
Reverse ETL opens up a world of use cases for your data and business teams to activate customer data by sending modeled insights directly into tools your teams rely on. We're continually inspired by our customers, who are solving new use cases with Hightouch every day, whether it be:
- Helping marketing teams deliver personalized lifecycle campaigns
- Powering customer success tools with product usage data
- Putting upsell and churn risks directly in the hands of sales teams
But this post covers a specific use case emerging for Product Teams: syncing data from the warehouse into databases (not SaaS tools! 🤯) to power personalized, in-app product experiences.
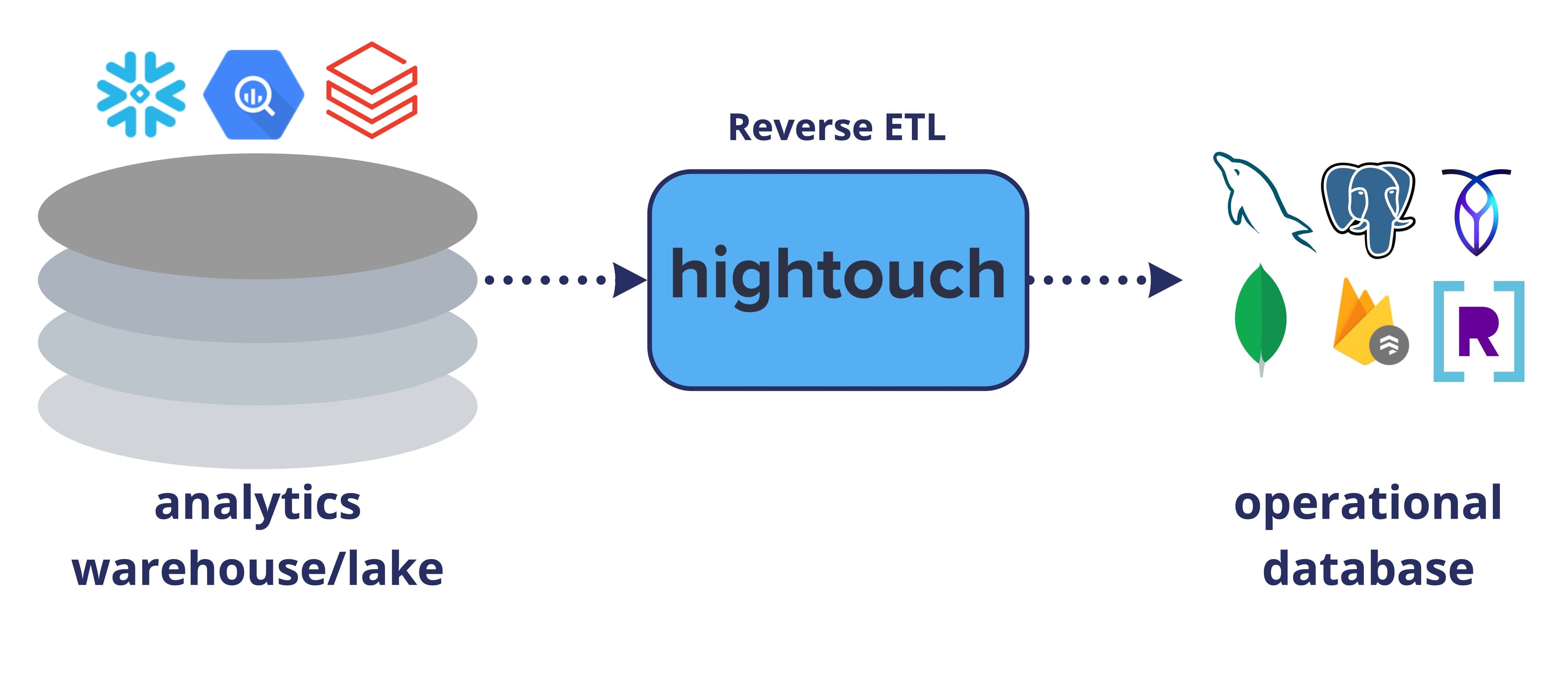
Sync warehouse data to application databases with Reverse ETL
Complex Analytics, Delivered Exactly Where You Need It for Real-time Action
Data warehouses like Redshift, Snowflake, and BigQuery (also called "online analytical processing" or OLAP systems) are designed to process complex analytical queries across a lot of data. They're built to query massive data sets and can perform complex calculations to help answer questions like: "What are the key actions that lead to conversion, using all historical purchase behavior across all our customers?" They provide immense analytical power, but they're not suited to return a single row of data to power real-time product experiences.
