
We’ve been talking to many marketers recently who’ve heard that Salesforce Data Cloud can use data from the data warehouse with “zero-copy.” Zero-copy is a great name for a feature and a great promise—it implies that marketers can access and use all of their data (from the data warehouse where their companies store it) without creating expensive and risk-inducing copies.
Unfortunately, this is yet another example of Salesforce overpromising and underdelivering. Salesforce’s zero-copy has fatal flaws that further compound the many shortcomings of Salesforce Data Cloud.

We’ve spent hundreds of hours talking to customers and reading through every piece of Salesforce’s (opaque) documentation - so you don’t have to. We have three goals in this blog:
- Share what we’ve learned about zero-copy
- Hopefully help you avoid a painful implementation with Salesforce Data Cloud
- Suggest better ways that you can actually use your company data without copying it.
Salesforce Zero-Copy Doesn’t Work as Advertised
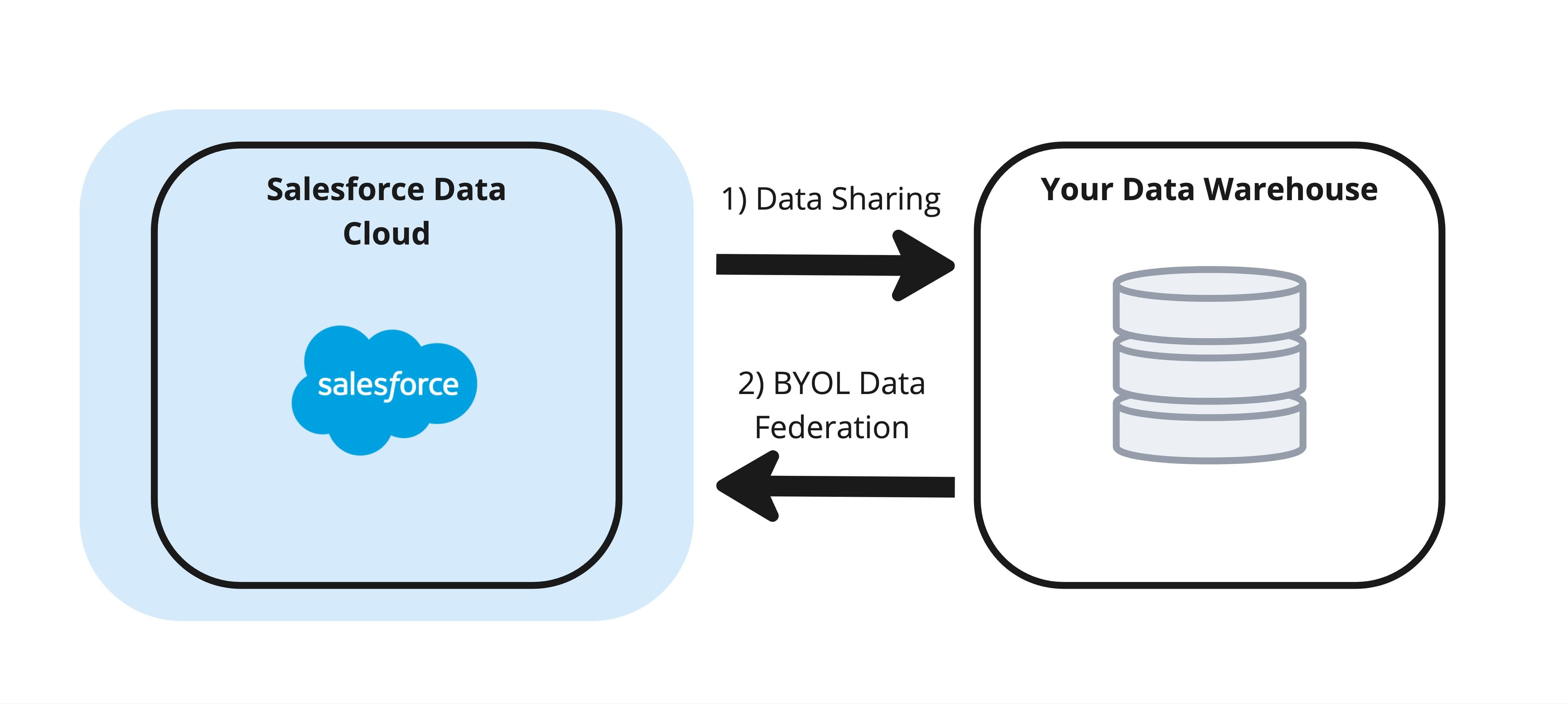
First and foremost, it’s essential to understand that there are two directions to consider when discussing “zero-copy”:
- Salesforce Data Cloud → Your Warehouse, via data sharing
- Your Warehouse → Salesforce Data Cloud, via BYOL data federation
Salesforce conflates these concepts under the broad umbrella of “zero-copy,” but the technology that powers each is fundamentally different.
