
Introduction
Five years ago, Jeff Magnusson of Stitch Fix wrote one of the seminal posts that paved the way for how data teams are built. His blueprint for changing the relationship between data engineers and data scientists resonated heavily and it's still a blog post I share with anyone who asks.
In short, his approach was to change the data team dynamic of an assembly line into a more creative process. Data Scientists would no longer chuck their models over the fence for a Data Engineer to make production-ready; instead, both roles would be empowered through autonomy.
Data Scientists would write end-to-end models without waiting on a Data Engineer for implementation, who, on the other hand, would build a platform that enables Data Scientists to embrace that autonomy.
This guide builds upon these ideas to shed light on the state of data engineering today and the rise of Reverse ETL as a core component of the Modern Data Stack. If the term “Reverse ETL” sounds foreign, I’d highly encourage you to read this piece which provides a simple yet thorough breakdown of what Reverse ETL is.
The changing landscape of data
In the five years since Jeff’s post, there has also been a shift in how data platforms are used and organized at companies, big and small.
Many years ago, I worked at a large bank that had invested in a proprietary data warehouse offered by one of the two companies that worked on data at that scale. We had large teams of ETL engineers, QA analysts, and long lead-times for any development effort of even small changes.
Redshift, along with Hadoop and Airflow, changed the landscape of data processing. Using commodity hardware and scalable cloud infrastructure, the data space shifted away from expensive and difficult to simply difficult.
Hadoop was still not easy to maintain and no one quite knew how Spark clusters worked or why they'd fail, but we did manage to move large amounts of data from source systems into cloud-based warehouses to drive analytic work.
Warehouses powering data science
Once we had this centralized store of data, the next step was to run data science models off these datasets. Airbnb's data infrastructure was a typical example of the state of data in 2016. The Data Warehouse was largely used to enable analytic work, centered around powering data science models and business intelligence reporting.
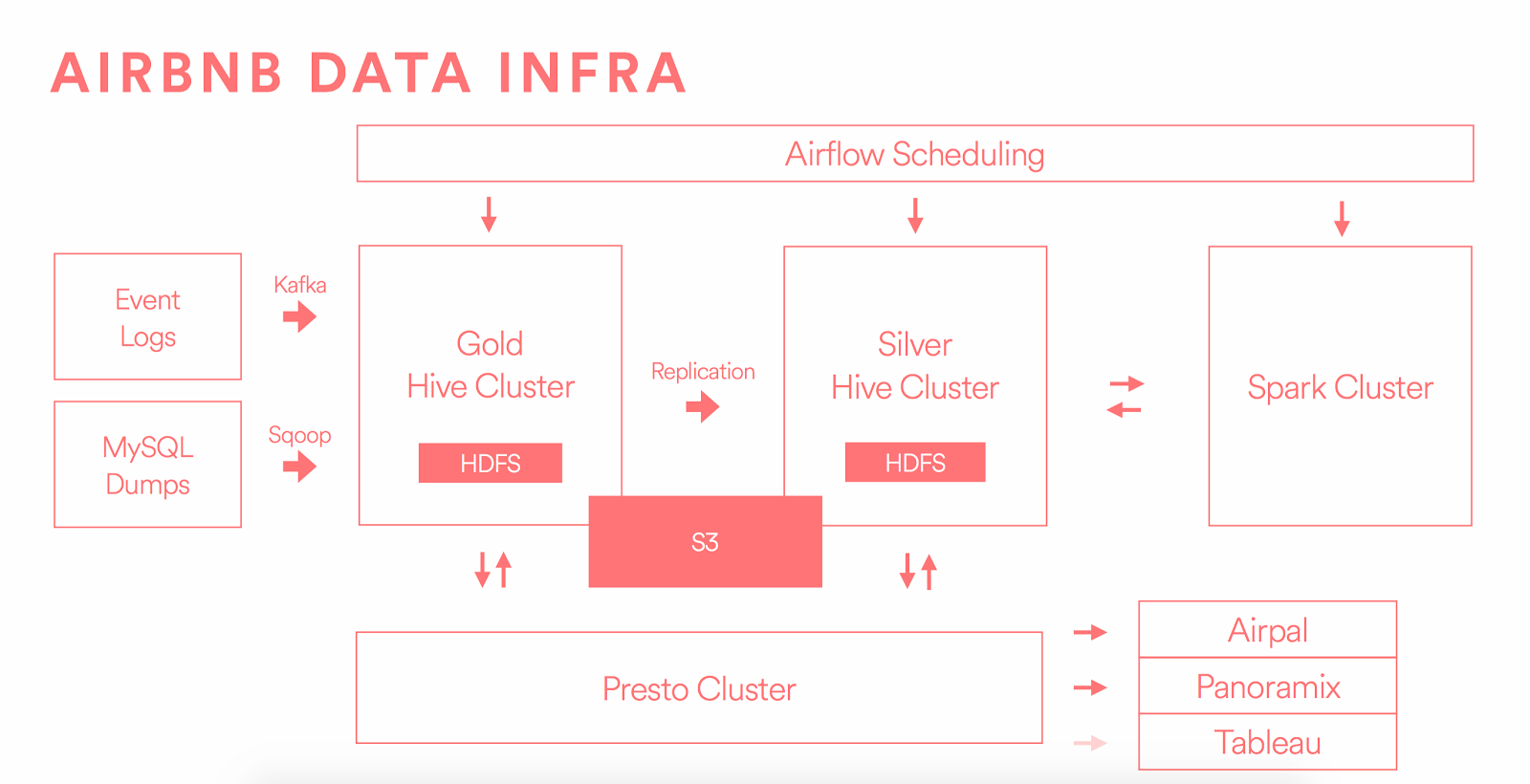
With the rise of cloud-based data warehouses such as Redshift, and later BigQuery and Snowflake, a new paradigm was beginning to emerge. Data Warehouses weren't only catering to large enterprises or high-growth startups with big data needs, but were also proving to be valuable for smaller companies that began exploring warehousing use cases that could not be handled by relational databases.
