
Snowflake supports most basic SQL data types but has some restrictions. This article will introduce you to Snowflake and show how you can leverage the various data types supported in the platform.
What is Snowflake?
If you know what Snowflake is, go ahead and skip to the good stuff. If you’re not a part of the modern data stack world, then read on!
Snowflake is a cloud-based, relational data warehouse offering users DataBase as a Service (DBaaS). It brings flexibility and scalability with built-in functions such as auto-scaling and auto-suspend. Snowflake is a cloud-independent solution that offers a uniform user experience across all three major cloud providers: AWS, Azure, and GCP.
Because of the possibility of storing both structured and semi-structured data types, Snowflake can be used as both a data lake and data warehouse (and/or setting up a data lakehouse architecture). Snowflake eliminates all the setup and management that might be needed if you did this yourself.
Stop Settling for “Good Enough” Customer Data
Over 40% of companies say their off-the-shelf CDP barely moves the needle. Don’t let that be you. Our new whitepaper reveals how to use Snowflake to design a Composable CDP that finally delivers on the promise of unified, high-impact customer insights. Learn from real-world winners like Lucid and Auto Trader and position your organization for next-level growth.
Take the fast track to a scalable, future-proof CDP—download your copy today and stay ahead of the competition.

Supported Data Types in Snowflake
Now you know some key features of why people use Snowflake for their data warehouse, we can start looking at the supported data types in Snowflake.
Numeric Data Types
Numeric data types can be whole numbers or decimal numbers such as “23” or “145.12”.
When declaring certain numeric data types, there are two values you can change to help optimize the data stored in your tables.
Precision is the total number of digits allowed for a numeric data type, and scale is the number of digits allowed to the right of the decimal point.
You can create several different numeric data types:
- NUMBER: stores whole numbers with the default settings as precision is 38 and scale is 0.
- DECIMAL: synonymous with NUMBER.
- NUMERIC: synonymous with NUMBER.
- INT, INTEGER, BIGINT, SMALLINT: synonymous with NUMBER but doesn’t allow for precision and scale to be changed. It is set to the default (precision is 38 and scale is 0.)
- FLOAT, FLOAT4, FLOAT8: Snowflake treats all three of these are 64-bit floating-point numbers and supports special values such as Not a Number
NaN, infinityinf, and negative infinity-inf. - DOUBLE, DOUBLE PRECISION, REAL: All three of these are synonymous with NUMBER.
- Numeric Constants: Snowflake supports numerical constants, also referred to as literals. The format of how to use there looks like this:
[+-][digits][.digits][e[+-]digits]
You can look at how you can create different data types and how they behave if you change the precision and scale with example below.
With the code below, you can create a table with customer info for an E-commerce company.
Note: These examples illustrate how customer data can be structured in Snowflake. In practice, Hightouch makes it easy to activate this data for marketing campaigns without requiring your team to write any SQL.
create
or replace table customer_data(
customer_ID number,
total_amount_spent number(10, 2),
number_of_times_logged_in float,
age numeric(3, 0),
telephone_number number(5, 0)
);
In the table, you’re creating multiple numeric data types. You can see how you create a column by naming it and then specfiying the data type. The numbers in brackets are the precision and scale, respectively.
You can put data into the table with the code below and see how it reacts to the data types we created.
insert into customer_data
values
(1234.12, 10.434, 6, 10, 78884);
The first thing you’ll notice if you run this is you’ll get an error message. This error message is due to the data you’re trying to enter in the telelphone_number field. The precision was only set to five digits, where you’re trying to enter a 10-digit number.
When you created the table, you set the customer_id as a NUMBER, but the entered data had decimal places. As you can see, because a scale wasn’t specified (the default is 0) the decimals are dropped.

You can also see a number was entered into a total_amount_spent with three decimal places, but the scale was set to two, so it dropped the last decimal place. Both the number_of_times_logged_in and age weren’t changed because they were correct values for the data types we created. And the altered telelphone_number was entered without any issues.
String and Binary Data Types
String and Binary data types are one of the most commonly used. They represents a sequence of digits, characters, or even symbols. An example could be a name “Sam Husselback” or a phone number “123-123-123”.
The following are some of the different types of String and Binary data types.
- VARCHAR: can hold Unicode UTF characters and is limited to a maximum length of 16MB. When declaring a VARCHAR, you have an optional parameter that allows you to select the maximum number of characters to store.
- CHAR, CHARACTER: is the same as VARCHAR but only allows the maximum length of one character.
- STRING: Is the same as VARCHAR.
- TEXT: Is the same as VARCHAR.
- BINARY: The maximum length of a BINARY is 8MB and doesn’t have any notion of Unicode characters, so the length is measured in terms of bytes.
- VARBINARY: Is the same as VARBINARY.
- String Constants: refer to fixed data values and are always enclosed between delimiter characters. Snowflake has two methods to delimit string values.
- Single-Quotes String Constants: A string constant can be enclosed between single quote delimiters like this (‘I am a string’).
- Dollar-Quoted String Constants: If a string constant contains single quote characters, backslash characters, or newline characters, you can enclose them with dollar symbols.
You can look at these data types by creating a new customer_data table with just String and Binary types with the code below.
create
or replace table customer_data(
first_name VARCHAR(5),
last_name STRING(7),
gender CHAR
);
In the table, the data has specified the length of some of the columns we created. You can enter data with the code below and see how it responds.
insert into customer_data
values
('Alexander', 'Smith', 'female');
The first thing you’ll notice is an error occurs. This is because the first_name column was set only to have five characters, and the entered data was too long. You can change Alexander to Alex instead to remove the error. If you run the code again, another error will show.
You’ll get a message similar to the above. This time, it’s because “Female” was entered into a CHAR data type. CHAR data type only accepts one character. If you change “Female” to “F” and rerun the code, everything is ok, and the data is inserted.

