
We all went through it. At some point – maybe a few months ago, maybe a few years ago – we all heard someone say “dbt” for the first time.
If you’re like me, you thought, “what’s dbt and why is this person saying it like it’s a term I should know?”
For me, I was already about eight months into my first data analytics role. I was interviewing for a new job at a different company, and the VP interviewing me kept referring to “dbt.” I nodded in agreement as if I knew exactly what he was talking about.
As soon as the interview was over, I Googled “dbt” and came up with – of course – Dialectical Behavior Therapy. I thought, “I must have misheard what the interviewer was saying.” Or, maybe I had been confused about what type of company I was interviewing at 🤷🏻♀️ ?
But of course, a bit more sleuthing and I found it: dbt as in “data build tool.” Software made by a company called dbt Labs.
From that point on, it was a classic case of Baader-Meinhof phenomenon: from having never heard about dbt, suddenly I was seeing and hearing the name everywhere. I took a closer look at the scripts written by the data engineers I was working with – it turns out that what I’d thought were straight-up SQL scripts were actually written with dbt syntax.

If you are on a data team or work anywhere near one, you either:
- already know about dbt,
- already work in dbt,
- or, will soon hear about and possibly need to work in dbt.
For the uninitiated/soon-to-be-initiated, here’s what I think you need to know...
dbt: What is it?
One of the essential terms in data infrastructure is “ETL,” the “extract-load-transform” process of pipelining data from a source into a data warehouse. “Extract” is taking data from its original source. “Transform” refers to operations to get the data into a certain format or shape, such as deduplicating it, combining it, and maybe taking measures to ensure its quality. Finally, the “L” is for “loading” it into your warehouse.
These days, you’re more likely to hear “ELT” than “ETL”. This is because, in newer warehouses (like Snowflake, Amazon Redshift, Google BigQuery), everything is cheaper than it used to be. You can store lots of data for a relatively low cost, and performing transformations and queries on the data – what’s called the “compute” cost – is also much more affordable than in the past. This enables you to do the “load” first, then focus on the “transform” once the data is in your warehouse.
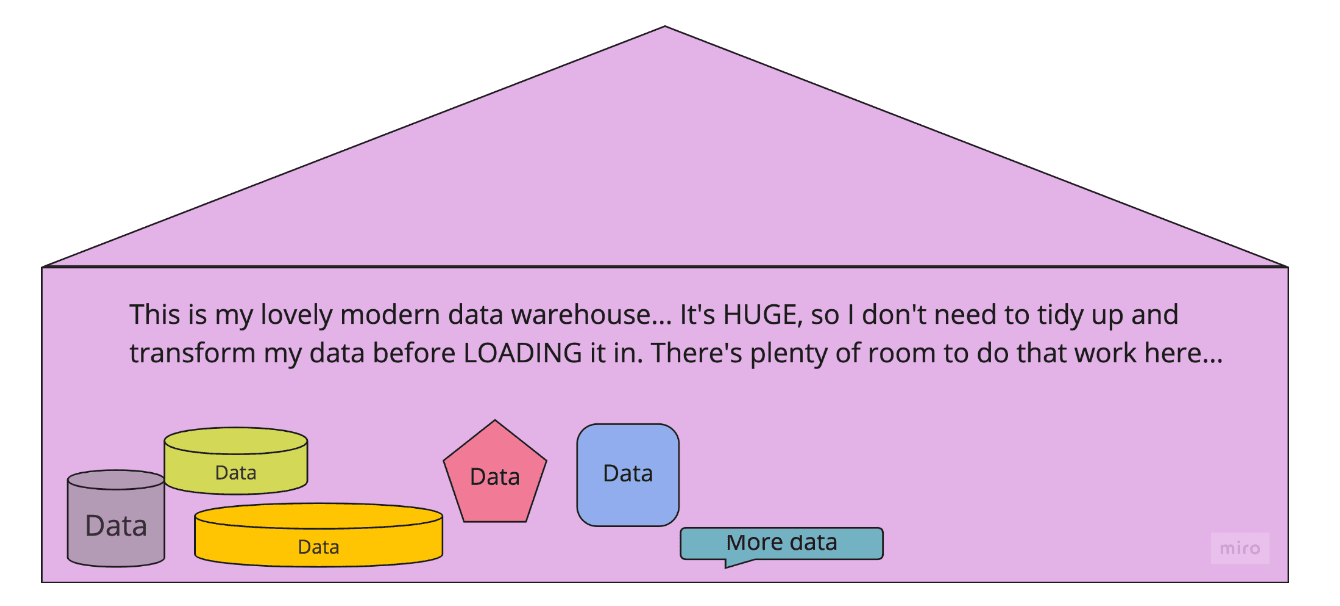
Where does dbt fit into this? dbt is a tool that focuses on just one part of the “ELT” process: the transformations.
dbt is an open-source software, but there’s also an enterprise version developed and sold by dbt Labs. The dbt Labs founding story bears some similarity to that of Slack: dbt started as a tool built by a small company, for internal use… but then, that tool became the company. More specifically, in this case, the tool became a unicorn currently valued at $6 billion. It’s a pretty fascinating history, worthy of its own article – here’s a good one.
