
Many of today’s biggest SaaS businesses have jumped on the product-led growth (PLG) bandwagon. By leveraging the product as a first-class go-to-market channel, companies can grow more efficiently. Sales cycles become shorter and acquisition costs begin to flatten.
Yet, there’s a perception that only large teams with big budgets can build PLG motions at scale, (e.g. Dropbox, Slack, Airtable), and that growth engineers need to write thousands of lines of code over multiple months just to execute simple experiments.
The modern data stack—exemplified by vendors like Snowflake, Fivetran, and dbt—has promised an alternative. By replacing application code with SQL queries and models, a business can build a high-caliber PLG engine…without outsized resources.
Making this transition does require changing the mental model of how the system should be architected, but our own journey at Hightouch shows that the payback can be tremendous.
It’s still early, but the results and velocity have been exciting. In writing this post, our goal is to engage with and learn from others who are driving similar innovations in PLG.
Building a PLG Engine on the Warehouse
As a PLG business ourselves, we’re always excited to push the envelope of what’s possible. Over the past two months, we migrated our entire PLG engine directly on top of our data warehouse (🤩).
We went beyond a simple implementation like “syncing data fields into Salesforce” and instead prioritized migrating key components of our business logic directly into our warehouse so we could focus on higher-level objectives like audience building, workflow sequencing, customer journeys, and experimentation.
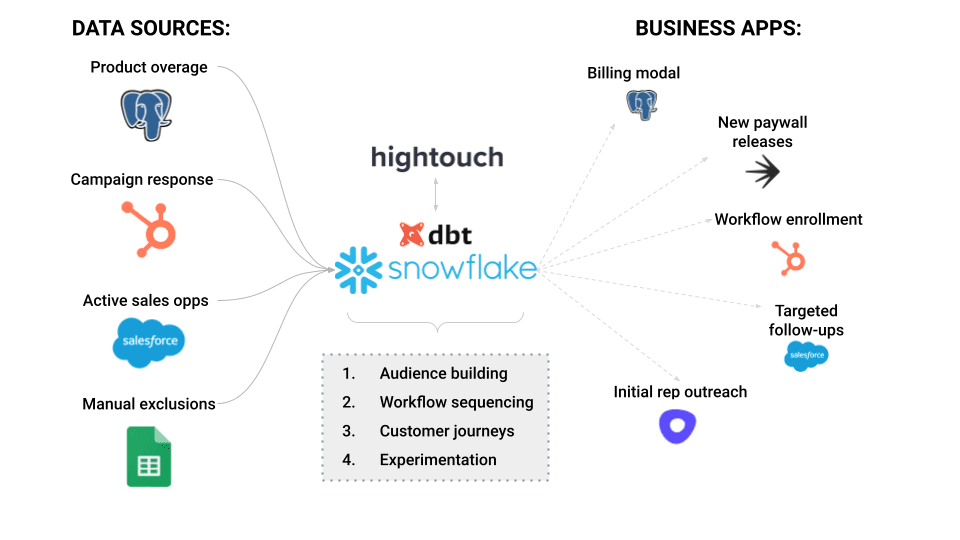
How We Do PLG at Hightouch
Our high-level implementation was standard. From a source perspective, we were interested in several classes of data, all loaded into Snowflake with Fivetran:
- Product usage: Our production database records plan entitlements. Our primary use case here is to target workspaces that are in overage (these are workspaces that have exceeded the usage allotted in their tier).
- Campaign response: We use Hubspot for transactional emails. These emails notify users of escalations, and Hubspot helps capture valuable response data.
- Active sales opps: Our SFDC instance records open sales opportunities. In our marketing campaigns, we want to exclude workspaces tied to active sales conversations.
- Manual exclusions: Our team maintains a list of workspaces in Google Sheets to exclude from our upsell campaigns and we want to account for these exclusions.
We also wanted to use this data to drive various user-facing affordances. We drink our own champagne, as they say, and use Hightouch to trigger these workflows in end systems.
- In-app banners: built directly in our production database (Postgres)
- Paywalls: controlled via LaunchDarkly (we rolled out different types of product behaviors)
- Campaigns: run through Hubspot Workflows/Campaigns
- Targeted follow-ups: implemented as a report for SDRs in Salesforce
- Initial rep outreach: automated through tasks in Outreach
Create 360° User Profiles in your Warehouse
Learn how to stitch your existing customer data into rich, actionable profiles directly in your data warehouse without writing a line of code.