On the other hand, application databases like MongoDB, MySQL, and Postgres (also referred to as "online transactional processing" or OLTP systems), are purpose-built to read and write small amounts of data very quickly. For example: "Give me the information you have on Customer ID 3418, fast!" These systems are optimized to handle many small transactions with extremely low latency to power the real-time experiences we all expect from an online application.
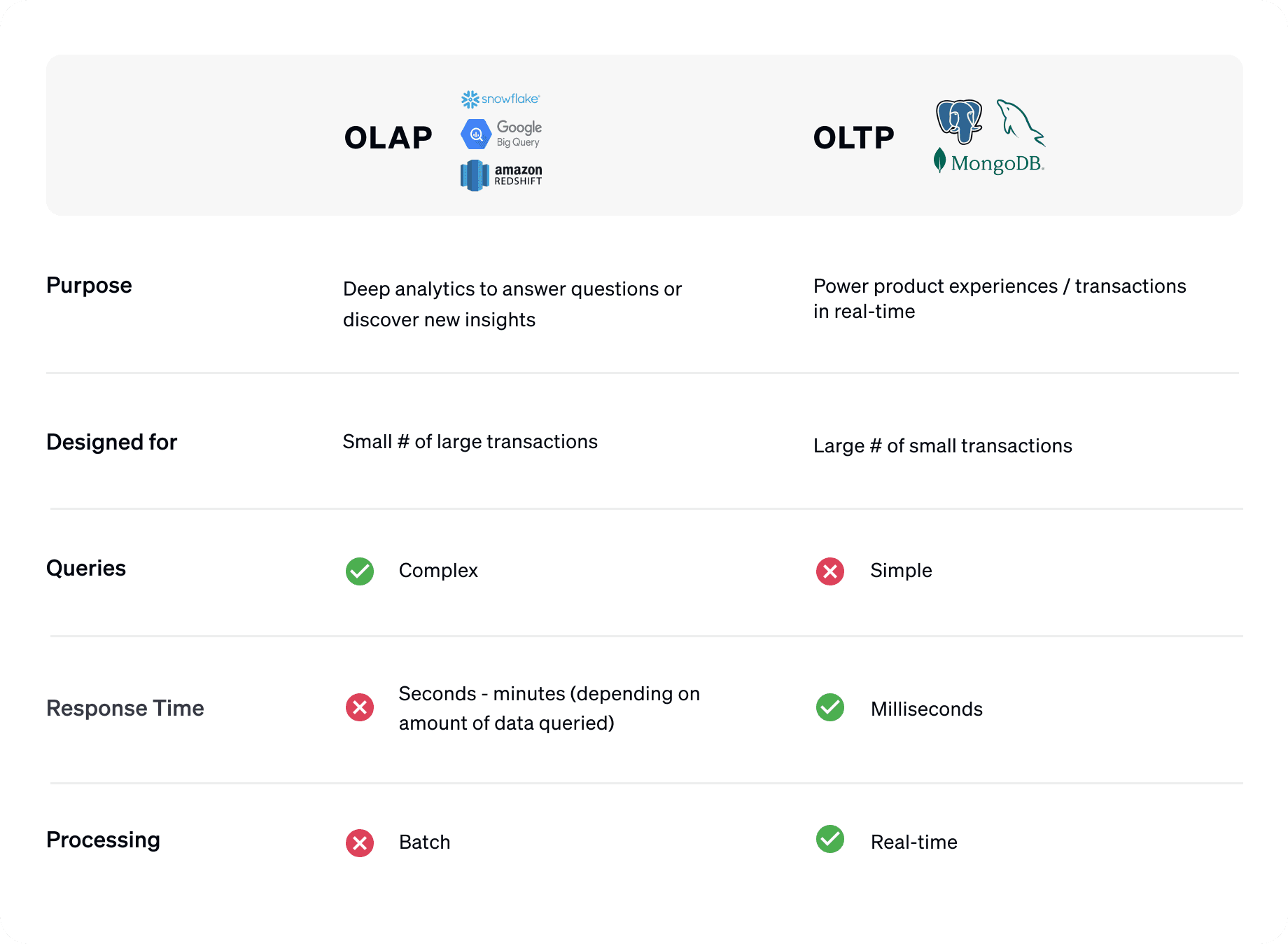
OLAP vs. OLTP
Using Hightouch to sync analytical data into your application databases, you can get the best of both and deliver complex analytics in real-time exactly where you need it.
