
It happens all the time: I'm sipping my morning coffee in a stand-up meeting and someone says, "The data in that report doesn't look right." The statement is broad, but the investigation immediately becomes complex and requires details, because without the proper information, I have no idea what that person is saying might be "wrong" with our data. Is it inaccurate when referenced against the sources? Are there duplicate rows? Or is there a discrepancy between the monthly Excel version of the report and the BI tool version of the same that runs off our data warehouse?
These are just a few of the questions that rush through my head when I hear that data doesn't behave the way a stakeholder expects. I work with the Extract, Transform, Load (ETL) cycle and the data warehouses it serves every day. If you work with data too, you know how these rabbit holes go. Whether it's inconsistency, inaccuracy, missing data, or something else, the debugging process to find out where the data went wrong before it got to your data warehouse is always complicated. That, and it never happens fast enough for the business.
Why Test Your Data Warehouse?
The data warehouse is the destination for your beautiful, clean data to be delivered to whatever tools the business needs the data for. Whether that's business analysis, fraud operations, company executives, or regular reporting, that data should be ready to go by the time it's in the data warehouse. If it's not, broken data begins to appear in all those places, and the emails and chats commence asking what happened and how it can be fixed.
What if it never got to that point? Testing the data throughout the ETL pipeline—and adding requirements for acceptance to the data warehouse—can stop bad data from ever reaching a stakeholder's eye. This makes the data in the production warehouse more accurate, consistent, and complete.
How Can Automated Tests Fit Into the ETL Pipeline?
So, how can data engineering teams test fast and light in a useful way, while keeping the business running on well-maintained data warehouses? I'm sure you've heard it before: automation. It's up to individual data engineering teams to decide where tests can save them manual validation time and stop broken data from entering the data warehouse.
As a general rule, if you can test it manually, there's a way to automate it. Different types of automated tests work as checkpoints in every part of the ETL pipeline, and look in on Source Behavior, Transformations, and Output.
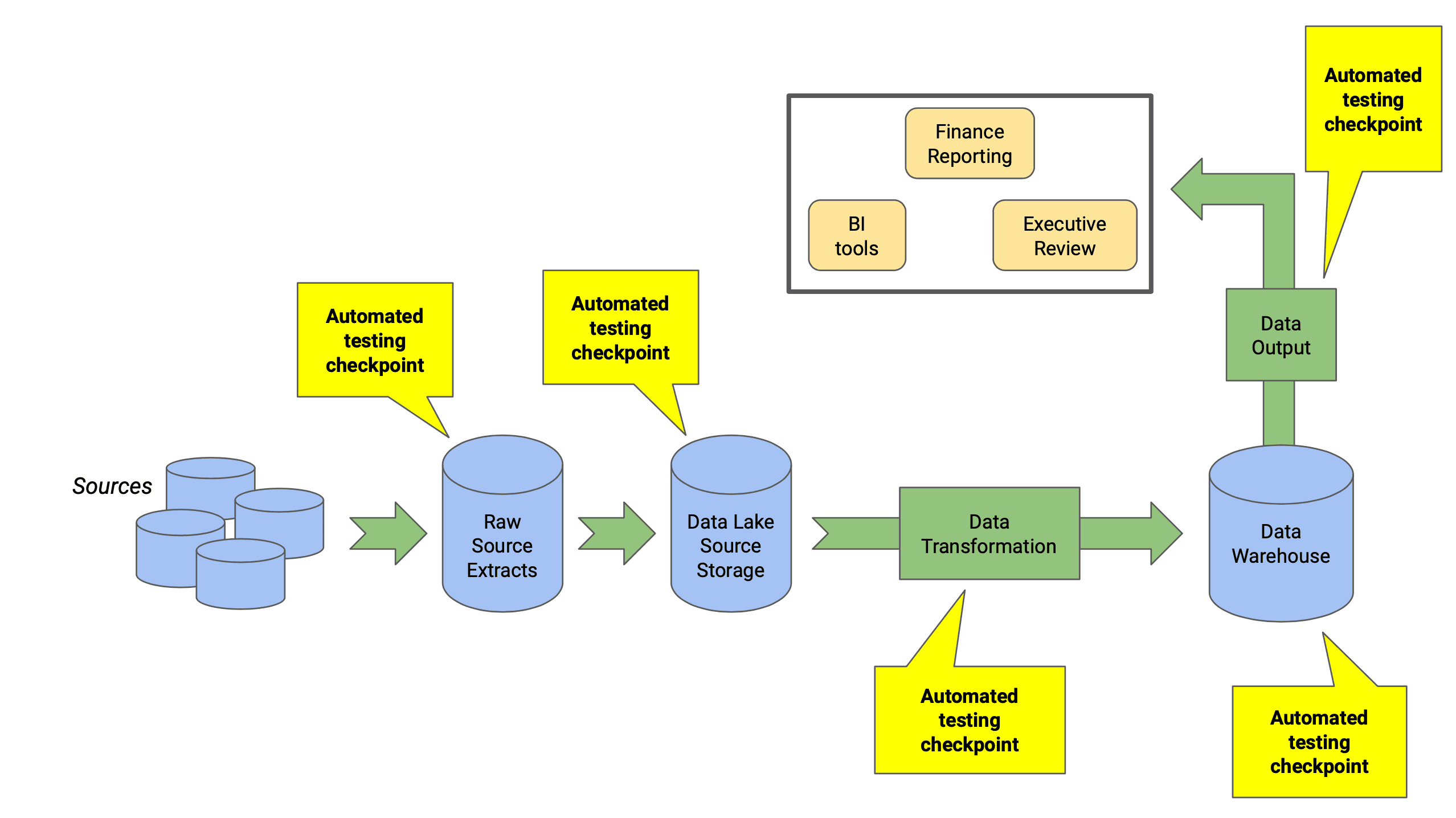
Possible Blockers to Implementing Automated Tests in Data Warehouses
Before we talk about the different types of testing that should happen in data warehouses and the tools that can help, let’s go over a few caveats about automating tests in your data warehouse. Automation isn’t currently possible for all data warehouses, so before you start to consider adding planned automated testing, here are a few potential blockers you could run into.
- Your company is in the process of overhauling its data architecture. You don't want to automate tests that will be irrelevant in the near future. If the data pipeline to the warehouse is experimental or in development, this could be a blocker to useful automated testing.
- Most of the data engineers you work with don't prioritize testing. Unlike software developers, data engineers aren't often taught that a testing methodology should be built into any programming cycle. Josh Temple from Spotify's analytics engineering has a good take on this. This could be a blocker, as more evangelizing for testing must be done.
- Your data architecture doesn't yet use ETL. If your data warehouse uses some other type of pipeline that isn't ETL, this could be a blocker for using automated testing in the warehouse.
