
Much of the developer world is familiar with the AWS outage in us-east-1 that occurred on October 20th due to a race condition bug inside a DNS management service. The backlog of events we needed to process from that outage on the 20th stretched our system to the limits, and so we decided to increase our headroom for event handling throughput. When we attempted that infrastructure upgrade on October 23rd, we ran into yet another race condition bug in Aurora RDS. This is the story of how we figured out it was an AWS bug (later confirmed by AWS) and what we learned.
Background
The Hightouch Events product enables organizations to gather and centralize user behavioral data such as page views, clicks, and purchases. Customers can setup syncs to load events into a cloud data warehouse for analytics or stream them directly to marketing, operational, and analytics tools to support real-time personalization use cases.
Here is the portion of Hightouch’s architecture dedicated to our events system:
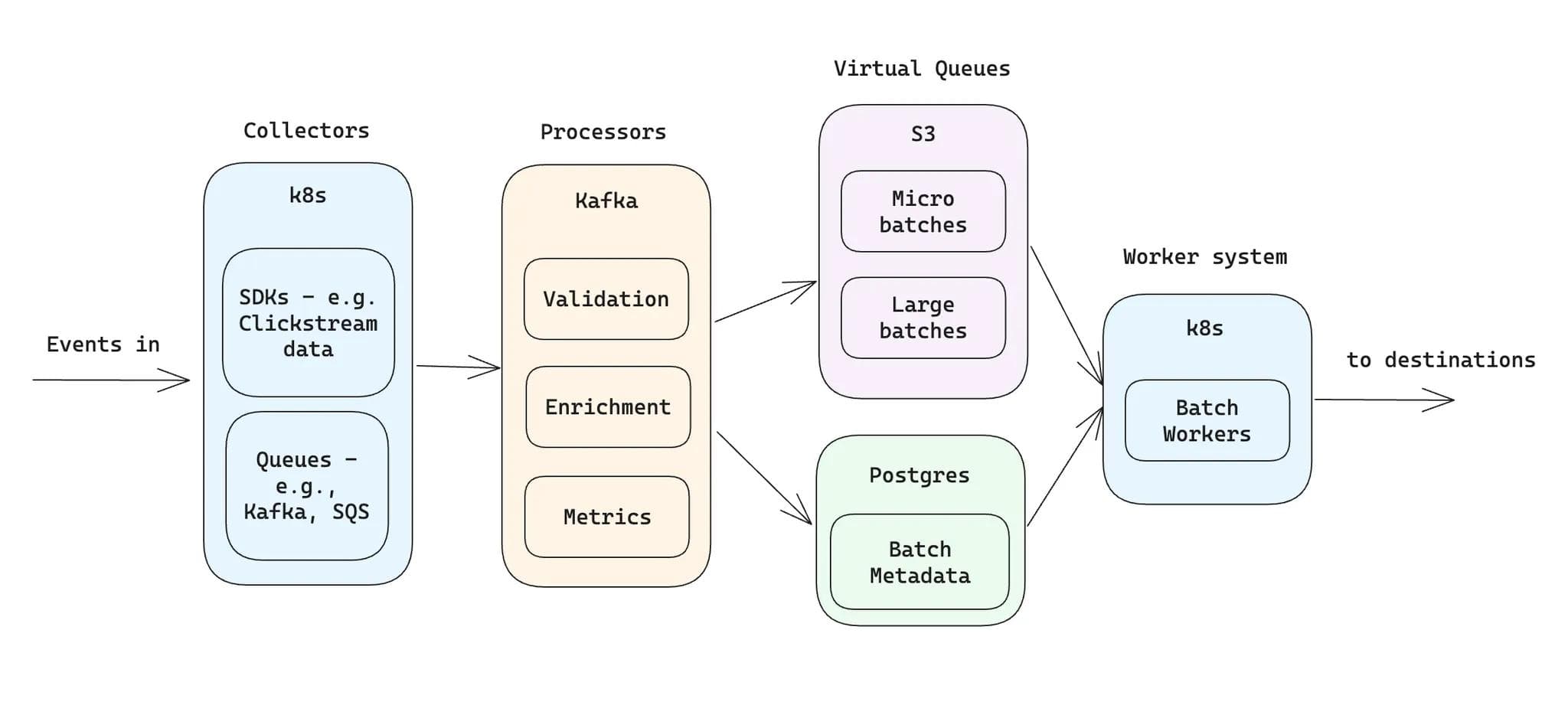
Hightouch events system architecture
Our system scales on three levers: Kubernetes clusters that contain event collectors and batch workers, Kafka for event processing, and Postgres as our virtual queue metadata store.