Going way back to a time before SaaS tools even existed 👵, ETL was almost exclusively used to replicate application databases (OLTP) to analytical databases (OLAP) to segregate production workloads from reporting workloads. Production application databases are not built for complex reporting queries—they can slow down the actual product experience for your end users and take forever—so you need to replicate your data to an OLAP system designed for analytics. Here's a very basic diagram of ETL (before SaaS was even a thing):
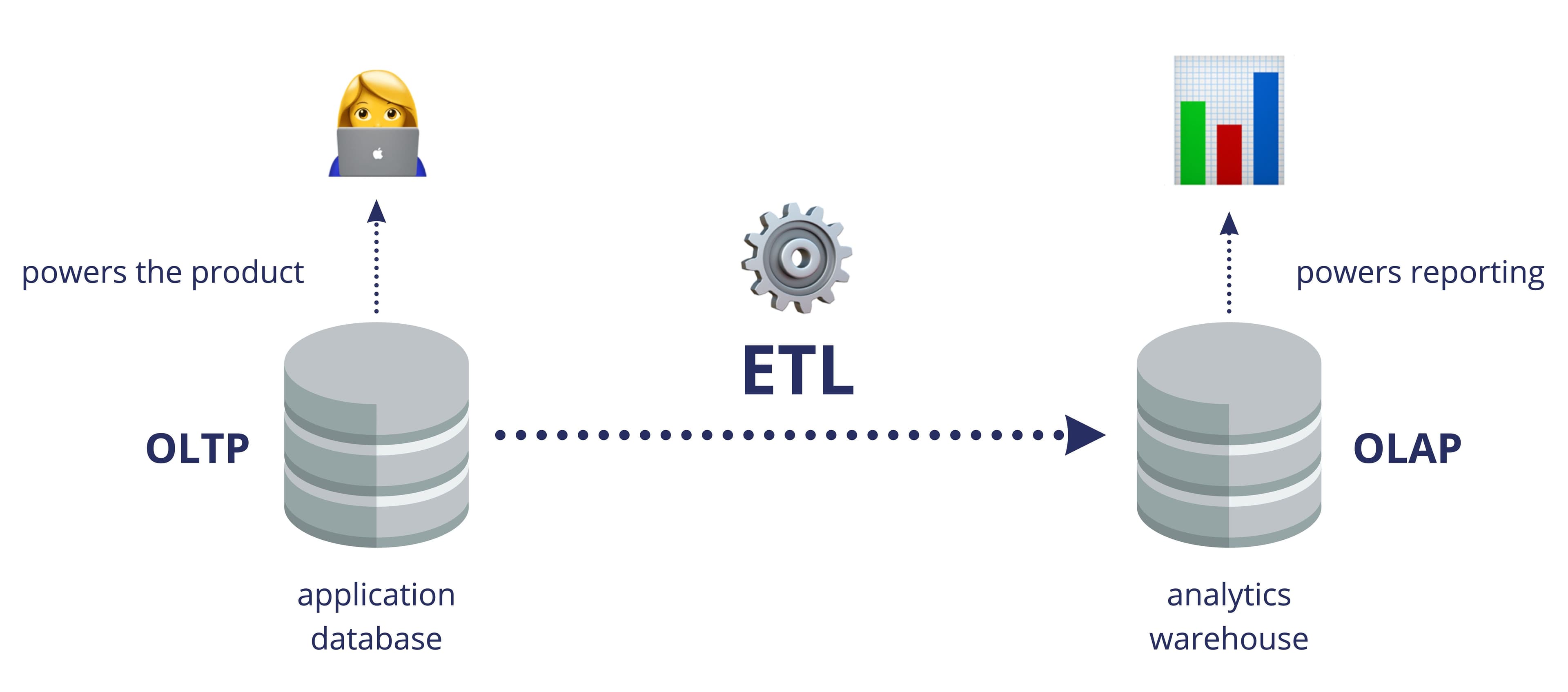
ETL diagram
In that sense, taking your warehouse data and syncing it back out to your application databases is probably the most fundamental example of "Reverse ETL" we can imagine:

Reverse ETL diagram
Of course, we understand all of the above can be classified as "ETL", but 90% of the time when data teams say "ETL", they're referring to replicating data into the warehouse (often via fantastic data integration tools like Fivetran). We use "Reverse ETL" to make it clear that we're doing the opposite.
