
What Is a Data Lakehouse?
The lines between a data warehouse and a data lake have always been somewhat blurry. Converging solution capabilities not only made setting definitions harder, but they have also sprouted a novel hybrid data repository category: the data lakehouse. Before we outline its benefits and use cases, let's look back on how we got here.
The Yin and Yang of Storing Data
With data technologies evolving so fast, it’s easy to forget that the juxtaposition of the data warehouse and the data lake comes from the past decade's hardware trade-offs, forcing data professionals to rig one solution or the other. That is, if you didn't want to break the bank.
The data warehouse and the data lake both have their strengths and weaknesses. They are each other's yin and yang and most often coexist within the same data stack.
With near-infinite low-cost scalability, data lakes are the preferred solution for capturing, storing, and serving massive raw, schemaless data sets collected from server logs, IoT sensors, and click behavior. All the data is stored, irrespective of source, anomalies, or format. With the schema-on-read paradigm, the structure of the data is only defined after capturing and storing it. Consequently, a typical workflow from the perspective of the data lake is ELT (extract, load, transform).
On the other hand, the data warehouse has the core capability of querying highly processed structured data and returning a response at a mind-boggling speed. To access the data, users can rely on a predefined and strict schema. Traditionally, the preferred workflow from a data warehouse point of view is ETL: The data is extracted and transformed before loading it according to the schema. However, we’ll discuss why many organizations are switching to an ELT workflow within their data warehouse setup below.
With Different Needs Come Different Solutions
Decision scientists, data scientists, and machine-learning engineers need access to immense data volumes to develop algorithms and answer the most complex business questions. With their hypotheses and exploratory analysis steering them toward opportunities, their data needs are unpredictable. Handing them the keys to the data lake is the logical thing to do.
On the other hand, in their day-to-day operations, business professionals need access to quick answers that help them make appropriate decisions. These answers come in the form of tickers, tables, visualizations, and natural language. The software that produces this output requires a data warehouse that supports a speedy response to repeated and ad-hoc queries.
Introducing the Data Lakehouse
The data lakehouse (a portmanteau of lake and warehouse) is a concept that moved into the spotlight in 2019 and 2020. One prominent actor in popularizing the term is Databricks, the company behind the popular open-source data processing framework Apache Spark. Spark is best known for giving data lakes analytical capabilities.
In 2019, Delta Lake was released. By adding this storage layer on top of Apache Spark, data lakes can be ACID-compliant (like transactional databases) and can enforce a schema-on-write.
In other words, it eliminates the need to have both a data lake and a data warehouse and reduces data redundancy. The data lakehouse was born.
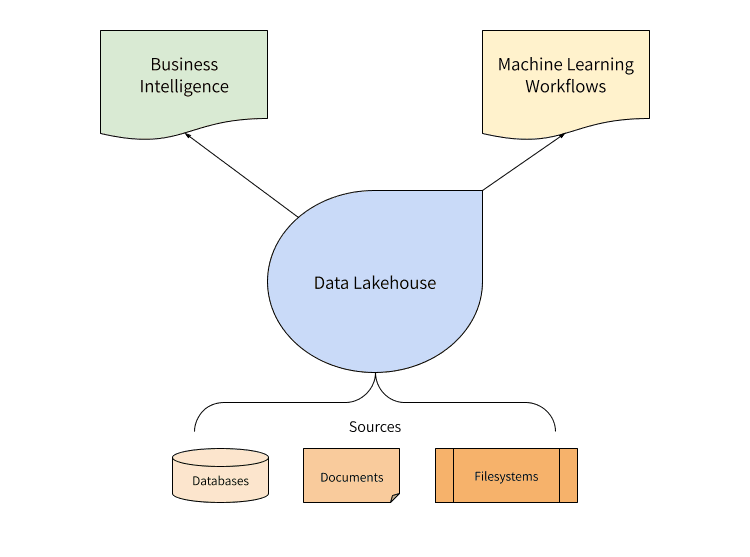
According to Databricks, a data lakehouse brings the best capabilities of data warehouses and data lakes together. It is "what you would get if you had to redesign data warehouses in the modern world, now that cheap and highly reliable storage (in the form of object stores) are available."
These are the key features that differentiate a data lakehouse from a data lake:
- Transaction support (ACID compliance)
- Schema enforcement and governance
- Business intelligence (BI) support
And the following are properties of a data lakehouse that separate it from a data warehouse:
- Decoupling of storage and computing
- Support for data types, ranging from structured to unstructured
- Support for all kinds of workloads. Data science, machine learning (ML), and analytics tools can all use the same repository
- End-to-end streaming
Let's pause and take a closer look at that last set of capabilities.