So dbt does the “T” in “ELT” - what’s so special about that?
dbt is a tool that enables whoever is carrying out the transformations on the data to do it in a certain way.
I say “whoever” not to be vague, but because the person doing this work can vary from company to company – it might be a data engineer, or data architect, or data analyst… or it could be an organization’s only data person.
It’s kind of hard to describe dbt because, like some of the best inventions, it’s great because it’s so… simple. dbt Labs CEO Tristan Handy describes it as a tool that “enables data analysts and engineers to transform data in their warehouses more effectively.” I would add to that: it enables the work to happen in a way that’s more manageable and intuitive than existing processes.
Maybe it’s best to first describe what it’s like to do data transformations without dbt. Normally, data transformations are carried out according to workflows determined by the data team. The languages are usually a combination of SQL and Python, maybe some Java or C++ … Often, the choice of workflows and languages are ad-hoc, depending on the skills of the team members.
If you think that sounds chaotic, you’re right – it can be. And that’s where dbt can be brought in.
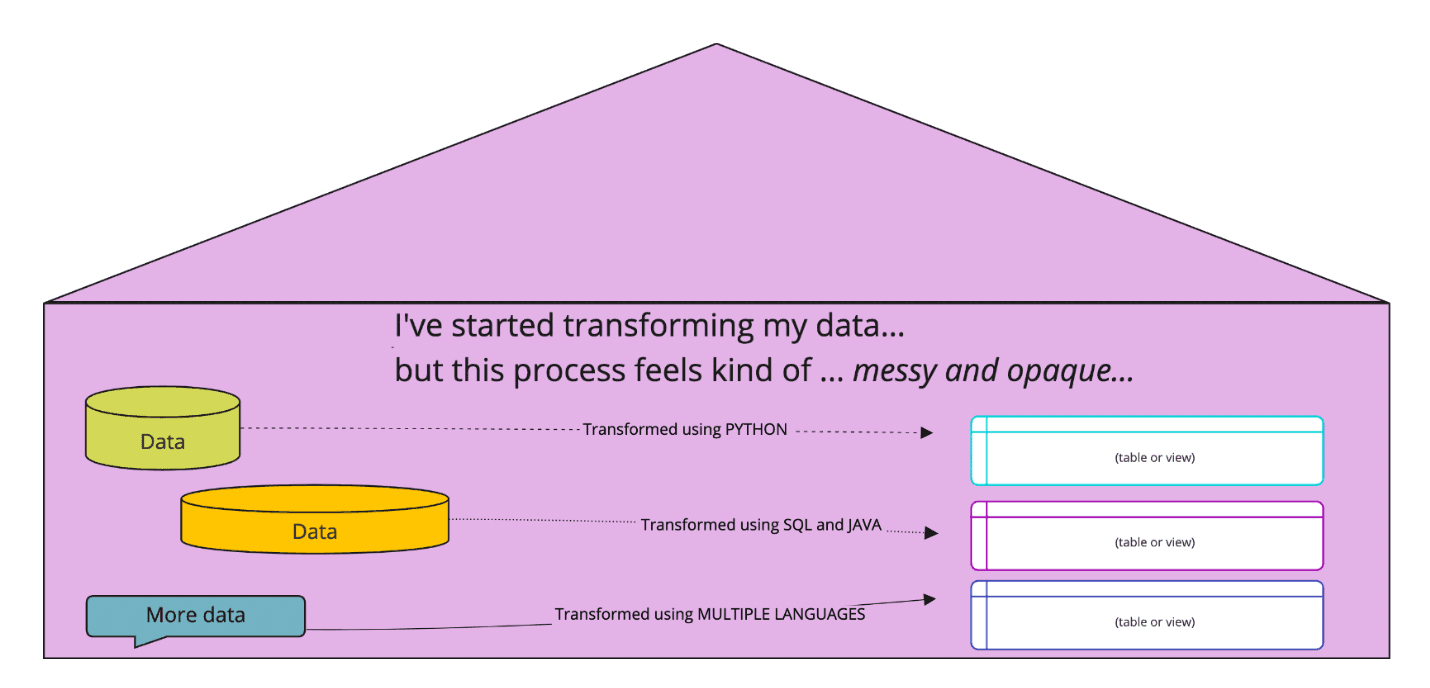
dbt brings uniformity and coherence to this mess. It enables the Data Transformers🦸™️ (yes I just made up that job title) to do all their work in the language that’s generally most widely-known across a data team: SQL.