When our pagers went off during the AWS outage on the 20th, we observed:
- Services were unable to connect to Kafka brokers managed by AWS MSK.
- Services struggled to autoscale because we couldn’t provision new EC2 nodes.
- Customer functions for realtime data transformation were unavailable due to AWS STS errors, which caused our retry queues to balloon in size.
Kafka’s durability meant that no events were dropped once they were accepted by the collectors, but there was a massive backlog to process. Syncs with consistently high traffic or with enrichments that needed to call slower 3rd party services took longer to catch up and were testing the limits of our (small) Postgres instance’s ability to act as a queue for the batch metadata.
As an aside, at Hightouch, we start with Postgres where we can. Postgres queues serve our non-events architecture well at ~1M syncs/day and for events scaled to 500K events per second at ~1s end-to-end latency on a small Aurora instance.
After observing the events on the 20th, We wanted to upsize the DB to give us more headroom. Given that Aurora supports fast failovers for scaling up instances, we decided to proceed with an upgrade on Oct 23rd without a scheduled maintenance window.
AWS Aurora RDS
The central datastore for real-time streaming and warehouse delivery of customer events uses Amazon Aurora PostgreSQL.
Aurora's architecture differs from traditional PostgreSQL in a crucial way: it separates compute from storage. An Aurora cluster consists of:
- One primary writer instance that handles all write operations
- Multiple read replica instances that handle read-only queries
- A shared storage layer that all instances access, automatically replicated across multiple availability zones
This architecture enables fast failovers and efficient read scaling, but as we'd discover, it also introduces unique failure modes.
A failover is the process of promoting a read replica to become the new primary writer - typically done automatically when the primary fails, or manually triggered for maintenance operations like ours. When you trigger a failover in the AWS console:
- Aurora designates a read replica as the new primary
- The storage layer grants write privileges to the new primary
- The cluster endpoint points to the new writer