Types of Data Warehouse Testing
Data can seem nebulous and unwieldy at times, especially when you're working with complex data warehouse pipelines. But there are ways to nail down data issues and fix data quality before it reaches a production data warehouse. Here are the primary types of data warehouse testing, and a little bit about why they're important for data quality.
Data Source Testing
Data sources, whether they are loaded to on premises source databases or cloud solutions, are generally the first place that messy data exists. It's no secret that a great number of businesses still rely on things like spreadsheets and VLOOKUPs to do critical reporting. I've seen it more than a few times, and the manual process not only hinders expediency, but is fraught with different kinds of errors that come from the attempt to translate Excel logic into a data warehouse output.
Adding automated testing to source data at the Extract point alleviates problems like Null rows, wrong values, or incompatible encoding before that source data breaks the Transform stage. And if you have a good relationship with the folks who maintain the sources, whether they be databases or spreadsheets, you can harness their expertise to determine where they often see broken data.
Data Completeness Testing
"There's data missing here." Maybe you've heard this, just like I have. What does that mean to a data engineer? Where do we start to look for something that we didn't know was "missing" during ETL in the first place?
Testing for data completeness can help mediate missing rows, columns, and broken ETL logic within your data warehouse. If you expect to see millions of rows in the data warehouse, you can test to ensure they are all present.
Data Accuracy Testing
At all stages of the ETL process, the data shouldn't be altered in such a way that it no longer represents what it meant in the source. This is data accuracy. For example, if a company name exists in a Clients table in the source database, that same company name should be accurate in the data warehouse, wherever it is used for reporting. The company's name shouldn't change in such a way that it no longer represents the client.
Because of the data transformations that occur along the ETL process from source to data warehouse, it's not easy to check for data accuracy. But it can be done with the right automation, written to match expected transformations and check for a golden data set as it mutates along the way.
Data Consistency Testing
Checking for consistent data in the data warehouse has layers, but you can start with an output that you know has required variables aggregated in its data set. For example, a state abbreviation field. This field can be treated differently in different sources and transformations.
Testing for data consistency can ensure that all values which represent a data type, such as a state, are captured in the data warehouse. Rows using that data type will then be interpreted and used consistently throughout the aggregated data in the warehouse.
Automated Testing Tools for the Data Warehouse
Now that we know why we care about testing in our ETL pipeline for broken data before it hits production—and the primary kinds of testing that can help catch that data—let's take a look at how we can implement this in different ways. Some of the primary types of data warehouse testing are covered in each of these tools.
Great Expectations

Great Expectations is a widely used and supported data assertion testing library that sits inside almost any data pipeline. On top of helping eliminate bad data in the data warehouse, the framework provides detailed documentation on test cases and validation reporting.