With dbt, the work of data transformations – getting all the data into the right formats, and presented in tables and views that are the most useful for analysis – is all happening in the same language, one that everyone on your team speaks. That includes even the most sophisticated data modeling (transforming and joining the data in ways that make sense for your business).
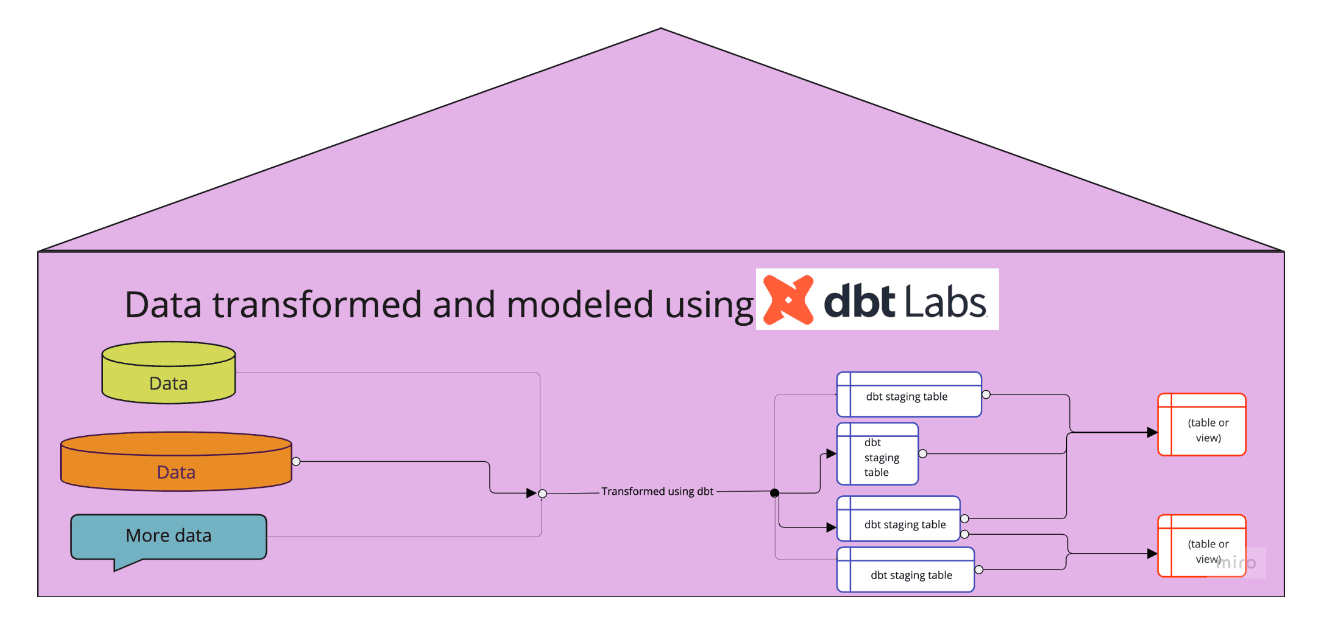
But that’s not all. dbt is like the overly-strict nanny that forces everyone in the family to develop amazing organizational habits. (At first, you can’t stand the nanny - because she wants you to change how you have always played, d**nit! But, you quickly learn that it’s for your own benefit, and that you’ll make a lot more friends if you follow her rules).
For starters, dbt encourages you to write your SQL scripts in a modular fashion. That’s to say, rather than writing a mile-long SQL script that no one but you and the computer can make sense of, you are able to break that script up into logical chunks (or “staging tables”).
This makes your script not only more approachable by your co-workers, but also reusable: you, and other members of your team, can take these foundational staging tables and build off of them – rather than starting from source data with every new project. As your team gets better at dbt, they can also develop lots of ways of sharing their work and leveraging dbt work done by others – by building and using dbt macros and packages.
Modularity is just one of many software engineering practices that dbt applies to data work. The dbt workflow also allows you– or kind of forces you – to do testing, version control, continuous integration/continuous deployment (CI/CD), and documentation.
There’s more to it, of course, but that’s enough background to get you started!
