
SaaS makes the world go round. To the point where in 2021, the average company reported using an average of 110 SaaS applications 😳. While the explosion in SaaS tooling and adoption has freed up time for organizations to focus on their core differentiators, it has also led to an unintended consequence: data silos.
And so, data integration vendors emerged to address this problem.
You can read our rundown of the data integration landscape here.
The data integration space continues to evolve rapidly, and this post is meant to serve as a guide to help you better understand two specific approaches—iPaaS and Reverse ETL—so you can evaluate which is right for your business.
The iPaaS Approach
Integration Platform as a Service (or iPaaS) solutions have risen in popularity over the past decade (with multiple unicorn exits, including Mulesoft to Salesforce and Boomi to Dell).
iPaaS solutions are either low-code or no-code software platforms that enable companies to connect various applications via their APIs without managing servers or writing complex code. They are programmed to perform actions based on specific triggers (if this, then that). A trigger is an event that takes place in one system (e.g., contact created, email opened, new signup, page viewed, etc.) that is then transmitted to an integration platform (via an API call or webhook). Once an event is triggered, iPaaS tools kick off predefined actions (e.g., send Slack a message, update Stripe subscription data, etc.). Typically, these workflows involve multiple layers and dependencies to run properly. The idea behind iPaaS solutions is to allow companies to integrate different applications without needing software engineers.
Examples of iPaaS vendors include Zapier, Workato, Tray.io, Celigo, Mulesoft (Salesforce), and Boomi (Dell).
Benefits:
- Relatively easy to use (for straightforward use cases)
- No-code/visual interface (drag-and-drop)
- Numerous integrations (varies by vendor)
Shortcomings:
- Brittle: pipelines often break, requiring engineering maintenance
- Lack of scalability: must start from scratch with every new integration
- Complexity: workflows can quickly become long and complex
- Not universal: limited to event-driven workflows
- Security and governance: not centralized in point-to-point architecture
Many iPaaS vendors were founded over a decade ago, well before data warehouses were made mainstream by the emergence of cloud data warehouses like Snowflake. In their wake, a new data integration strategy has emerged to sync data into operational tools: Reverse ETL.
Reverse ETL: An Alternate Paradigm