Download this document to learn more about Hightouch's Adaptive Identity Resolution and how warehouse-native identity and entity resolution empowers companies with the best-possible uses for their data.

Our PLG Use Cases
With this migration, we were able to transition logic that otherwise would have lived in different systems—via static lists, workflow graphs, custom field logic and dynamic filters—and move it into dbt models and Hightouch syncs. There are several key components we’d like to call out.
Audience Building via Filters
We implemented audiences directly via dbt as nested models with incremental filters. The broadest audience (self-serve workspaces in overage) is sent to in-app affordances. Then a subset of this audience (workspaces with no active sales engagement) is sent to Hubspot for marketing automation. Finally, a more granular subset (workspaces with high usage) is sent to Salesforce for SDR outreach.
This nested hierarchy not only makes the process easily traceable but also means that our different systems operate off the same data. If anything changes, we don’t have to worry about propagating it in multiple places. The traditional alternative meant we’d have to update reports in Salesforce and workflow rules in Hubspot, which introduces the risk of human error and takes a lot longer.
Workflow Sequence via Timestamp Fields
The hardest part of this shift has been sequencing: making sure different steps in different systems are taken in the right order and with the desired time delay. Marketing and sales automation tools do a great job via their core sequences products, but it’s very hard to coordinate sequences across systems. For example, we want our SDR team to reach out three days after our initial marketing outreach and immediately when our marketing sequence ends if admins haven’t responded. We want in-app notifications to follow a similar logic.
We solved this problem by time stamping every key event, and then using these timestamps to create audiences. We have a field that counts the number of days since the initial automated billing email was sent and that triggers the next step in the workflow. This sophisticated automation is possible purely because we can create custom columns in our own warehouse tables without polluting SFDC (similar to how you can create a custom column in Google Sheets).
Customer Journeys via Status Fields
Another challenge we faced was tracking the status of users and workspaces across their entire journey (e.g. campaign membership). A myriad of events could theoretically enroll or un-enroll users as members in our campaigns across systems. For example, if a user asks for an extension on their account we might want to pause the lockout modal from our in-app process. Depending on the use case, this can be non-linear or cross-object and that adds complexity.
To solve this, we created several status fields on our users table. We created one for our sales and marketing flows and another for product flows (both had custom stages). We calculate stages using a series of CASE statements based on engagement data that is loaded into Snowflake. We also use the built-in DAG function within dbt to ensure eventual consistency whenever the engagement data causes a state of a certain field to change.
Experimentation via Cohort Fields
We knew we didn’t want to roll out every experiment to our entire user base. Instead, we preferred a phased roll-out with proper A/B testing. In the old architecture, we’d have to do this manually in Google Sheets and create individual cohorts. With our warehouse implementation, we can create a field that generates cohorts automatically for us, simply by using a random number generator.
Best of all, since this is all happening automatically in the warehouse, we can plug our BI reporting tool directly on top of the data and immediately track how our experiments are performing. Because we also record the customer journey and time stamps in our warehouse, snapshotting and time series analysis are also possible.
What About System Performance?
One common concern when building on top of the data warehouse, as compared to event-based frameworks, is latency. Data needs to move from systems, into the warehouse, and then back out, adding an additional hop. This becomes especially problematic if the wrong affordance is displayed to your end user.
For our implementation, we haven’t found latency to be an issue. Using our Dagster integration, we’re able to sync data from Salesforce, Hubspot, and Postgres into the warehouse, run a series of dbt jobs, and then kick off Hightouch syncs with a cycle time of 15 to 25 minutes.
For any in-app affordances, we’ve decoupled the business logic for whether a workspace is in overage from the affordances that ask users to upgrade. The business logic for overages runs off our production Postgres, so it bypasses the lag.
For automated campaigns in Hubspot, we’ve found that the 15 to 25-minute time lag is more than enough to manage workflow enrollment upon changes in product settings. We’ve scheduled our Dagster workflow to trigger one hour before our Hubspot workflows execute, which practically eliminates the risk of errors.
Warehouse Centricity (For the Win)
There were several promises of a warehouse-centric approach that were attractive to us. At a meta-level, it’s the reason we believe so wholeheartedly in the potential of Reverse ETL: the warehouse is a treasure trove of actionable customer data.
