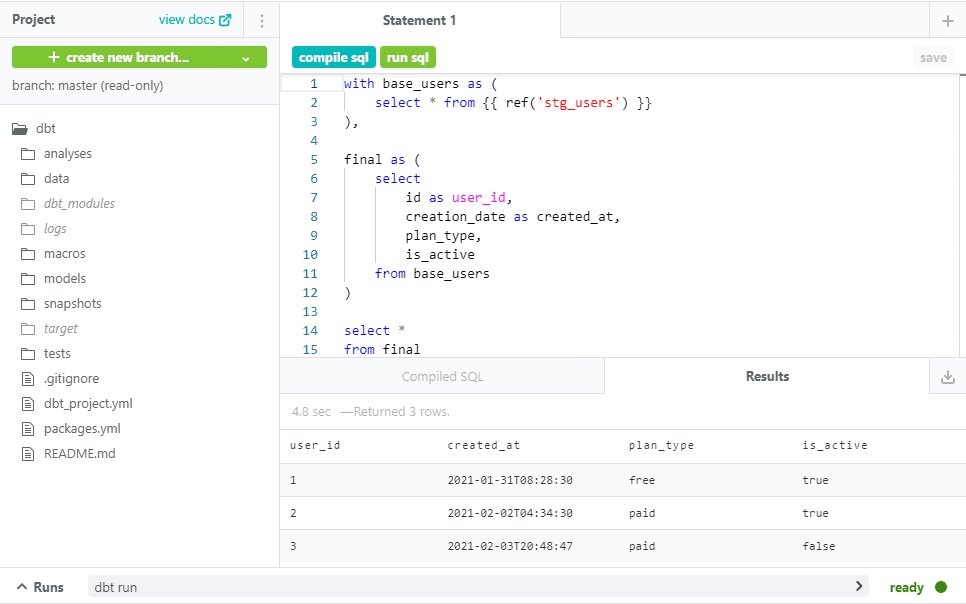
What's unique about dbt Cloud is its integrated development environment or IDE. It dramatically reduces the friction from this iteration process you're just a key command away from previewing the current version of a query. The IDE will compile the query, send it to your data warehouse (with a limit of 500 attached), and show you the results in the same browser tab.
How often do your complex aggregations work exactly the way you want the first time around? Because you can easily run queries as you go, you get to see samples of your data and incrementally build up even the most involved models.
A bespoke editing experience
The IDE has one job: helping your team build and manage data models quickly and accurately, reducing time-to-insight for marketing and business stakeholders. Try typing two underscores in the query editor to get quick access to snippets like custom materializations, scaffolding for new macro definitions, or perfectly-formatted ref statements. When editing a schema.yml file, the IDE knows what properties belong where, and validates your work every time you save a query.
This tight feedback loop also makes dealing with YAML files significantly easier. When I was getting started with dbt, I still didn't fully understand the indentation rules in the config files, and I would have had a much easier time if I'd checked my work more often! The easiest time to fix a bug is when you've just typed it, not when there are 50 new lines of config and you have to hunt down a missing colon.
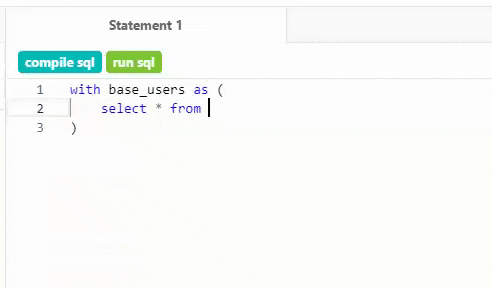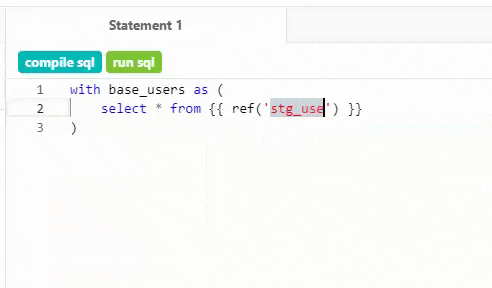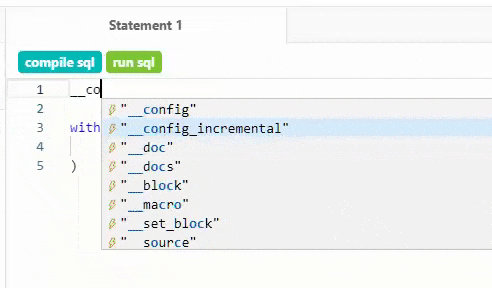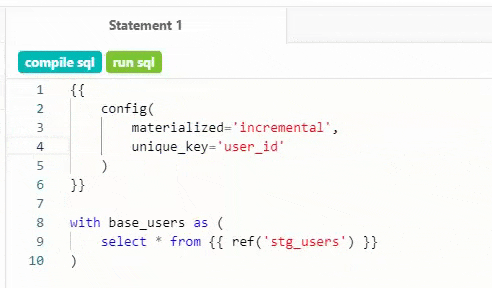
Type __ and let the autocomplete on dbt help with standard code snippets
Easy orchestration
Once created, your dbt models need to run on a regular basis. During development, you trigger runs manually but that doesn't scale. Ideally, you want to run jobs at least overnight to let your colleagues arrive to freshly updated data in the morning. Orchestration tools let you run everything on a schedule (creating an Orchestration Workflow), without having to babysit the process.