Reverse ETL is the process of using batch-based data pipelines to sync data from your central data warehouse to your operational tools, including but not limited to SaaS tools used for growth, marketing, sales, and support. In essence, this data movement is technically data integration much like ETL, but because it’s a relatively new behavior (egress from the data warehouse), many of our earliest customers found it most intuitive to call it “the opposite” of their ETL pipelines (which enabled ingress into the data warehouse).
At a high level, the fundamental difference between iPaaS and Reverse ETL is their architectural approach. iPaaS follows a point-to-point approach while Reverse ETL follows a hub-and-spoke framework, with the warehouse being at the center of all workflows.
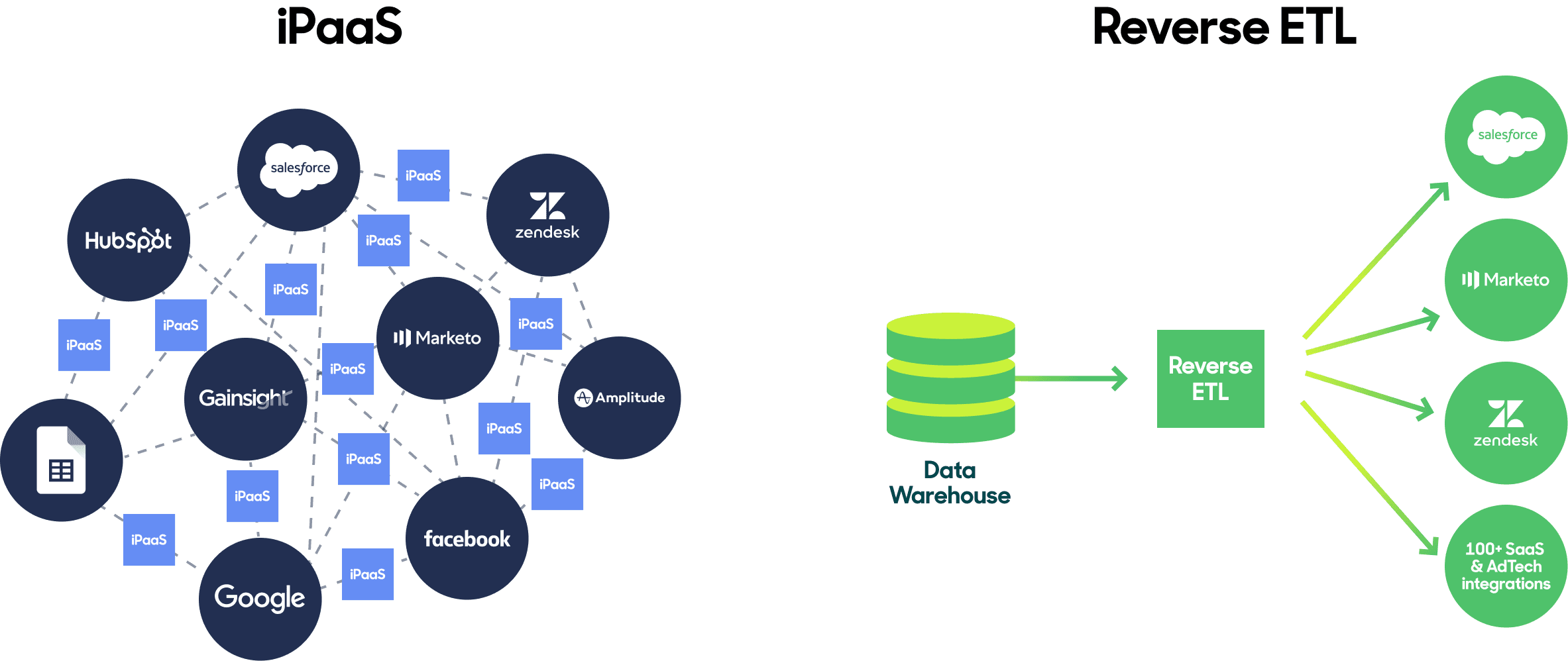
iPaaS architecture vs. Reverse ETL architecture
As you can see in the visual above, iPaaS can introduce an exponentially growing spiderweb of point-to-point integrations into your tech stack, simply because each data source needs to be integrated into every data destination. With iPaaS, you may find yourself syncing Hubspot data to a half dozen destinations. With Reverse ETL, that architecture is streamlined by leveraging the data warehouse as the data hub.
Understanding How Reverse ETL Stacks Up Against iPaaS
We’ve obviously written extensively about Reverse ETL, but when comparing it to a point-to-point approach of iPaaS solutions, a good way to think about the two is the method in which they get data to the desired endpoint.
- iPaaS follows step-by-step directions to get from point A to point B. These instructions are dictated by the user, typically in the form of coding in a web UI (e.g., IF/THEN statements to call APIs).
- Reverse ETL takes the inverse approach. Rather than requiring the user to provide specific steps to get to the desired endpoint, the user simply needs to declare their desired end state. (e.g., sync data into Salesforce, with this explicit mapping and configuration).
Here’s an everyday analogy: Let’s say you wanted to get from your hotel from Union Square in San Francisco to the Ferry Building. If you were using an iPaaS solution to make it happen (roll with me here 😉), you’d have to tell the tool exactly the steps needed to get there (e.g., walk outside, turn right, walk 0.3 miles, turn left, go straight 0.4 miles, cross the railroad tracks, collect $200, you have arrived at your destination). With iPaaS solutions, the focus is on verbs and actions.

The iPaaS Approach
In a Reverse ETL construct, that express route has already been pre-built for you. Simply state that you want to get to the Ferry Building from your origin point of Union Square (with some mapping between the two), and get on board. Because the Reverse ETL vendor has pre-built clean integration paths for you, all of the complexity is abstracted away. With Reverse ETL solutions, the focus is on the nouns.