- The old primary becomes a read replica (if it's still healthy)
The diagram below explains how Hightouch Events uses Aurora.
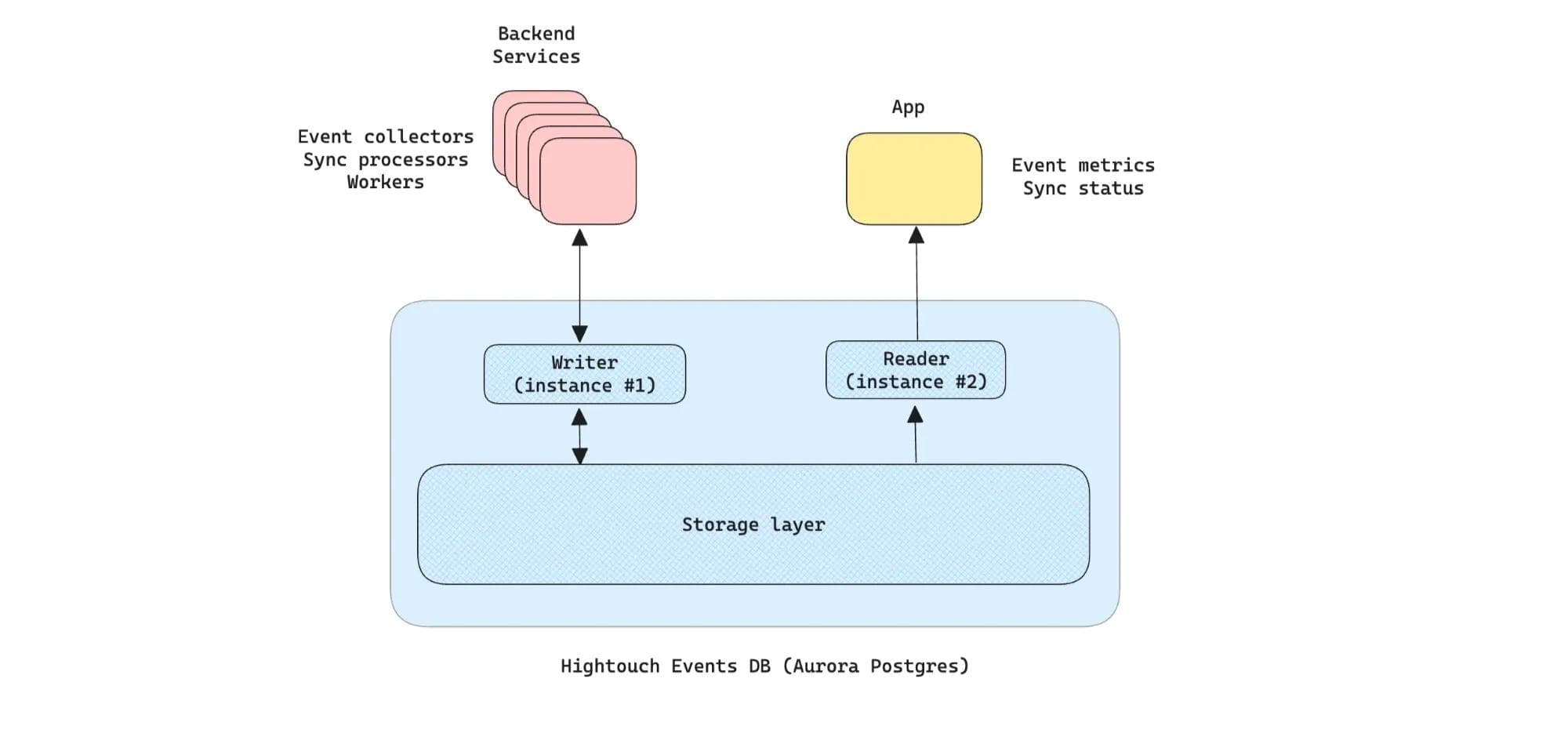
How Hightouch Events uses Aurora
The Plan
This was our upgrade plan:
- Add another read replica (instance #3) to maintain read capacity during the upgrade.
- Upgrade the existing reader (instance #2) to the target size and give it the highest failover priority.
- Trigger a failover to promote instance #2 as the new writer (expected downtime less than 15s, handled gracefully by our backend).
- Upgrade the old writer (instance #1) to match the size and make it a reader.
- Remove the temporary extra reader (instance #3).
The AWS docs supported this approach and we had already tested the process successfully in a staging environment while performing a load test, so we were confident in the correctness of the procedure.
The Upgrade Attempt
At 16:39 EDT on October 23, 2025, we triggered the failover to the newly-upgraded instance #2. The AWS Console showed the typical progression: parameter adjustments, instance restarts, the usual status updates.
Then the page refreshed. Instance #1 - the original writer was still the primary. The failover had reversed itself.
According to AWS everything was healthy. The cluster appeared healthy across the board. But our backend services couldn't execute write queries. Restarting the services cleared the errors and restored normal operation, but the upgrade had failed.
We tried again at 16:43. Same result: brief promotion followed by immediate reversal.
Two failed failovers in five minutes. Nothing else had changed - no code updates, no unusual queries, no traffic spikes. We had successfully tested this exact procedure in a staging environment under load earlier in the day. We checked our process to see if we had made any mistakes. We searched online to see if anyone else had encountered this issue but found nothing. Nothing obvious could explain why Aurora was refusing to complete the failover in this cluster. We were perplexed.
The Investigation
We first checked database metrics for anything unusual. There was a spike in connection count, network traffic, and commit throughput to the read replica (instance #2) during the failover.