Continuous Integration/Continuous Deployment
When a scheduled job starts, dbt Cloud will automatically pull the most up-to-date version of your project from your main git branch and deploy it to your warehouse. If you use GitHub, you can also take advantage of continuous integration when you create a Pull Request, dbt Cloud will automatically kick off a run, check that your job builds successfully, and ensure that your tests pass. If anything's not right, you're notified before merging into main which saves you from the stress of breaking an important downstream report that depends on your tables.

“Slim” CI
Continuous Integration is a crucial way to build confidence in your work but can be slow on established projects. Why should you have to build your entire project when you only added one model? A recent version of dbt Core introduced functionality to enable “Slim” CI — CI jobs that only build and test the modified parts of your dbt project.
Changing to Slim CI can significantly reduce build times (and costs in the case of usage-based platforms like BigQuery and Snowflake) while still providing analytics engineers with confidence in their work.
Everything necessary to enable Slim CI is part of dbt Core, but its deployment is made easier by its integration into the Cloud product. It handles all of the retention of the run artifacts necessary for deferral automatically and gives you an easy UI to configure the setup. This is a common pattern with Cloud vs Core — dbt Cloud provides a straightforward, opinionated way to easily deploy the features in dbt Core.
A great starting point without lock-in
It’s worth noting that there are more fully-featured orchestration tools beyond dbt Cloud, like Dagster, Prefect, or Airflow that can manage your orchestration workflows beyond just dbt jobs. As your team’s maturity grows and you add more interconnected tools into your stack, you might want to transition to one of these solutions.