You may be asking yourself: "Why would I do this? When is it useful to copy warehouse data back into my application databases?" Let's dive into some fun use cases.
Use Case #1: Onsite Personalization
Many companies are pushing user-level recommendations or predictions back to low latency databases to power in-app product personalization. We do this at Hightouch to calculate customer-specific billing usage in our Snowflake instance and then sync info from Snowflake to → Postgres (via Hightouch) to power personalized in-app banners that inform users when they’ve exceeded their plan limits.
In case you missed it, we wrote a post about how we're using Hightouch at Hightouch to power in-app banners and feature flags with our own Snowflake → Postgres syncs here.
Another example is how a media publisher uses Hightouch to sync predictions from the warehouse about suggested interest categories (e.g., Garden Lovers). Their product team can then promote these categories to relevant users based on their behavior. The process looks like this:
- Compute user-level recommendations in the warehouse
- Use Hightouch to sync these definitions back into MySQL regularly
- Insights are now available in MySQL to offer relevant suggestions for each user
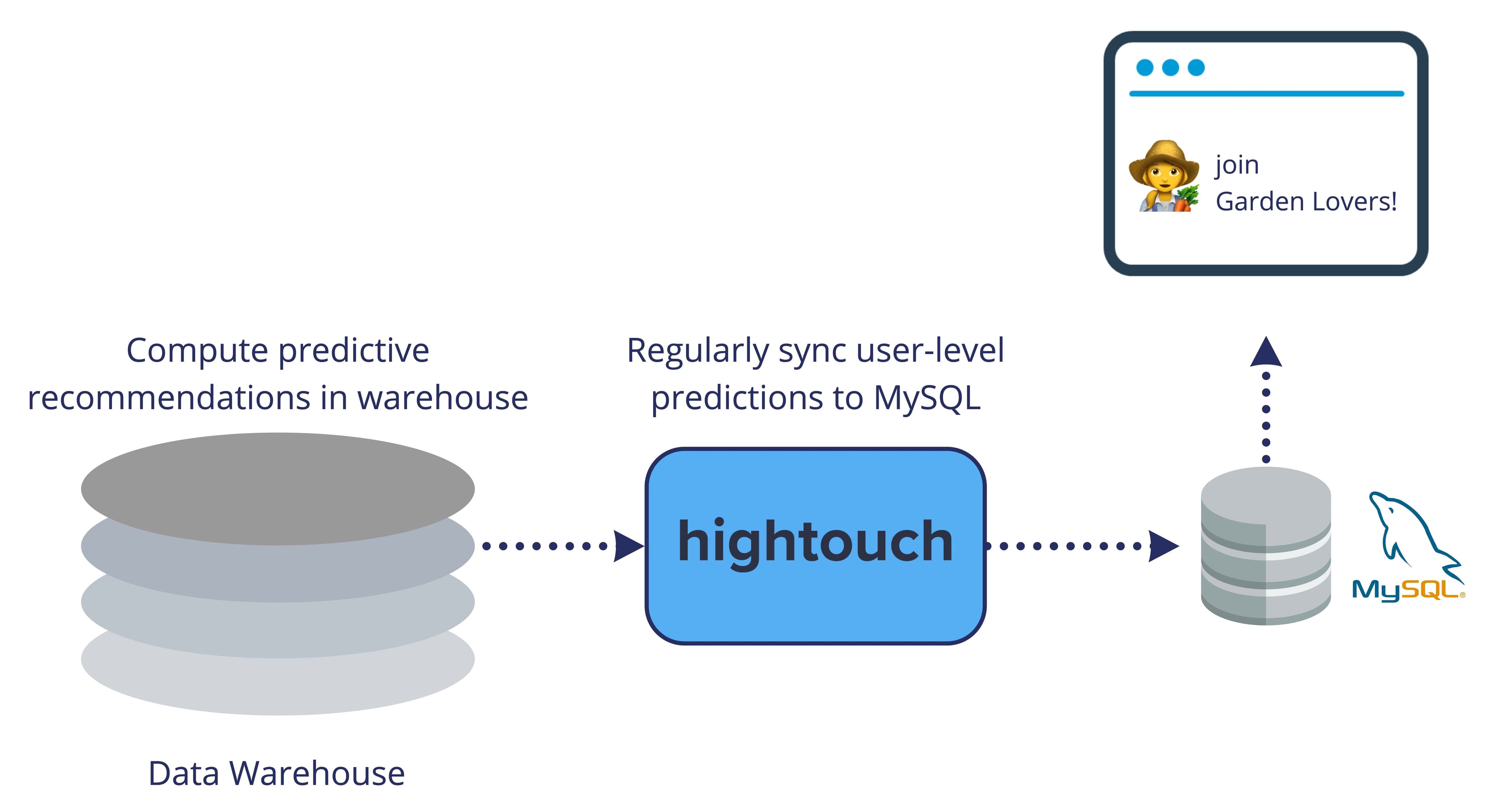
In-app personalization via Reverse ETL
It's easy to build and iterate on this architecture with little engineering overhead since the computed insights are landing in the very same OLTP database that the app is already built on.