The higher commit throughput could have been due to replication or the execution of write queries. The other two metrics simply indicated a higher query volume.
We checked the read query traffic from the app (graph below), and found that there was no change during this period. This told us the extra traffic to instance #2 came from our backend services which are supposed to connect to the writer instance.
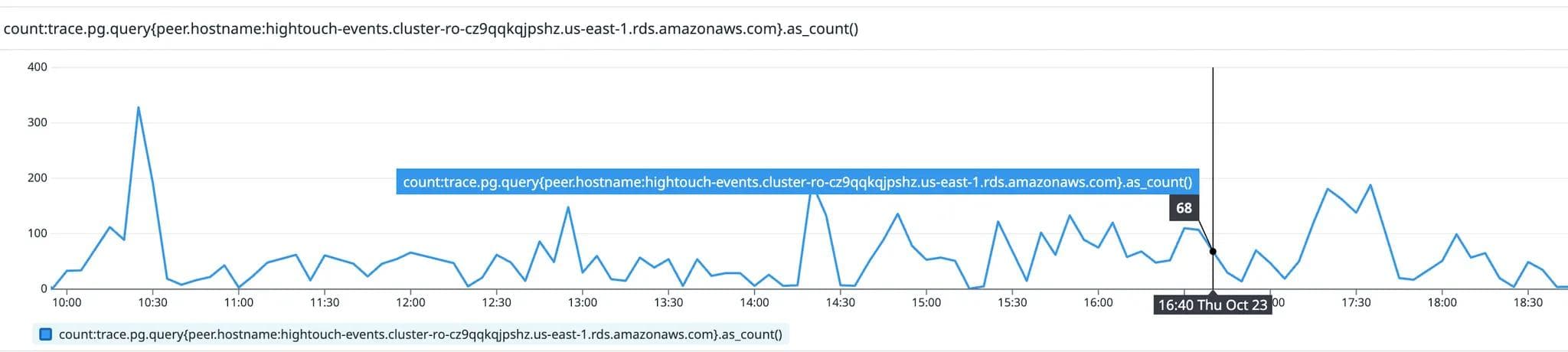
Query traffic from the Hightouch app
When we looked at the backend application logs, we found this error -DatabaseError: cannot execute UPDATE in a read-only transaction in some pods.
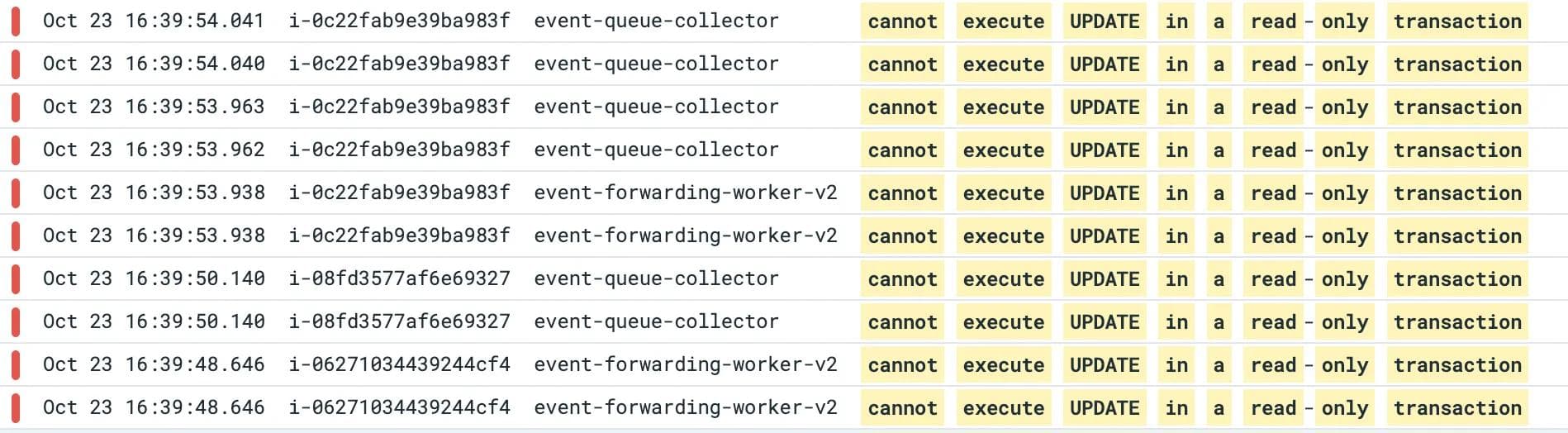
Backend application logs
Our services do not connect directly to the writer instance, but rather to a cluster endpoint which points to the writer. This could mean one of 3 things:
- The pods did not get the signal that the writer had changed - i.e. the cluster did not terminate the connection.