Logical Data Types
Snowflake supports a single logical data type, BOOLEAN, which can have a TRUE or FALSE value. BOOLEAN can also have an “unknown” value displayed as NULL. The BOOLEAN data type can also support Ternary Logic.
You can create a table with the code below to look at Logical data types in action.
create
or replace table customer_data(
logged_in BOOLEAN, has_downloaded_white_paper BOOLEAN,
has_paid BOOLEAN, has_viewed_over_4_webpages BOOLEAN
);
You can use the code below to insert some data into the customer_data table.
insert into customer_data
values
(
'customer is logged in', 1, 'true',
'off'
);
The first thing you’ll notice is an error message. This is because you’re trying to enter the string ‘customer is logged in,’ which is not recognized as a BOOLEAN value. Change that to TRUE and see if you get any errors.
You would think you would get more errors due to the other entered strings, but Snowflake can explicitly convert strings and numerical values using readily available functions.

The table shows that ‘1’ and ‘true’ have been converted to TRUE, and ‘off’ has been converted to FALSE. You can find more information on what can be converted to a BOOLEAN value in the Snowflake documentation.
Date and Time Data Types
Dates and Time help you track when an event happened. Snowflake has a range of different formats of date and times that are usable such as “2023-01-01”, “01-Jan-2023”, or “ '2023-01-01 01:00:00”.
Below are the date and time data types that Snowflake supports.
- DATE: allows you to store just the date without any time elements and supports most of the common forms such as YYYY-MM-DD and DD-MON-YYYY.
- DATETIME: is an alias for TIMESTAMP_NTZ.
- TIME: allows you to store the time in the form of HH:MI:SS, and you have the option to set the precision, which is set to a default of 9. The TIME value must be between 00:00:00 and 23:59:59.999999999.
- TIMESTAMP: is a user-specified alias associated with one of the TIMESTAMP_* variations. In operations where TIMESTAMP is used, the associated TIMESTAMP* variation is used automatically, and the TIMESTAMP data type is never stored in tables.
- TIMESTAMP_LTZ, TIMESTAMP_NTZ, TIMESTAMP_TZ: Snowflake supports three different versions of TIMESTAMP:
- TIMESTAMP_LTZ: stores UTC time with specified precision, and all operations performed in the current session’s time zone are controlled by the TIMEZONE session parameter.
- TIMESTAMP_NTZ: stores “wallclock” time with specified precision with all operations performed without taking any time zone into account.
- TIMESTAMP_TZ: internally stores UTC time with an associated time zone offset. The session time zone offset is used if a time zone is not provided.
You can create a table with the code below to look at Data and Time data types in action.
create
or replace table customer_data(
last_logged_in DATE, time_of_purchase TIME,
account_created DATETIME
);
You can use the code below to insert some data.
insert into customer_data
values
(
'2022', '12', '2021-01-01 01:00:00'
);
Thankfully there are no errors, but you might find some things wrong with the data.

Strangely the last_logged_in date is 1970-01-01. This is because a unrecognised Date format was entered, so it has reverted to the start of the Unix epoch, 1970-01-01.
The data entered as the time_of_purchase was “12”, so it has converted into a TIME data format, assuming that 12 seconds was entered.
At first glance, the account_created value appears to be wrong. A DATETIME was entered, but it’s only displaying a date. This is only a display issue. By default, it shows a date, but you can change how you want to display the DATETIME by changing the Date/time format.
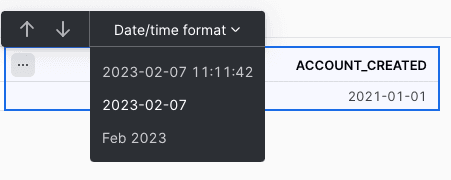
By doing so, you can see that the correct value is now displayed.