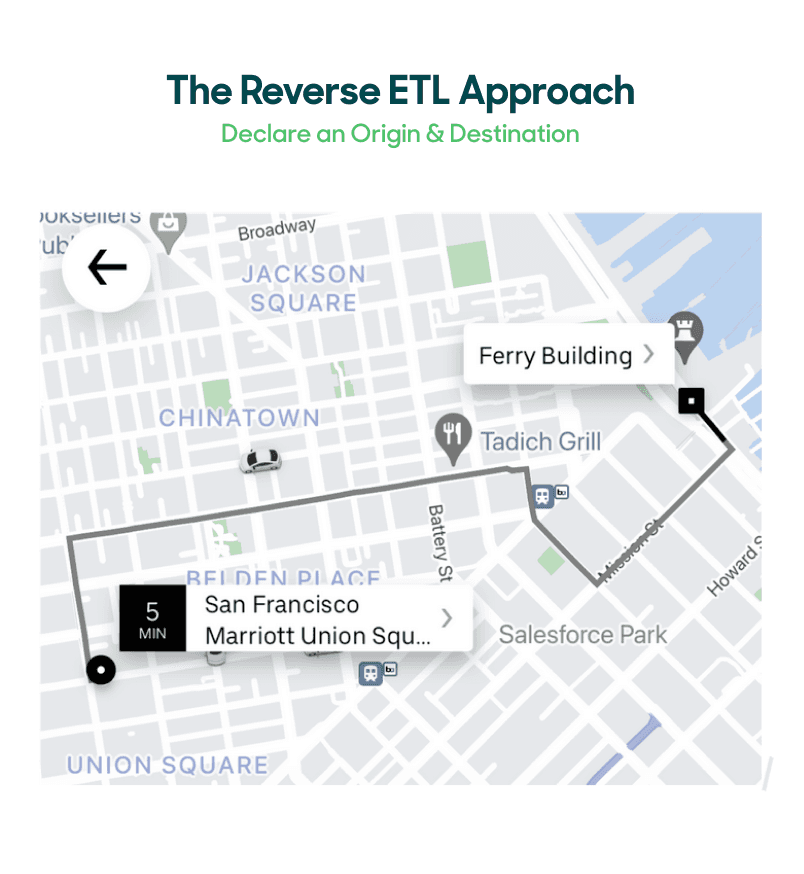
The Reverse ETL Approach
This obviously wasn’t a very technical analogy, but hopefully helps you understand the architectural differences between the two approaches. We wrote a blog post on the topic that dives into what this step-by-step workflow might look like in an iPaaS platform (spoiler: there are a lot of steps involved).
In technical terms, iPaaS is referred to as an imperative workflow (if this, then that), whereas Reverse ETL is a declarative workflow (declare your end-state).
Capability Comparison
Apart from their architectural approaches, a key difference between iPaaS and Reverse ETL is the method by which they process data. iPaaS tools typically leverage single record APIs to communicate updates to another tool, whereas Reverse ETL is exclusively batch-based. This gives Reverse ETL considerable advantages in terms of scalability, cost (especially at high volumes), and observability.
This distinction also allows Reverse ETL to be much more forgiving with mistakes. Because it moves data in batches, Reverse ETL provides robust management on version control and lineage of these pipelines over time. In the event of a mapping mistake, a user can quickly identify historical configuration changes, roll back to a previous state, and even revert or resync all records to a downstream destination with a few clicks. Reverting bulk record changes with an iPaaS tool can be a much more painful (and many times impossible) process.
Other important considerations include pricing and observability:
-
Pricing: iPaaS vendors often price their solutions based on the number of API calls made, which makes this approach quite expensive at high volumes. Reverse ETL vendors can vary in price, but Hightouch charges customers based on the number of destinations synced to, regardless of the number of updates (or “calls”) made to that destination.
-
Observability: With a point-to-point architecture, it becomes impossible to understand what’s happening across your tech stack at a holistic level when you’re trying to push updates on millions of records. When the logic is centered in the warehouse, observability and lineage are much more traceable, especially when all record updates are logged directly back into the warehouse.
“Our decision between iPaaS and Reverse ETL for data integration ultimately came down to simplicity, flexibility, and reliability. iPaaS solutions require a lot more resources to achieve the same result. With Hightouch, we can set up a sync from our warehouse to operational tools like Zendesk in a matter of minutes; the same data pipeline took weeks to achieve with iPaaS. Needless to say, adopting Hightouch has made a drastic difference in our resource efficiency and the productivity of our data engineering team.”