Key Features
- Python-based, which means happily familiar code for many data engineers
- Contains dozens of different kinds of data assertions that cover data accuracy, consistency, and completeness
- Integrates with Microsoft SQL Server, Redshift, BigQuery, MySQL, Snowflake, Pandas, Jupyter Notebooks, and others
- Generates a nice UI in HTML documentation that explains test cases and test results
Cost
- Fully open source and supported by the library's engineering team at Superconductive as well as the community
Ideal Use Cases
- Best used in a data pipeline runs on Python
- Solid framework for getting data assertions up and running quickly
- Great Expectations is a good choice for engineers who need to test data anywhere in the pipeline, from CSV sources to Pandas dataframes, Spark dataframes, and other potential problem spots.
dbt Tests
Fishtown Analytics' data build tool (dbt) is a popular ETL automation tool that has built-in test functionality for unit testing and data validation. Engineers can write simple one-line tests for quick column checks such as unique values or compose complex SQL tests, all of which execute in the data pipeline.
Key Features
- Robust programming environment for data transformation with built-in tests
- Works primarily as a runner and compiler in the Transform stage
- Many open-source packages available for even more testing
- Integrates with Postgres, Redshift, Apache Spark, BigQuery, Snowflake, and others.
Cost
Pricing for dbt comes in three tiers, which are based on whether or not you and your team may want to use dbt Cloud versus the CLI.
- One Developer license is free
- Team license(s), $50/dev per month
- For the Enterprise level, call Sales
Ideal Use Cases
- Best used to validate data in the Transform stage
- Engineers can write built-in unit tests as they write data models
- You'd like a UI that works on an enterprise level where data engineers can validate their data
Bigeye
Bigeye (formerly Toro) is a data monitoring framework with a number of built-in automated tests that can cover accuracy, completeness, consistency, and even freshness. With a UI that allows data engineers to easily create a suite of tests (called "Autometrics") checking for all of the major kinds of data problems, you can even test for syntax and cardinality without writing a line of code.
Key Features
- Monitors data in various ways as its number one job
- Web-based UI for adding test cases on all major data testing types
- Read-only agent in your data warehouse so it won't change your data
- Integrates with Redshift, Snowflake, BigQuery, and others
Cost
Bigeye has two cost tiers, one for business and one for enterprise. Neither has a public cost shared on the Bigeye Pricing page. It's more about the size of the account:
- Business (hundreds of tables monitored)
- Enterprise (thousands of tables monitored, SOC 2 and HIPAA compliance, improved support)
Ideal Use Cases
- Good choice for a data warehouse with a data pipeline in place
- Data engineers want to monitor the data and get reports in their work channels
Monte Carlo

Monte Carlo is a fully customizable data monitoring and alert system in a nice web-based application, designed to catch data warehouse anomalies before they cause a problem. Most of Monte Carlo's automated testing is behind the scenes; the engineers simply choose which "Alerts" to use and how they want to use them.
Key Features
- Data monitoring at every step of the way: Extract, Transform, and Load
- Compatible with all major data stacks and even BI tools such as Tableau
- No programming required to write alerts
- Out-of-the-box usage and understanding of data lineage
Cost
The Monte Carlo website offers only a way to request a demo of the tool, which likely means you're looking at negotiating a custom cost.
Ideal Use Cases
- You need a custom data monitoring tool that is SOC 2 compliant
- End-to-end data monitoring across the entire data lineage to the warehouse
- Finding data as it's breaking the pipeline in real time via Alerts
Acceldata
Acceldata is a jack-of-all-trades for data control across your warehouses, ETL process, migration, and more. More important, it has an automated data validation platform called Torch, which can integrate business rules as data validation tests.
Key Features
- Torch data validation checks more than just accuracy, consistency, and completeness
- Connect data assets to auto-compare
- Can control and validate millions of rows
- Compatible with Redshift, MySQL, BigQuery, Snowflake, Kafka, and a few more
Cost
With such a breadth of data pipeline control, it's no wonder you'll have to contact Acceldata to find out the cost of their different products.
Ideal Use Cases
- Full control in one UI tool to run everything end to end
- Controlling data validation in a set of professional tools with paid support
Wrap-up
Testing your data warehouse is just filtering out the broken data in order to go back and fix it before it's approved for production. This is an essential part of making sure that stakeholders can trust the data warehouse and the data engineers who work hard to maintain its integrity.
Data can be incredibly complex when it comes to testing and validation. But adding relevant, timely validation to your end-to-end data treatment at the right points in the ETL process can save you from scrambling when someone emails and says the data looks wrong. Your best chance is to find the data testing automation tool that works for your circumstance, and give it a try.

