Maybe just one more thing: the people who use dbt are not actually called Data Transformers🦸™️. They are still data engineers or data architects or data analysts. But, thanks to dbt having shone the spotlight on the work of data transformation, a new job category has emerged for people whose main focus is this work: "Analytics Engineer." Business Insider published a great piece looking at the growing use of this title.

You want to learn dbt? Here’s where to start…
I knew that I wanted to start learning dbt, and I also knew that in my new job at Hightouch I would soon need to know how to work in dbt.
Here’s the learning path I’ve followed so far…
First step: Udemy course
When I want to learn any technical skill, I take the same course of action as – well – probably all of you other wonderful people who work in tech or data. I head to Udemy and search for the top-rated course in that skill. I then look at the price, say to myself “no way am I paying $89.99,” then log back in late on Saturday night and purchase the course at the weekend discount of $13.99.
In this case, that course was titled “Analytics Engineering Bootcamp,” with a ranking of 4.5/5 stars and taught by Rahul Prasad and David Badovinac.
The reason I was drawn to this course, besides the high ratings: the curriculum makes it clear that it’s not focused just on learning dbt, but also on providing a solid background in the history of data infrastructure. Like many of us, my education in this topic thus far had been scattered; I knew the history of databases and SQL, but not much beyond that.
What the course consists of:
- What is a database?
- What is a data warehouse?
- Data modeling and ERD notations
- Normalization and denormalization
- Data warehouse design and methodologies
- Dimensional modeling
- Hand-on dbt: building a dimensional data warehouse.
There are a total of eleven hours of videos, but the instructors suggest watching at 1.2 speed; I watched most of them at 1.5 speed, and skipped the lectures covering topics I already knew. Then, I stopped before the final section, which covers dbt. This was partly because it’s illegal to actually complete a Udemy course 🚫, but also because I knew that dbt labs offers its own introductory courses – and I thought it would be best to learn the software itself straight from the horse's mouth...

Second step: Free certification offered by dbt labs
dbt Labs offers five free courses on its website. You might be thinking: wouldn’t that have been the most obvious place to start? My answer: yes, it’s perfectly fine to start here, especially if you already have a solid knowledge of data infrastructure. I’m someone who tends to over-research things, and before learning the tool I wanted a deeper understanding of why the tool was created.
These are the five courses that dbt labs offers:
- dbt fundamentals
- Jinja, macros, packages
- Advanced materializations
- Analyses & seeds
- Refactoring SQL for modularity.
I took the “dbt fundamentals” course, which takes about five hours to complete. What I liked: it doesn't require any technical knowledge beyond SQL, and it offers great explanations of what some might consider basic topics. Without “dumbing down” the concepts, the main instructor (Kyle Coapman) offers clear definitions of terms ranging from data warehousing and data modeling to modularity and version control.
The course walks you through how to do a project, which you can set up and do on your own machine:
- Building your first model
- How to set up your data sources
- Documentation: how to do it and why it matters
- How to set up tests
- Deployment.
My advice for the introductory course: start by skipping to the end of each section and taking the quiz. That will give you a sense of what terms and processes you really need to focus on.
Third step: do your own projects, or take an additional course
With just those two courses under my belt, I was able to start working in dbt on the job, building my own basic model. I plan to now take the dbt Labs “Refactoring SQL for modularity” course, and have also enrolled in an online class with a live instructor, offered by Co:rise (details below).
If you’re on the job, try doing your own projects – there’s no better way to learn than working with real data and trying to create or solve real business logic. If that’s not possible, or if you don’t feel ready to dive in but definitely want to pursue your learning, here are a few paid courses to check out:
-
The playbook for dbt, by Kahan Data Solutions. A 4-hour digital course. I don’t know anyone who has taken this, but I like the instructor’s YouTube videos on dbt and other data engineering topics, so it sounds promising. Cost: $120.
-
Analytics Engineering with dbt, by Co:rise. A 4-week part-time course taught by Emily Hawkins, Data Engineering manager at Drizly. I signed up for this course, on the recommendation of a co-worker. I’m starting this week, and I’ll report back on how it goes. Cost: $400.
-
Analytics Engineering Club. A 10-week, part-time course designed and taught by Claire Carroll, formerly of dbt and currently at Hex. I’ve heard only positive reviews of this course, and if you’re curious about it, I can put you in touch with some alumni. Cost: $4,000 (in other words, maybe get your employer’s professional development fund to pay for it).
If you’ve taken any of these courses, or if you have other resources to recommend on how to get your dbt on, I’d love to hear from you - drop me a note, mary@hightouch.com.
Shout-out to Brooklyn Data's Rebecca Sanjabi and some other very wise dbt brains over on the Data Angels Slack community, for kindly sharing their insights with me.

