It's worth stating that many SaaS vendors in the CDP space try to suggest they can power onsite personalization via their own "profile API" that allows you to fetch user info programmatically (see Segment, mParticle, Tealium, and Amplitude, for example). This strategy is hard to take seriously for several key reasons:
- It would require your product engineers to build bespoke requests to the external API, involving a server-side proxy in the middle to ensure it's secure, and this requires significant engineering resourcing.
- The API latency will be far slower than an in-house database, often failing to return data in less than 200ms.
- Your user-level recommendations probably originate from core definitions your data teams have built in the warehouse, so you'd need to find some way to first "import" these into a CDP, which means you may end up using Hightouch for this anyways.
- CDPs charge a significant premium to cache everything on each user for this retrieval.
- You’d have a core app experience dependent on another vendor’s uptime. If your CDP goes down, so too does your app, and there’s nothing you can do about it.
Instead, use your own database! Doing so allows you to control exactly what data is passed back (directly into the database your app is familiar with). It provides much lower latency at a lower price, requires far less engineering, and is more flexible and secure since your data is never stored outside your own infrastructure. It's a no-brainer 🧠!
Use Case #2: In-product Analytics and Embedded Dashboards
Many applications include reporting visualization features. If your underlying data is somewhat complex, it’s useful to do the actual aggregations and number-crunching in your analytics warehouse, but then send the results to your application database to power snappy visualization experiences. For example, one of our customers is a social media scheduler for content creators and has adopted this use case to publish in-app dashboards for their users.
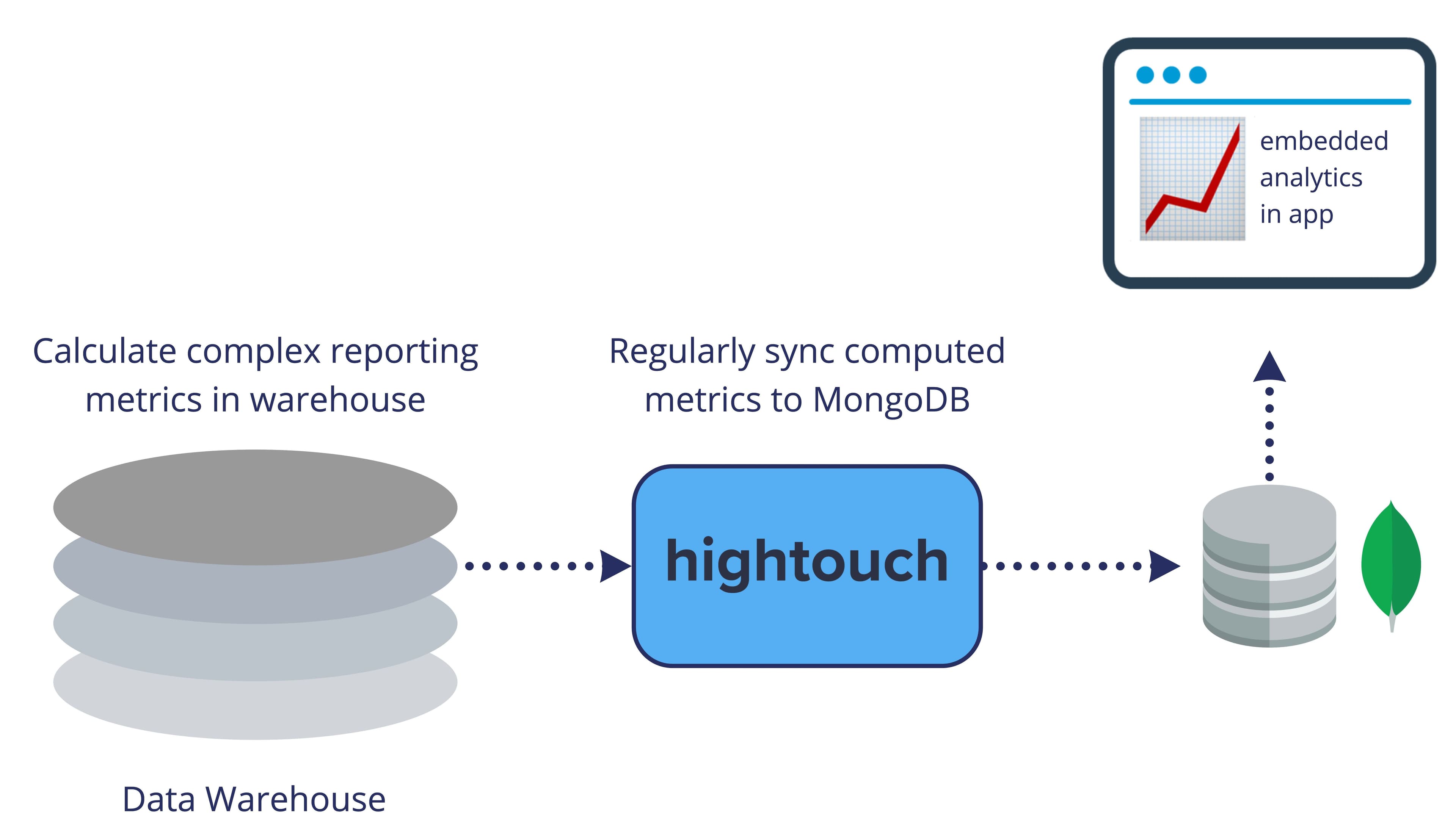
Embedded analytics via Reverse ETL
They sync modeled data from their warehouse to MongoDB (their application database) every hour. Their app reads from MongoDB to then serve users with updated engagement dashboards upon login. Querying the warehouse would take far too long, so this solution provides the same insights but comes with the real-time performance of their application database. One of our customers got pretty excited about this use case:
Making the call to start use @HightouchData was one of the best decisions our team has made. They literally built a MongoDB integration just for us within a couple of days. Used it to rapidly put together a data product and this is the reception I got after sharing the news. pic.twitter.com/PXwGe5LTFu
— Michael Erasmus (@michael_erasmus) November 2, 2021
Use Case #3: Powering Internal Applications
Rather than using third-party SaaS tools, large organizations will often choose to build an in-house CRM, in-house marketing tool, or any other application. These tools will run off of some application database (not a warehouse). Still, it's very helpful to pump your modeled data or aggregations computed within your warehouse into an application database. For example, one of our FinTech customers has built a CRM in-house that runs off a Postgres database. They hydrate this tool modeled data from their warehouse, including contact-level information, computed attributes, and custom audiences for marketing.