Decoupled Storage and Computing
If decoupling storage from computing gives you déjà vu, it's not without good reason. The lines between a data lake and a data warehouse have been blurring for years—we just didn't call it a data lakehouse. Not only have modern enterprise data warehouses (EDWs) become faster and cloud-based, they have been slowly creeping toward the data lake in terms of new features and cheap storage.
Let's look at two popular solutions offering cheap storage that scales independently from computing power.
Google BigQuery has been around for over a decade. Look under the hood of Google's cloud EDW solution, and you'll find a strict separation of Dremel, the query engine, and Colossus, where all data is stored in the ColumnIO file format, supporting fast access for Dremel workloads.
From a Google Cloud blog article from 2016: "Colossus allows BigQuery users to scale to dozens of petabytes in storage seamlessly, without paying the penalty of attaching much more expensive compute resources—typical with most traditional databases."
With Snowflake's successful IPO in 2020, it's easy to forget that their EDW solution is almost a decade old. Here too is the separation of storage and computing at the core of the product.
And that has never been different. From a 2014 Snowflake whitepaper: "In a traditional data warehouse, storage, compute, and database services are tightly coupled…Snowflake's separation of storage, compute, and system services makes it possible to dynamically modify the configuration of the system. Resources can be sized and scaled independently and transparently, on-the-fly."
These two examples prove that the decoupling of storage and computing isn’t really that much of a differentiating capability of the data lakehouse.
Semi-structured and Unstructured Data
That brings us to support for semi-structured and unstructured data. On top of JSON support, BigQuery has its nested field type. Snowflake handles semi-structured formats such as JSON, XML, Parquet, and Avro as a VARIANT field.
While it’s correct that genuine support for unstructured data—such as images, video, or sound—is not supported, many businesses don't have a need for it, either because it's unrelated to their market or they don’t have aspirations to develop AI applications like computer vision in-house.
Moreover, the possibility of storing raw and semi-structured data in an EDW is responsible for flipping the typical workflow upside-down. If storage is cheap, and structure is not a prerequisite, there’s no reason for manipulating the data before storing it in a data warehouse. It even spawned a new set of popular tools and an accompanying job role tailored for ELT workflows within modern EDWs like Snowflake and BigQuery. dbt (data build tool) and Dataform are the weapons of choice of the analytics engineer.
All Kinds of Workloads
With analytical query engines at their core, BigQuery and Snowflake are best-of-breed solutions for analytical workloads. Nevertheless, both vendors encourage their users to utilize their data repositories for all kinds of workloads, including machine learning.
Even more so, BigQuery ML abates the nuisances that come with the machine-learning workflow by allowing end users to engineer features and utilize a spectrum of unsupervised and supervised machine-learning methods within BigQuery SQL.
End-to-end Streaming
And then finally, streaming. While Snowflake does not support a native solution for receiving streaming data, it has an easy-to-set-up middleware known as Snowpipe that listens for changes in a storage bucket and sends the data into the warehouse.
BigQuery, on the other hand, supports streaming inserts natively via its API.
So…what exactly is a Data Lakehouse?
It's easy to see what sets the lakehouse apart from the traditional data lake. But from the modern data warehouse? Not so much.
As I've shown, data warehouses have long been crossing over to their data lake counterparts and adopting a variety of their capabilities. Google even lists “convergence of data warehouse and data lake” on BigQuery’s product page. Consequently, from a functional perspective, the lakehouse isn't fundamentally different from a modern data warehouse.
The main differentiator is of a technical nature: the data lakehouse adheres to the data lake paradigm.
- At its core, there is a storage layer such as HDFS or cloud storage.
- On top of that, there is a query engine such as Apache Spark, Apache Drill, Amazon Athena, or Presto.
- Finally, the third layer is a storage abstraction framework, such as Delta Lake or Hudi,` that adds additional capabilities like ACID compliance and schema enforcement.
Consequently, it’s the direction of the crossover that defines the data lakehouse.
Finally, the data type support remains much broader than nested and tabular objects, including audio, video, and time series. If those formats are your concern, the data lake(house) continues to be the most flexible destination for simply dumping your data, both stream and batch.
Conclusion
Is your organization assessing whether it should embrace a data lakehouse or a data warehouse? Or does it want to simplify its stack by eliminating the lake or the warehouse?
As I've shown, both modern warehouses and lakehouses share a lot of the same capabilities. If you don't care about what's under the hood or which paradigm should be abided by, the degree of unstructuredness that you require should be your primary consideration.

