Even if you eventually adopt an alternative orchestration tool, you can continue to use dbt Cloud’s other features, using Airflow or something similar to treat the job runs as just one step in your broader analytics stack. But until then, the inbuilt scheduler provides all the power you need, including notifications to Slack or email on failure, straightforward environment management, as well as full access to complex node selection syntax.
Democratize your documentation with a hosted doc site
Out of the box, dbt comes with a built-in documentation viewer to help you understand the shape of your project and its dependencies. When developing locally, you can preview it by running the commands dbt docs generate and dbt docs serve, which is helpful for you and anyone else working in your centralized data warehouse.
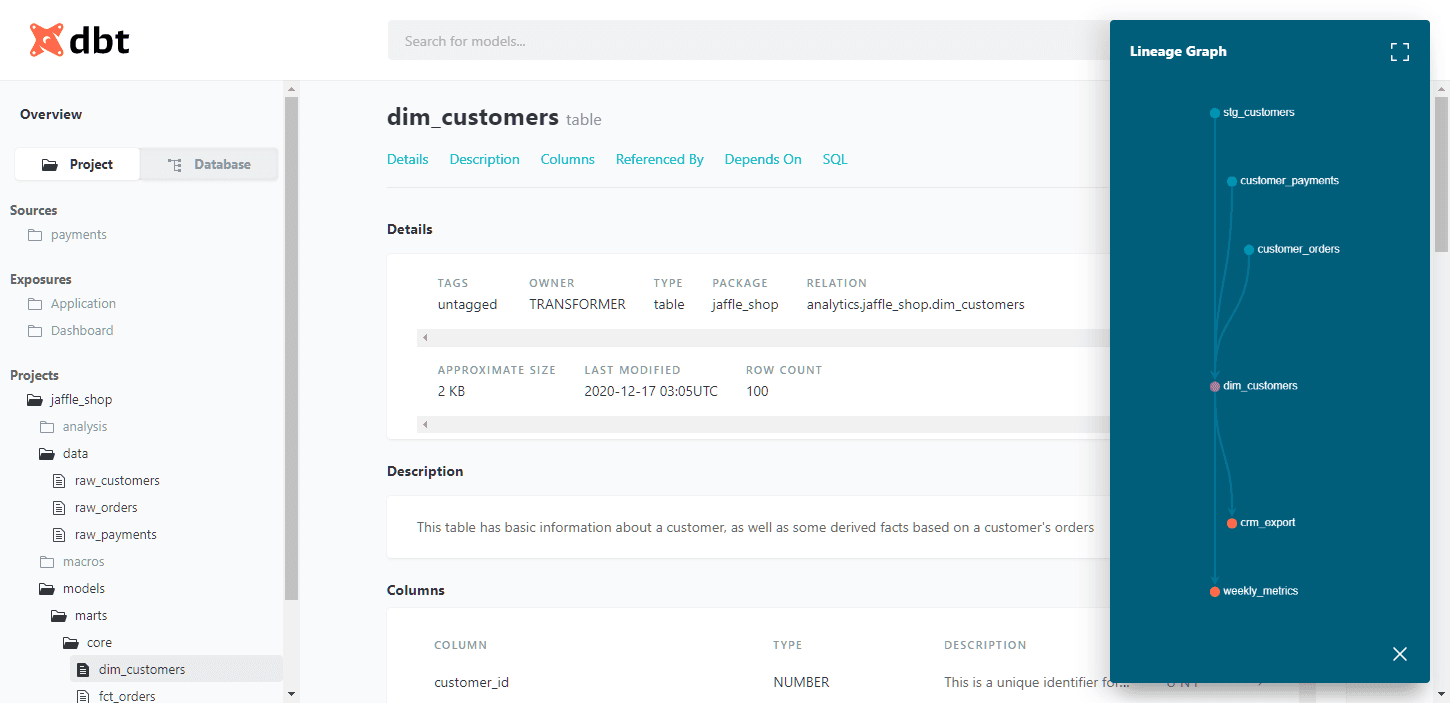
However, you can multiply its impact by also making the documentation available to everyone who accesses your reports. Imagine a world where no one has to ping you on Slack to ask for the definition of MAU, or how it's calculated!
As part of your dbt Cloud account, you get a hosted documentation site with restricted access. Free viewer accounts allow you to make your hard-won documentation available to everybody without having to worry about the logistics of deployment and security.
A team player in the Modern Data Stack
The Modern Data Stack is becoming increasingly more connected and interdependent. Data flows into your warehouse, is cleaned and transformed, and is then ready to be used for dashboards, ML, or maybe even to be fed back into your company’s operational tools. dbt Cloud provides several unique workflows to improve inter-app communication.
Metadata APIs
Behind the scenes, dbt Cloud provides metadata APIs which allow third parties like Mode to increase stakeholder trust on your behalf by showing them the freshness of dbt's data sources. For now, at least, these tools depend on dbt Cloud to provide a consistent endpoint to access this information dbt Core creates the same artifacts but doesn't have a way to advertise their existence externally.
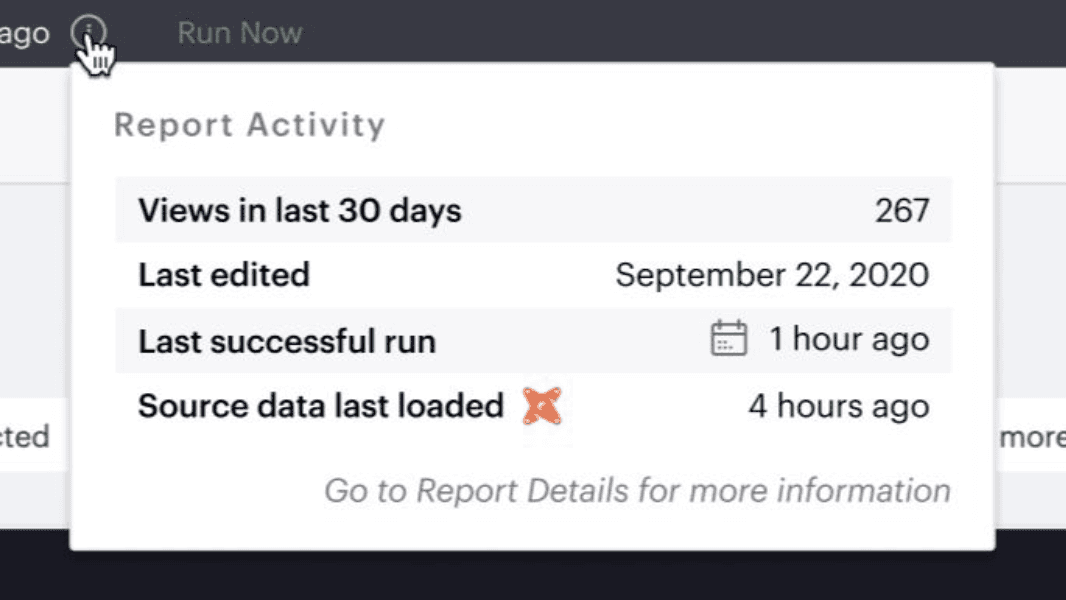