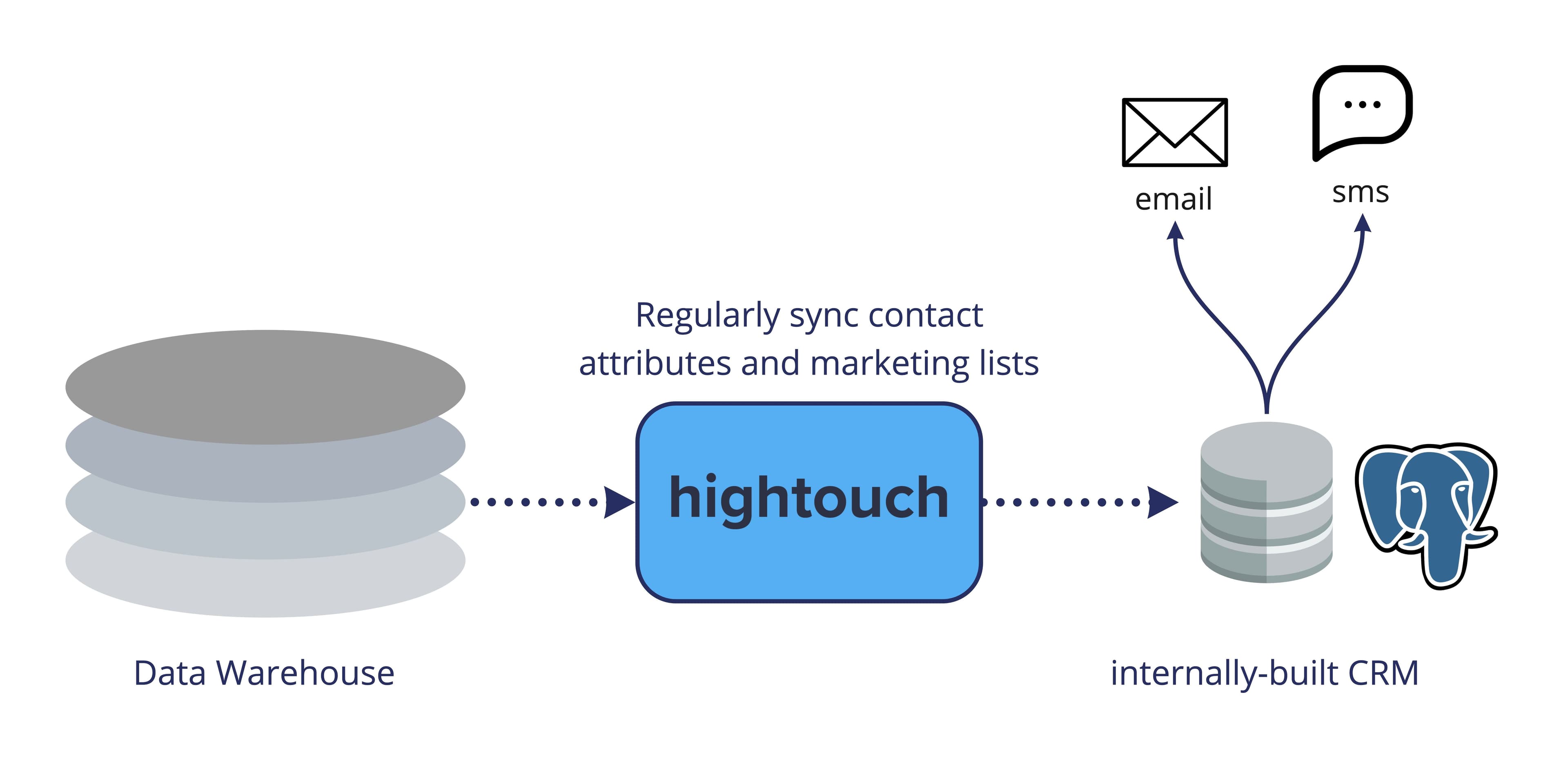
Powering home-grown apps via Reverse ETL
Why Do I Need Hightouch to Do This?
The truth is, you don't. You can build your own internal ETL tooling to move data from your warehouse to your application databases. However, many organizations are opting to "buy" vs. "build" for these pipelines because building in-house takes time - time to build, time to maintain, and time to iterate for any new use case or data field.
Custom pipelines also require deep knowledge of the intricacies of database systems (e.g., the same reason companies solicit help from Fivetran/HVR for traditional ELT jobs). You can stand up a pipeline with Hightouch in about 15 minutes, which also natively includes automatic incremental syncing, infinite scalability, market-leading observability and auditing, version control via Git, proactive and custom alerting, and integrations with the modern data stack that make Hightouch the fastest and most reliable way to activate your customer data.
This can also be a very effective way to bridge gaps between product and data teams. The reality is that often product engineering teams will spin up an application database, load it with data from scratch, and then maintain that database themselves. They rarely, if ever, build regular pipelines from the warehouse to hydrate their application database, and as a result they miss out on opportunities to collaborate and drive value from their company’s data analytics investments.
Today, Hightouch supports syncing data to popular application databases such as CockroachDB, Firestore, MongoDB, MySQL, and PostgreSQL. We're planning to expand this catalog rapidly over the coming quarter (and will prioritize our roadmap based on customer demand), so please feel free to request any destination you're looking for within our catalog!