In those days, setting up a data warehouse used to take several teams and weeks or months of planning but today, a data engineer can alone sync production data into a newly built warehouse within a weekend.
Warehouses getting democratized
Building reports to answer questions that rely on product data is one of the most common reasons companies collect data. But deceptively simple questions — how many users visited the website, what did they buy, for how much, and how much money we made — often involved complex queries against production databases.
Conflicts between engineering and business teams began as soon as a product evolved and engineering would make schema changes whereas evolving business logic requires ongoing maintenance of SQL queries.
The data warehouse soon became a natural fit for adding a layer of separation between production databases and operational use cases behind a clear interface. Mirroring the same fundamentals of good software engineering practices, new tools sought to bring a new approach to managing the complexities of data.
The rapid adoption of dbt (data build tool) as a way to manage the business logic using template-based SQL workflows that build iteratively on each other brought a rapid adoption of the warehouse as a central-store of information.
The business logic that captures the complexity of any business can now be version-controlled and managed centrally through git without being confined to archaic undecipherable proc queries that we can only hope no one accidentally clobbers.
Data from other sources — payment processors, CRMs, messaging tools, and advertising channels to name a few — soon started making their way into the warehouse. And analytics engineers started to integrate data from disparate sources to provide a holistic view of customer activity across multiple touchpoints, making the data warehouse the main abstraction over the complexities of business logic.
The promise of data integrations
With this promise of offering a unified view of customers, the warehouse was fast becoming the new source of truth or system of record and was no longer limited to driving data science models or large batch jobs. This created a rapid surge in demand for warehousing solutions as well as the data itself that was being warehoused.
What the expectations were: Faster access to data
Sales wants data about the customer journey in Salesforce to help drive their customer conversations, Finance wants transactional data in their ERP tools to automate reporting, and Marketing wants to track prospects and qualified leads for automated email campaigns.
People in Ops began to push engineering for more and more data integrations, but since engineering was focused on building a product, data engineers were hired to help build and maintain the much-needed integrations. However, hiring, as you know, was slow and the backlog continued to grow.
Frustrated with delays, ops professionals resorted to what they knew best -- data extractions from the warehouse to create CSV files. Manually updating source systems with data from the warehouse became commonplace, and soon, the source of truth depended on one’s definition of the truth.
No-code solutions enabling point-to-point integrations between SaaS tools promised to bypass the engineering effort by offering visual interfaces to build complex integrations, enabling one to sync Salesforce data to an email marketing tool with a few simple clicks. However, this just led to more data quality issues -- inaccuracy, redundancy, loss of data, and so on.
What it resulted in: A distributed data system
The responsibilities of data engineers have grown beyond building data pipelines and platforms -- they’re also expected to handle data integrations that enable business functions.
While tools like Segment can help if a product’s data model fits that of Segment’s, companies largely end up allocating valuable engineering resources towards building, and worse, maintaining complex data integrations.
The landscape of SaaS applications that operational teams need is only growing, and with third-party APIs, there is no guarantee that any change will be backward compatible.
Point-to-point integrations can result in duplication of data, drift, and conflicts. Whether we like it or not, we've built a distributed data system consisting of an array of third-party services, loosely stitched together.