Salesforce Data Cloud → Warehouse: This feature uses warehouse-native data-sharing capabilities. It allows data teams to access Salesforce data directly within their own warehouse instance for analytics and BI.
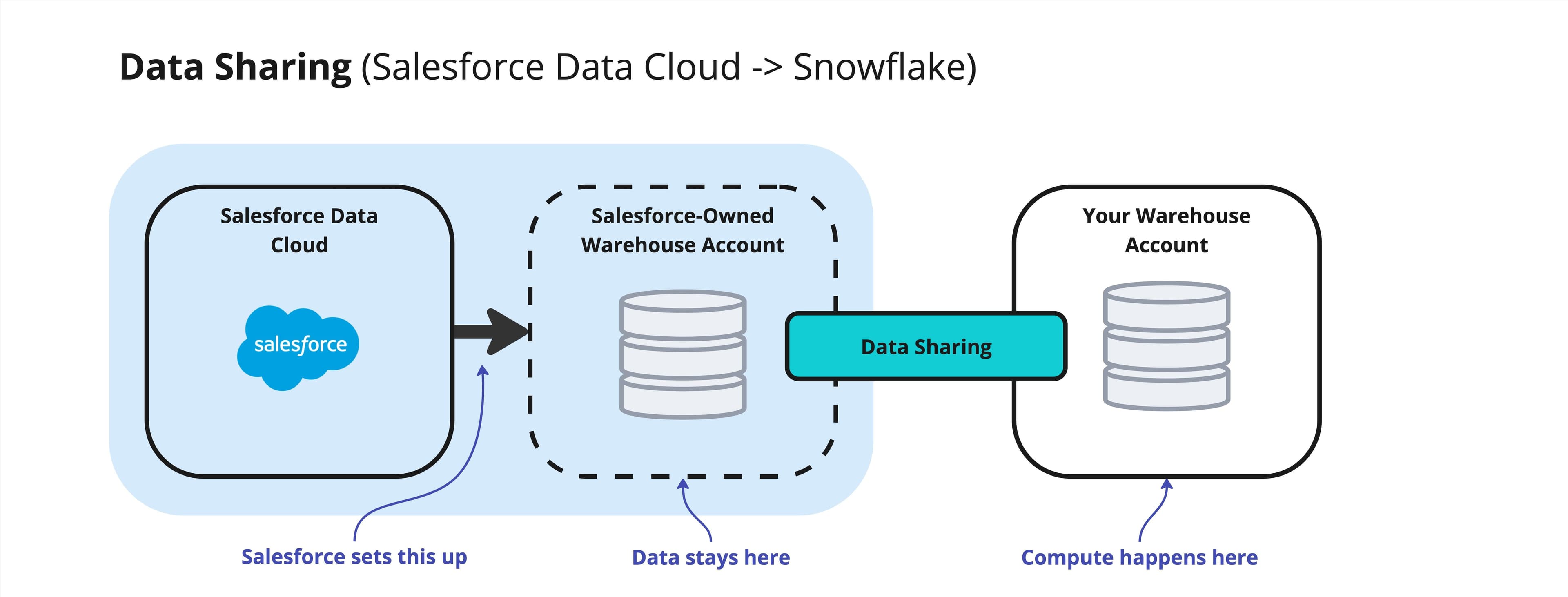
This functionality works well! Salesforce stores data in a warehouse instance that they manage, which you can then access via a data share to create virtual tables inside your owned warehouse instance. You get to use this data without storing it in your own instance. This process is relatively simple and straightforward to set up.