-
Cross-system coordination: It’s much easier to join tables from different systems using SQL inside a warehouse environment than by building point-to-point integrations. Reconciling different object types is more straightforward (e.g., accounts in the CRM and organizations in the production database). The same is true for managing complex hierarchies. Even a common use case like combining engagement tables in Hubspot with account history tables in Salesforce is frustrating outside the warehouse. Most CRMs also don’t have first-class support for processing product event feeds, which is common in PLG.
-
Traceability & manageability: Outside the warehouse, the data you need is often scattered across multiple systems making it difficult to connect the dots. Logic is implemented in different interfaces: static lists, workflow graphs, field logic, dynamic filters, and more. While the modern data stack won’t fully solve this challenge, it does help encapsulate all of this complexity into simple constructs: SQL, models, and composable views that can be version-controlled, organized, searchable, and traceable.
-
Velocity: Moving business logic to the warehouse means a wider set of users (e.g. technically-minded operators or business-minded analysts) now have the tools to iterate quickly. It also means business logic is decoupled from user affordances (marketing copy, in-app messaging, etc.). Business teams are given the flexibility to experiment and engage users without requiring engineering resources.
-
Live Reporting: Because audiences are defined in the warehouse, it's easy to generate incredibly powerful funnel conversion reporting—something that would not be possible with traditional tools. For example, this approach lets us track in-app activity for users that were included in a Hubspot campaign simply by joining our audience table with our site tracks table. This provides a real-time, full-funnel view of how our campaigns are performing.
What’s next
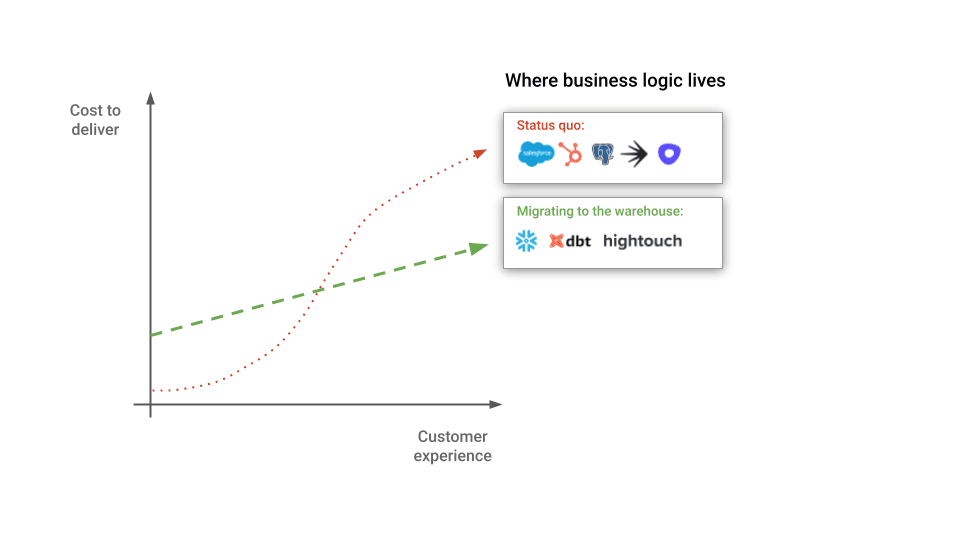
Cost to Deliver vs. Customer Experience
We are two months into our warehouse-first approach and are incredibly excited about our early outcomes and the unlimited potential for what we can build. Fundamentally, moving onto the modern data stack has allowed us to level up our customer experience, and we've been able to do that with significantly lower operational overhead.
Building nuance into the system was simply a matter of creating some more fields in a live pipeline, instead of complex changes that needed to be coordinated across multiple disparate systems. We’ve also learned a ton about how using Hightouch on top of dbt can power this motion.
We’d love to hear about how you’re approaching PLG in a warehouse-centric world. Shoot me an email at john@hightouch.com so we can chat! We plan to continue to document our journey on our blog so stay tuned. In the meantime, you can signup for a free Hightouch account here.
Create 360° User Profiles in your Warehouse
Learn how to stitch your existing customer data into rich, actionable profiles directly in your data warehouse without writing a line of code.
Download this document to learn more about Hightouch's Adaptive Identity Resolution and how warehouse-native identity and entity resolution empowers companies with the best-possible uses for their data.

