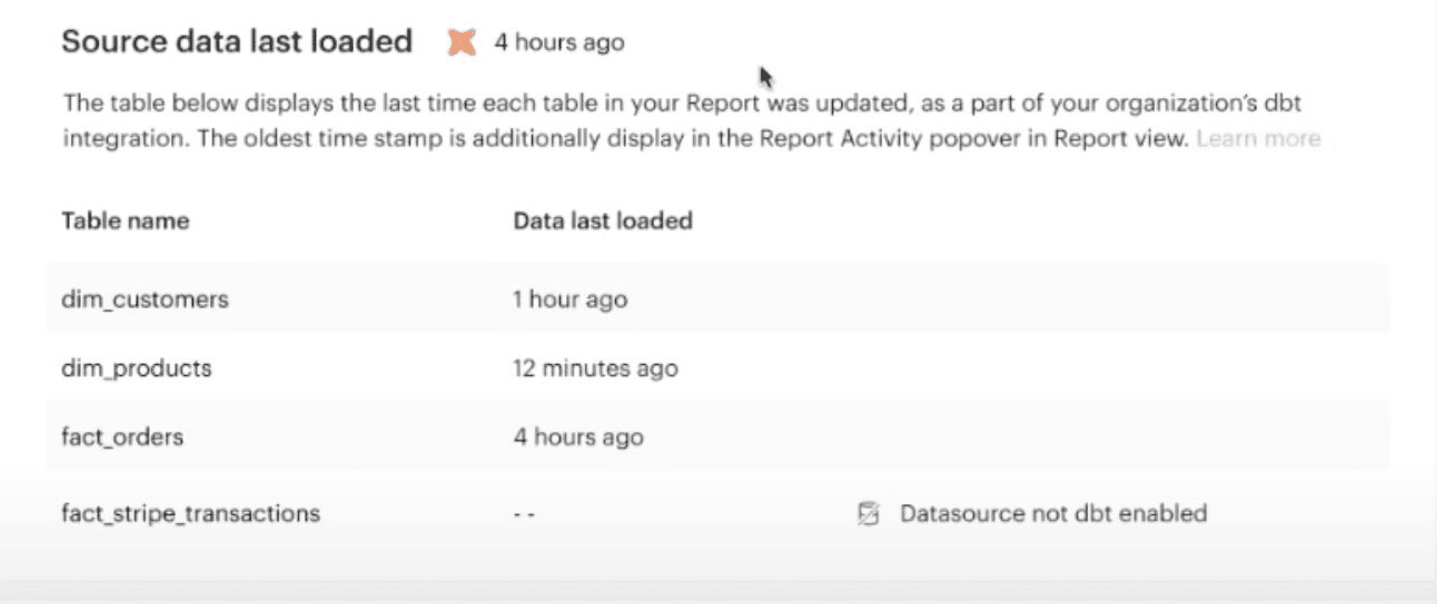
Exposure quality using iFrames
Even if your tool of choice doesn’t directly integrate with the dbt APIs, dbt Cloud embraces the ubiquity of iFrames to embed a rich “metadata tile” anywhere that supports it, including Looker (with some fiddling), Mode, Tableau, or totally unrelated products like a WordPress site. These tiles leverage exposures, a feature introduced in dbt 0.18.1, to define the places that models are accessed outside of dbt. They provide immediate inline confirmation that the source data is up to date and that all models involved are in a good state based on successful tests.
Pricing
dbt Cloud prices per Developer Seat. They also offer an Enterprise tier with features like Role Permissions.
Summary
The biggest benefit that dbt Cloud offers, especially to a small team, is freedom from distractions. Securely hosting documentation, or developing an orchestration strategy and a CI/CD pipeline are hard problems on their own. Instead, focus where you can add unique value making sense of your company's data.
dbt Cloud comes with a generous free tier for a single developer and if you're part of a larger team, developer seats for the are only $50/month. Enterprise options are available for more advanced configurations including SSO, single-tenant deployments, and more.
Is it perfect? Not yet. The IDE is still a bit clunky, and some workflows are slower than I'd like. The good news is that there's no lock-in when I need to do bulk operations like find-and-replace across files, I make the changes on a local copy of our project's repository and push it back to the cloud afterward.
Despite its warts, dbt Cloud is improving all the time and even in its imperfect state, I can absolutely say that it accelerates our day-to-day work. There's no way that my team could be as productive as we are if we first had to select and combine all the different cloud components that dbt Cloud abstracts away for us. The future is bright, but the present is also pretty amazing!

