Warehouse → Salesforce Data Cloud: This direction is much more confusing and poorly documented. Salesforce calls this technology Bring-Your-Own-Lake (BYOL) data federation. It is supposed to make data warehouse data accessible inside Salesforce Data Cloud so marketers can build audiences and act on their warehouse data, without copying it.
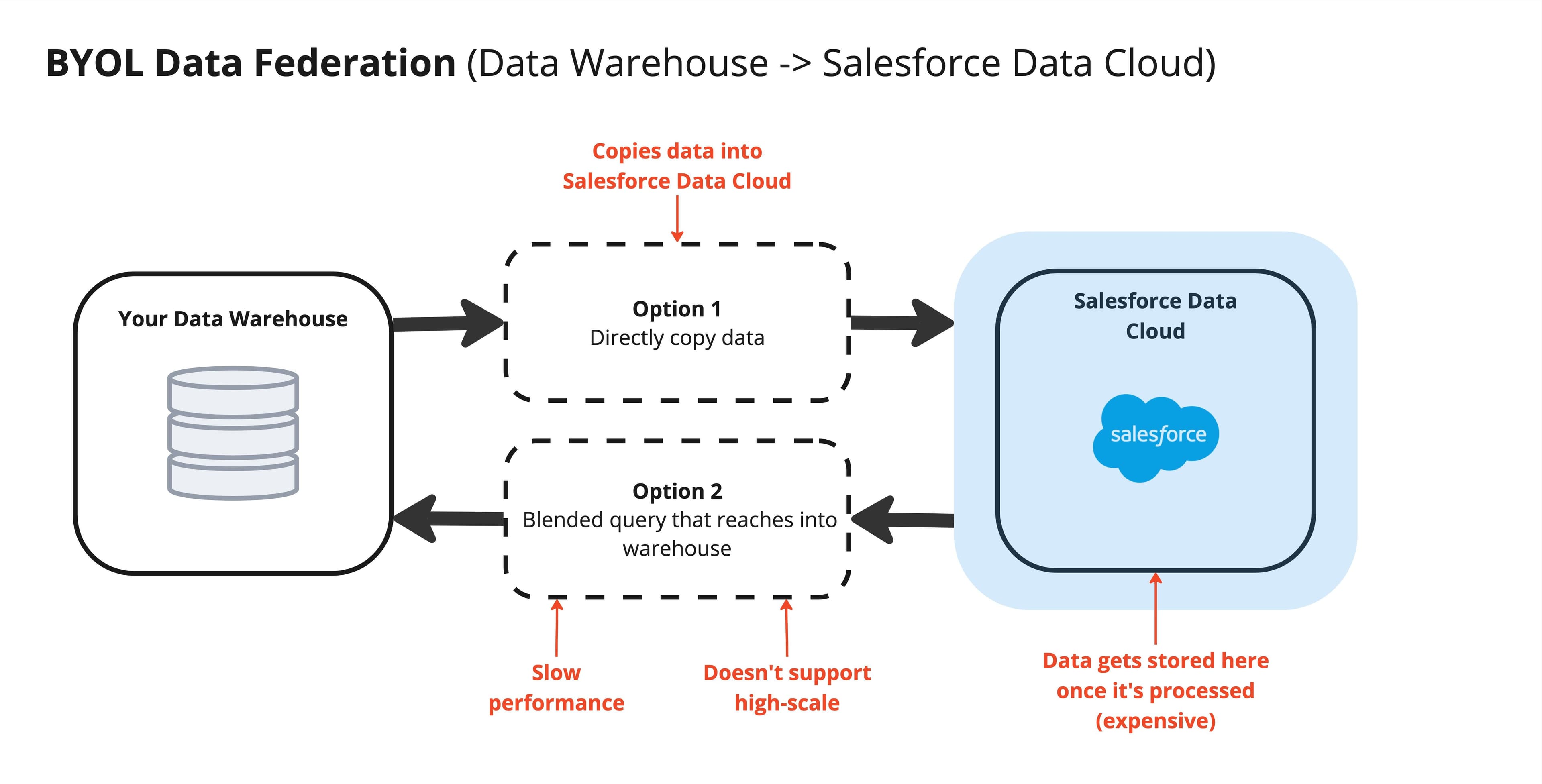
Accessing data in this direction is much more complicated than via data sharing. From all our research and discussions with customers, it seems as though there are really two options to access warehouse data within Salesforce Data Cloud:
- Copy it into Salesforce Data Cloud: Salesforce refers to this copy as an “accelerated data object,” and cleverly calls this action “caching.” In reality, this means you query the warehouse and copy the entire dataset into an external data lake object (DLO) within Data Cloud. From our experience, it seems as though Salesforce will typically recommend this option since it will allow their audience queries to be much more performant, and Salesforce also can benefit by charging customers for the extra caching storage. It is, quite literally, not a zero-copy solution: you must copy your data into Salesforce Data Cloud.