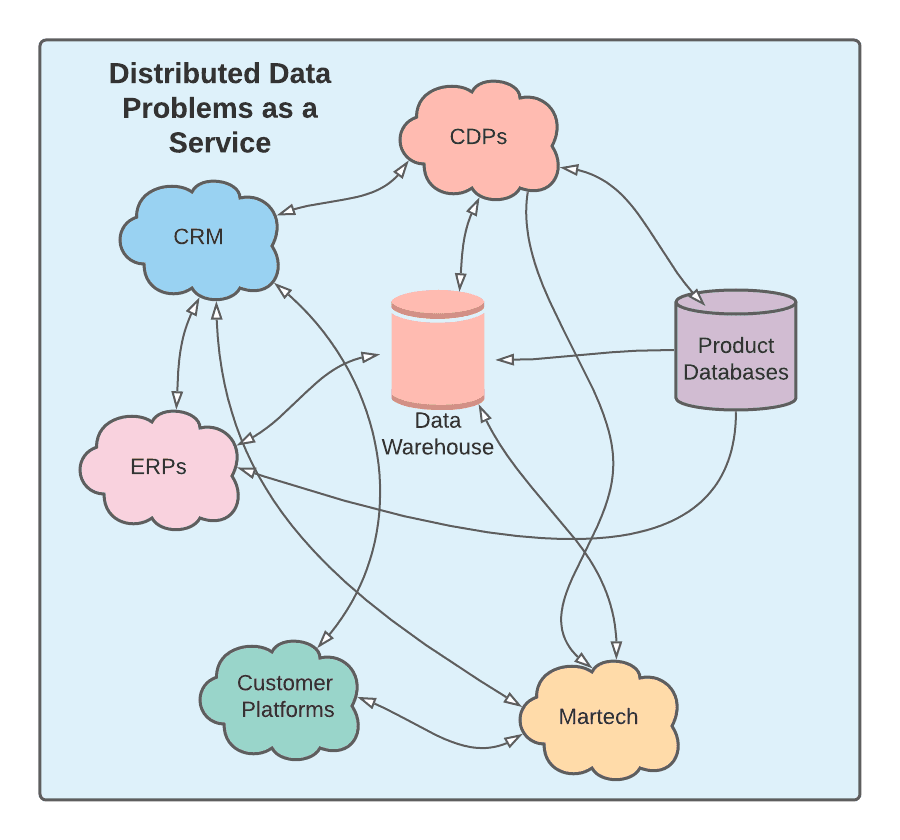
Data engineers are now spending more time on building and maintaining integrations than on building core infrastructure to move key data through internal systems.
Business rules and logic, rather than being centralized, are haphazardly applied throughout a distributed system, with all the complexity that comes with one: ordering, availability, and performance.
What's worse? This isn’t a deliberate design choice; it’s an architectural consequence of the lack of a well-thought-out design system.
The happy path
Breaking the barriers of a distributed system requires data engineering teams to mediate the production and consumption of data through the data warehouse.
This enables easier integration of data across various systems and makes the data warehouse the source of truth. The complexity of business logic can be handled through the power of SQL, in conjunction with a solution like dbt.
Instead of fighting with a simplified GUI filter to, for example, remove test accounts from an email platform, one can perform filtering at the source, and propagate that change to all downstream models.
While tools like Fivetran and Stitch have made integrating data from various source systems into your warehouse easy, a remaining complexity is how to pull data from the warehouse back into these sources, and there are factors that make this reverse process non-trivial.
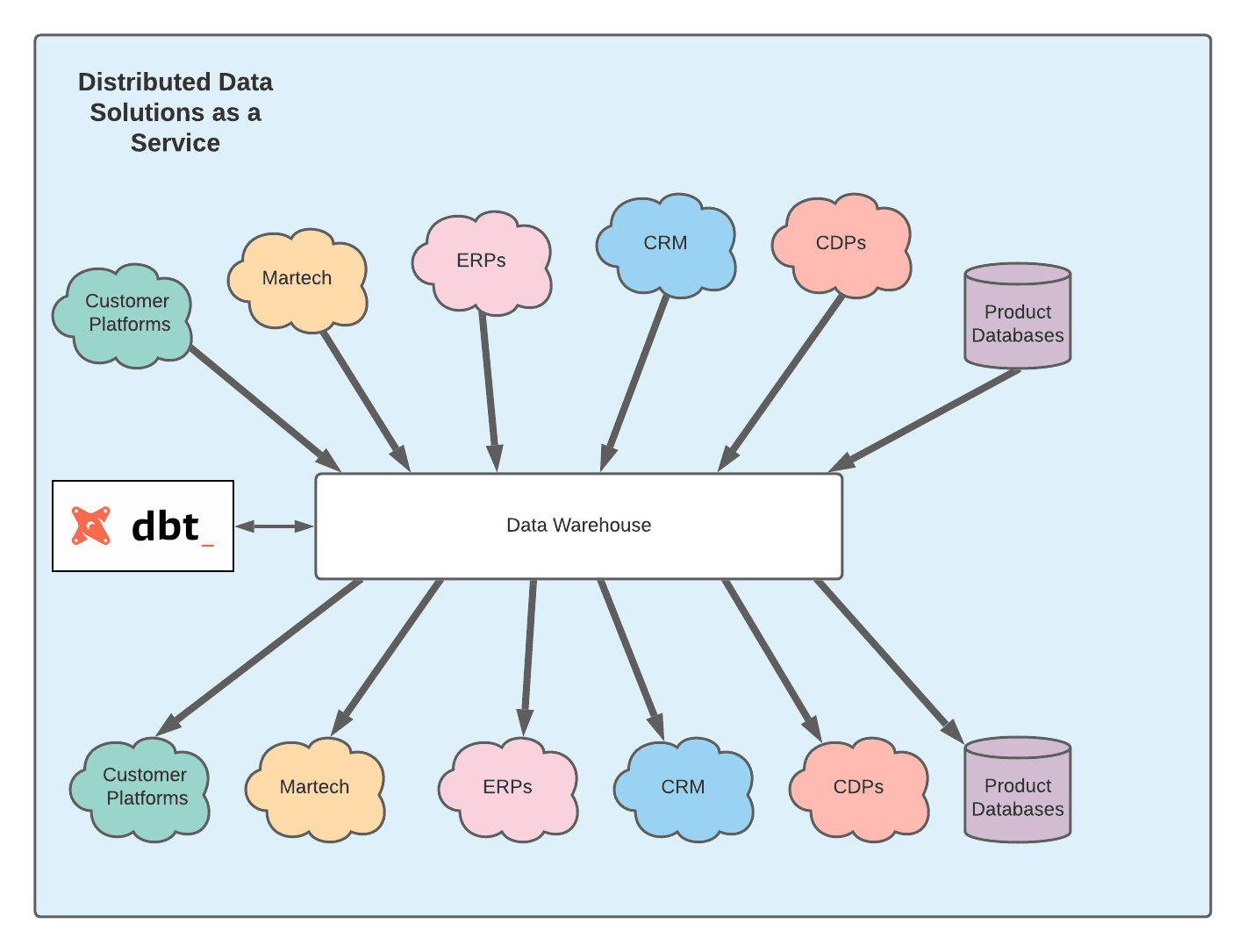
Reverse ETL: The last mile in the Modern Data Stack
Reverse ETL addresses the need to take data from the centralized store of information that is the data warehouse, and make that data available across the various internal and external systems that businesses rely on.
In other words, Reverse ETL is the answer to the question -- how can data in the warehouse be operationalized to make it available everywhere business teams need it?
Reverse ETL entails the following steps:
- Extracting data defined in a model from the data warehouse
- Figuring out what has changed since the last sync
- Translating that from the model to conform to the various models of different APIs
- And making sure that data is sent correctly and only once to the downstream systems
One can build these integrations internally but to paraphrase what Jeff Magnusson once said, “engineers should not be writing Reverse ETL”.