Semi-structured Data Types
Snowflake supports semi-structured data types, so you can load and operate on data such as JSON, Parquet, and XML. The semi-structured data types include:
- VARIANT: can store values of any other types, including OBJECT and ARRAY, and has a maximum length of 16 MB.
- OBJECT: can store key-value pairs which in other programming languages are often called “dictionary,” “hash,” or “map.” The key is a non-empty string, and the value is a VARIANT type.
- ARRAY: is similar to an array in other programming languages. It can contain 0 or more pieces of data, and each element is accessed by specifying its position in the array.
The special Snowflake column data type variant is very powerful, because it allows you to store semi-structured data without having to pre-define a specific schema. However you can easily query this table later on as if it were structured data. Let’s go through an example to see how this works.
First you need to create a table with the variant type:
create table json_sales_data (v variant);
You can now load JSON files into this table using Snowflake’s data loading steps, typically by batch loading via a stage. Manually, you can do the following:
insert into json_sales_data
select
parse_json(
‘{ "store" : { "location" : "CA-SanFrancisco-013",
"latitude" : "37.773972",
"longitude" : "-122.431297" },
"sale_obsTime" : "2023-2-17T10:03:15.000Z",
"total_amount" : "321" } ');
Now when you run a select * , you get one column (V) where the objects will be shown as above, in JSON structure.
To make it easier to query, you can create a view from this table that will put structure onto the semi-structured data. Views don’t copy data, the only thing they do is present data to the end user in a cleaner manner.
create
or replace view json_sales_data_view as
select
v : location :: string as store_location,
v : latitude :: float as store_lat,
v : longitude :: float as store_long,
v : sales_obsTime :: timestamp as sales_time,
v : total_amount :: int as sales_total_amount,
from
json_sales_data;
The SQL dot notation, as shown above (v:) pulls out values at lower levels within the JSON object hierarchy and will then treat the fields as if they were a relational table column, without changing the underlying table.
By now querying the view you created instead of the original table, you will get a structured table results with the above columns store_location, city_lat, city_long, sales_time, and sales_total_amount:
select
*
from
json_sales_data_view;
You can even query this view as if it were structured and/or join with other tables.
Geospatial Data Types
Snowflake supports Geospatial data types in two formats.
- GEOGRAPHY: models the Earth as a perfect sphere and follows the WGS 84 standard. This is where the points on the Earth are represented as degrees of longitude (from -180 degrees to +180 degrees) and latitude (-90 to +90).
- GEOMETRY: represents features in the planar coordinate system (Euclidean, Cartesian). The coordinates are represented as pairs of real numbers (x, y) and are determined by the spatial reference system (SRS). Currently, only 2D coordinates are supported.
Both of these data types support the following objects:
- Point
- MultiPoint
- LineString
- MultiLineString
- Polygon
- MultiPolygon
- GeometryCollection
- Feature
- FeatureCollection
Unsupported Data Types in Snowflake
There are a few data types that Snowflake doesn’t support. Large Objects (LOB) such as BLOB and CLOB aren’t supported. However, you can use BINARY instead of BLOB and VARCHAR instead of CLOB.
Other data types that aren’t currently supported are ENUM and user-defined data types.
Snowflake Programming languages
Previously Snowflake only ran on SQL, but with Snowpark, you can now leverage other development languages like Python, Java, and Scala in Snowflake.
Snowpark enhance the developer experience by letting you code in your preferred language and run that code directly on Snowflake. Using a language other than SQL, means you have better tools to solve more complex problems since all these languages have extensive open-source packages and libraries you can use to tackle specific use cases.
Using Snowpark also allows you to utilize the computing power of Snowflake. Rather than exporting the data to other environments, you can ship your code to the data, which can help with optimization.
Snowpark also lets you write unit tests and leverage CI/CD development pipelines that can push to Snowflake to create more dependable applications and Snowpark also allows for software application to work better on Snowflake with application such as Dataiku, dbt, and Matillion, enabling complex computations to push down to Snowflake.
There are three main workflows that Snowpark benefits the most.
- Data science and machine learning: Python is one of the most widely used programming languages for machine learning, making Snowpark Python framework a perfect fit. The Snowpark Dataframe API allows you to interact with Snowflake data, and the Snowpark UDFs let you use Snowflake computing power to run batch training and inference.
- Data-intensive applications: If you’re developing dynamic application that run on data, Snowpark can let you run those applications on Snowpark. Snowpark can also be combined with Snowflake’s Native App and Secure Dat Sharing capabilities, so you can process customer data in a secure manner.
- Complex data transformations: SQL can inflate the complexity of data cleansing and ELT workloads. Snowpark Python can take the functional programing paradigms, such as bringin in external libraries and code refactoring, and run on the Snowflake compute so there isn’t any needs ot ship data to an external environment.
Final Thoughts
Knowing which data types Snowflake supports can help you capture and ingest your data in the right format while also ensuring that you’re not compromising on data quality. Having a deep understanding of the different Snowflake data types will not only help you struture your data, but it will also help you tackle your analytics and activation use cases more effectively.

