- Run a blended query: This second option gets closest to the spirit of zero-copy, and seems to allow an audience query to directly blend across data stored natively within Data Cloud and data within your warehouse. We’ve heard from customers that this solution does not scale well, and is completely incompatible for tables greater than several million rows. Also worth mentioning, although the underlying data stays within the warehouse, the actual results of any audience would get published and stored within Data Cloud.
In summary: Salesforce’s zero-copy architecture is only truly zero-copy if you use “data sharing” to access Salesforce data in your warehouse. Directly using warehouse data within Salesforce Data Cloud, however, (BYOL) requires extra work and ongoing maintenance, is unnecessarily expensive, and actually makes a copy of your data into Salesforce’s infrastructure. This setup has several other technical drawbacks:
- Requires you to change your data schema: For Salesforce Data Cloud to query and aggregate your data, all of the objects in your data warehouse have to map directly to Salesforce’s standard Customer 360 Data Model; otherwise, that data is unavailable for data federation. You can’t bring your data as-it-is and must restrict yourself by explicitly mapping your data to Salesforce’s data model. This is hard to do, and also requires you to mount this refactored data into Iceberg tables—yet another complication for you to manage.
- Involves limitations, delays, and cannot support high-volume datasets: Many Salesforce Data Cloud features are only designed to work if your data is natively stored in Salesforce. Only a limited number of audiences can involve BYOL datasets, and these can also only compute on an interval of every 12 hours (according to their docs). There are also significant query limitations depending on the volume of your datasets. Case and point: we’re currently working with a large retailer who is unable to query any datasets via BYOL from their warehouse above several million records.
- Creates many copies of your data: As discussed above, BYOL data federation makes a copy of data into Salesforce Data Cloud. Then, if you want to use that data in other tools in the Salesforce ecosystem (like their CRM or Salesforce Marketing Cloud), you need to make yet another copy for each tool– they can’t act from that original store of data.
A Simpler Approach to Zero-Copy
Companies are interested in zero-copy MarTech because they want access to complete data without paying for risk-inducing copies of it. Composable MarTech actually solves this exact problem.
Composable tools like Hightouch’s Composable CDP operate directly in your data warehouse. This means that when you use them, you have full access to your data. There is no rigid schema your data needs to conform to; there are no volume restrictions or hidden fees, and there is no extra setup and maintenance work to "cache" your data in Salesforce. In Hightouch’s case, you can build audiences and journeys, analyze campaigns, and more—and none of these actions require copying data from the warehouse into Hightouch. This is very simple to set up, especially compared with the hoops and hurdles you go through to set up Salesforce’s “zero-copy.”