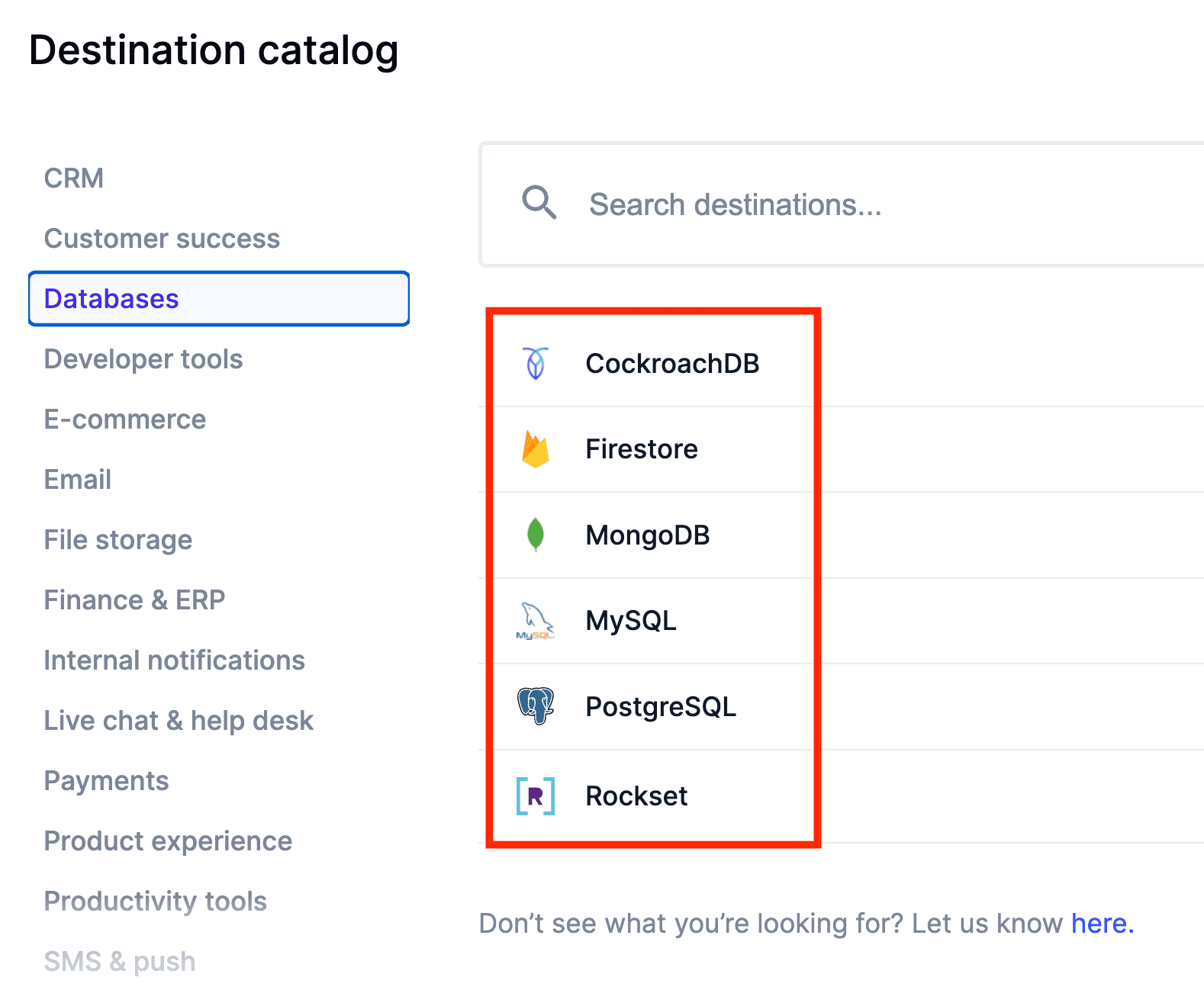
Databases as destinations in Hightouch catalog
Next Steps
We'd love to hear about the use cases you're solving by syncing your warehouse data to your application databases. Please shoot me an email at andrewjesien@hightouch.com to chat. Check out our full integration catalog to see the 300+ destinations we sync data to, and if you're not using Hightouch yet, you can request a demo or sign up for a free account here.

