- The cluster endpoint incorrectly pointed to a reader instance.
- The pod was connected to the writer, but the write operation was rejected at runtime.
We did not find any evidence supporting or disproving #1 in the application logs. We had a strong suspicion it was either #2 or #3. We downloaded the database logs to take a closer look and found something interesting. In both the promoted reader and the original writer, we found the same sequence of logs:
2025-10-23 20:38:58 UTC::@:[569]:LOG: starting PostgreSQL...
...
...
...
LOG: database system is ready to accept connections
LOG: server process (PID 799) was terminated by signal 9: Killed
DETAIL: Failed process was running: <write query from backend application>
LOG: terminating any other active server processes
FATAL: Can't handle storage runtime process crash
LOG: database system is shut down
This led us to a hypothesis:
During the failover window, Aurora briefly allowed both instances to process writes. The distributed storage layer rejected the concurrent write operations, causing both instances to crash.
We expect Aurora’s failover orchestration to do something like this:
- Stop accepting new writes. Clients can expect connection errors until the failover completes.
- Finish processing in-flight write requests.
- Demote the writer and simultaneously promote the reader.
- Accept new write requests on the new writer.
There was clearly a race condition between steps 3 & 4.
Testing the Hypothesis
To validate the theory, we performed a controlled failover attempt. This time:
- We scaled down all services that write to the database
- We triggered the failover again
- We monitored for storage runtime crashes
By eliminating concurrent writes, the failover completed successfully. This strongly reinforced the race-condition hypothesis.
AWS Confirms the Root Cause
We escalated the findings and log patterns to AWS. After an internal review, AWS confirmed that:
The root cause was due to an internal signaling issue in the demotion process of the old writer, resulting in the writer being unchanged after the failover.
They also confirmed that there was nothing unique about our configuration or usage that would trigger the bug. The conditions that caused it were not under our control.
AWS has indicated a fix is on their roadmap, but as of now, the recommended mitigation aligns with our solution: use Aurora’s Failover feature on an as-needed basis and ensure that no writes are executed against the DB during the failover.
Final State
With the race condition understood and mitigated, we:
- Successfully upsized the cluster in
us-east-1 - Updated our internal playbooks to pause writers before an intentional failover
- Added monitoring to detect any unexpected writer role advertisement flips
Takeaways
The following principles were reinforced during this experience:
- Prepare for the worst in any migration - you could end up in your desired end state, beginning state, or an in-between state - even for services you trust. Ensuring you’re ready to redirect traffic and handle brief outages in dependencies will minimize downtime.
- The importance of good observability cannot be emphasized enough. The “brief writer advertisement” was only detectable because we were monitoring queries to each instance in Datadog and had access to database logs in RDS.
- For large scale distributed systems, isolating the impact any single component can have on the system can help both uptime and maintenance. It helps a lot if the design allows for such events without completely shutting down the system.
- Test setups are not always representative of production environments. Even though we practiced the upgrade process during a load test in a staging region, we could not reproduce the exact conditions that caused the race condition in Aurora. AWS confirmed that there was nothing specific about our traffic pattern that would trigger it.
If challenges like this investigation sound interesting, we encourage you to check out our careers page

