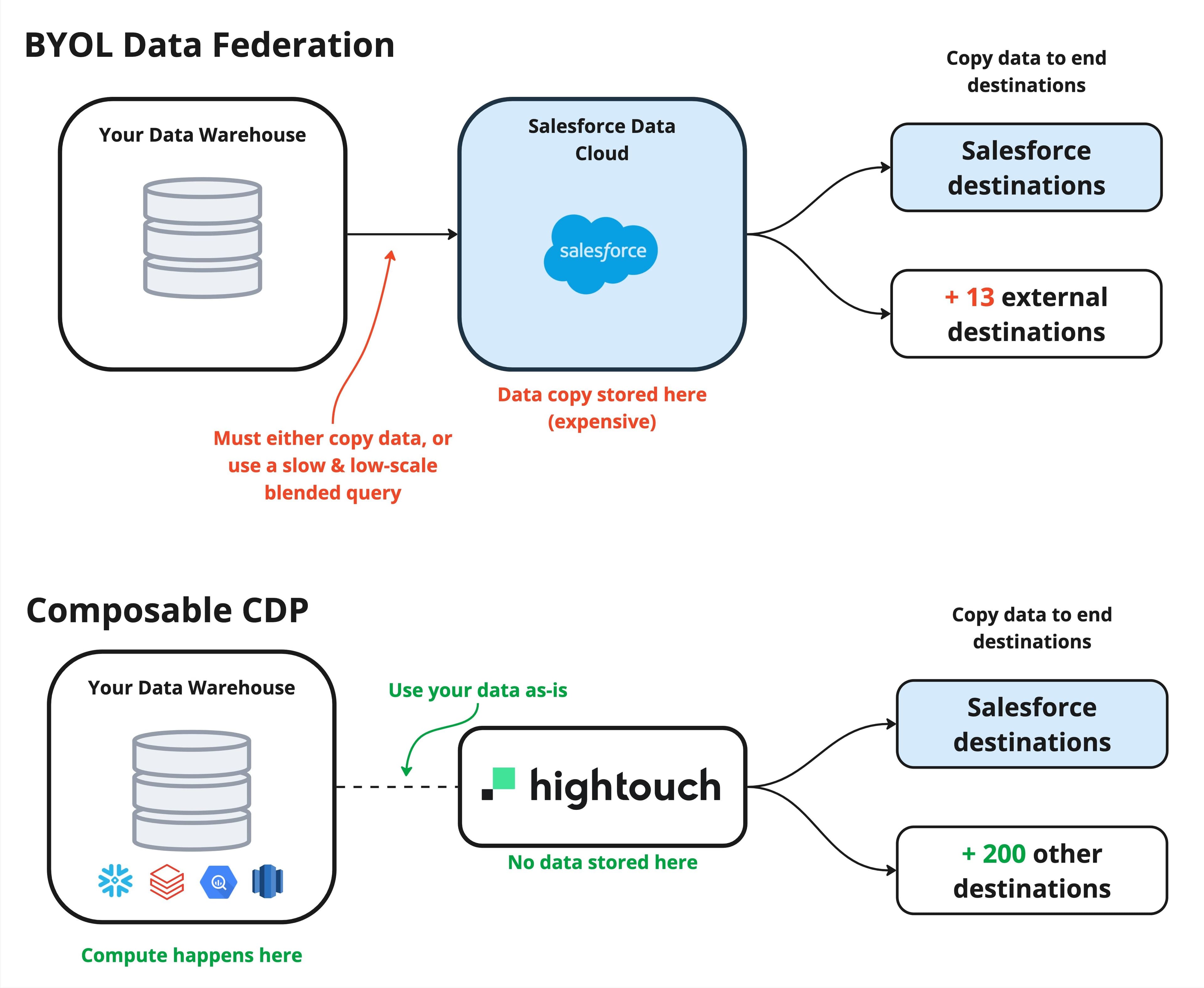
Hightouch allows marketers to build audiences and journeys inside the data warehouse. This allows Hightouch to analyze and act on your data without making a copy of it, which means Hightouch can work with your data “as-is,” without requiring you to conform it to a pre-set schema like Salesforce. Compute takes place in your warehouse, which is far more affordable and faster than Salesforce Data Cloud.
To be clear, the Composable CDP doesn’t entirely eliminate the problem of data copies—and no solution does. Many SaaS apps like email and advertising platforms require a copy of data in them to function. However, the Composable CDP empowers your warehouse to be the single, comprehensive data layer for all marketing activity, and then allows you to govern and only send data to other tools that are absolutely necessary for activation.
Use the data you have, where you have it
The promise of “zero-copy” tooling is incredible: give marketing and business teams access to your complete data, where it lives, in the format it’s already in.
Salesforce Data Cloud falls well short of this standard. Using data warehouse data inside of it requires data teams to extensively rework their existing data, which means that end-users will only get access to a snapshot of their data. If you actually want to operate on your data, it will be copied into Data Cloud—and processing that data is slow and expensive.
Truly Composable tools like Hightouch avoid this quagmire by operating on data where it lives, in the format it’s in, in the cloud data warehouse. If you’re interested in learning more about how you can empower marketing and business teams to use your data as it is today, grab some time with our solutions engineers.
Note: Researching this topic was challenging because of spotty Salesforce documentation. If you think we’ve got something wrong or have more details you can share from your own experience, reach out.

