Nobody likes to build integrations
Maintaining data integrations with third-party services seems simple on the surface but is far from it -- managing APIs, keeping up with API changes, dealing with errors and retry logic, and accommodating an ever-increasing SaaS landscape. It is time-consuming, not rewarding, and leads to frustration for engineers
Engineers don't want to write ETL jobs, and they don't want to write Reverse ETL jobs either. Period.
Enter Hightouch!
Built by former Segment employees, Hightouch offers a simple interface to integrate data from your warehouse with third-party SaaS tools using the same SQL-powered logic that powers your business.
Let Hightough’s team of engineers solve data integration woes so that the suffering starts and ends with them, and your engineers can focus on solving problems core to your business.
Freedom isn't limited to just engineers -- folks in operations, marketing, and sales are no longer constrained by the availability of engineers to provide superior customer experiences by having access to customer data in the tools they use everyday.
Conclusion
At Hightouch, we see Reverse ETL not only as the next logical step in the evolution of the modern data stack, but also as part of an acknowledgement that we need to design our systems to best support the people who work on them.
The more we can move tedious, uninspiring work away from the hands of highly-skilled and creative people, and the more we can enable them to do what they do best, the better it is for the companies we run.
What makes great analytics engineers is empathy for users and the ability to build meaningful data models that help drive business value. Nobody said that it involves maintaining CI pipelines and dbt has done a great job at offloading that concern through its cloud offering.
Similarly, what makes a great data engineer is a passion to build useful frameworks and abstractions that help others do their jobs more efficiently without having to worry about the underlying infrastructure. It involves maintaining brittle Reverse ETL pipelines from a data warehouse to third-party data providers -- said nobody.
Hightouch aims to offload that concern so that data engineers can do what they do best, nothing less.

