Remi Paulin
Data Architect at PrestaShop
There are pros and cons to either approach, and what’s right for your business will depend on your stage, team, tech architecture, and long-term goals. Here’s a quick breakdown of how iPaaS stacks up against Reverse ETL across various vectors:
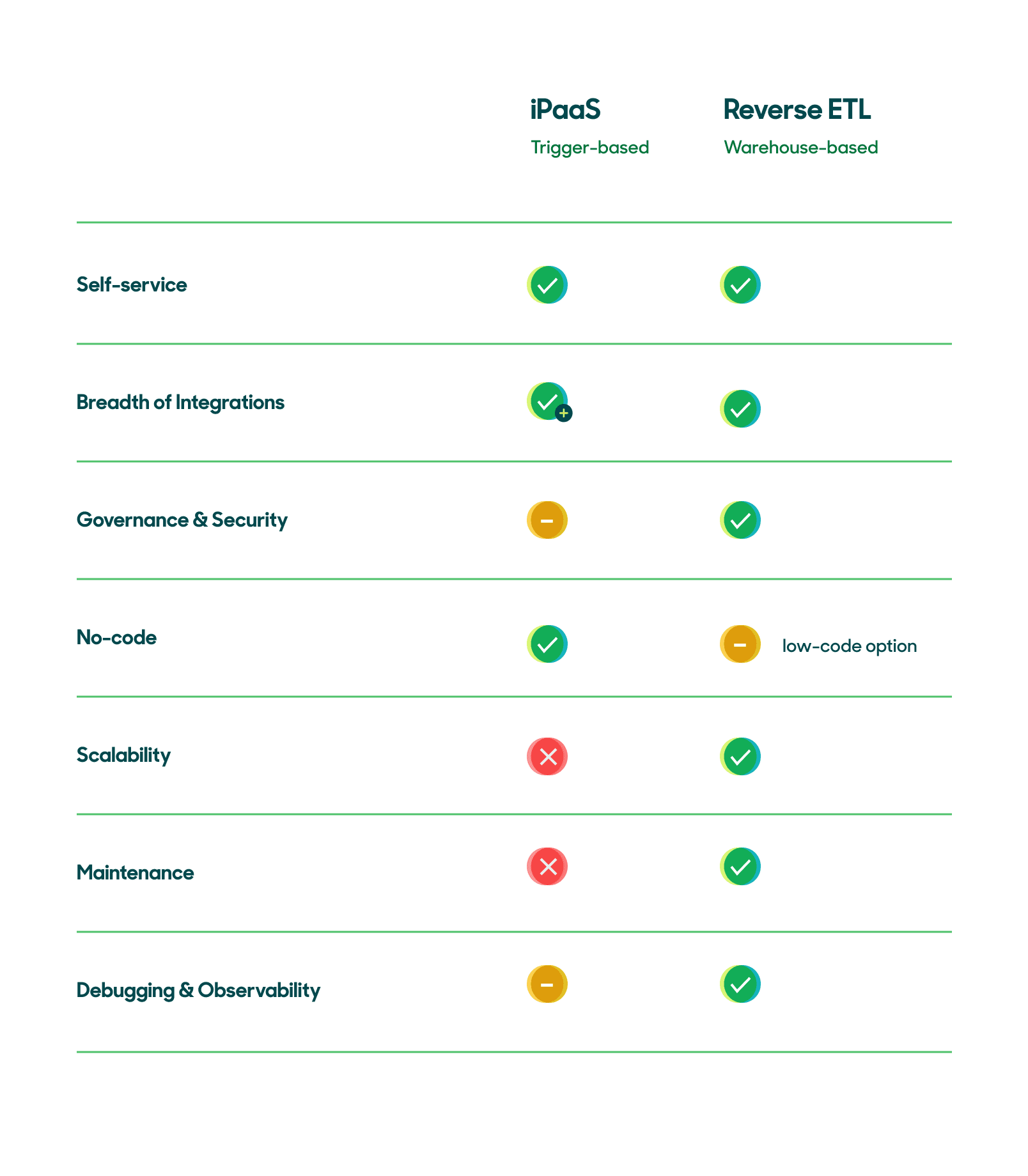
Capability comparison
Deciding Which Approach is Right for Your Team
Begin by assessing a few key questions as they relate to your business today:
- Data Architecture: Is operational data centralized in a cloud-based warehouse? If not, when is it likely to become a strategic priority for your business?
- Scale: How many go-to-market systems (e.g., Salesforce, Zendesk, Iterable, etc.) do your teams rely on?
- Data team: How many data and/or operations employees do you have?
- Budget: What’s your annual budget for data integration?
- Data posture: What’s the level of trust downstream teams have in the data they receive?
- Use cases: Have you identified high-priority data integration use cases? How will data pipelines address those problems?
In general, as your architecture, systems, and team scale, it will become increasingly onerous to rely purely on iPaaS solutions, and Reverse ETL should be considered and evaluated. From a budget and data trust standpoint, by leveraging a central source of truth (the data warehouse), Reverse ETL delivers operating efficiencies and data consistency that point-to-point solutions cannot match.
“When it comes to understanding the business and surfacing the right information to the right team, those workflows should be driven by the warehouse. It’s a very low lift to unlock that data with Reverse ETL to run experiments and drive business value quickly.”

Weston Rowley
Director of Strategy & Analytics at Lucid
Here’s a simple scorecard to help you assess what might be best for your business, given your company stage and data integration needs.
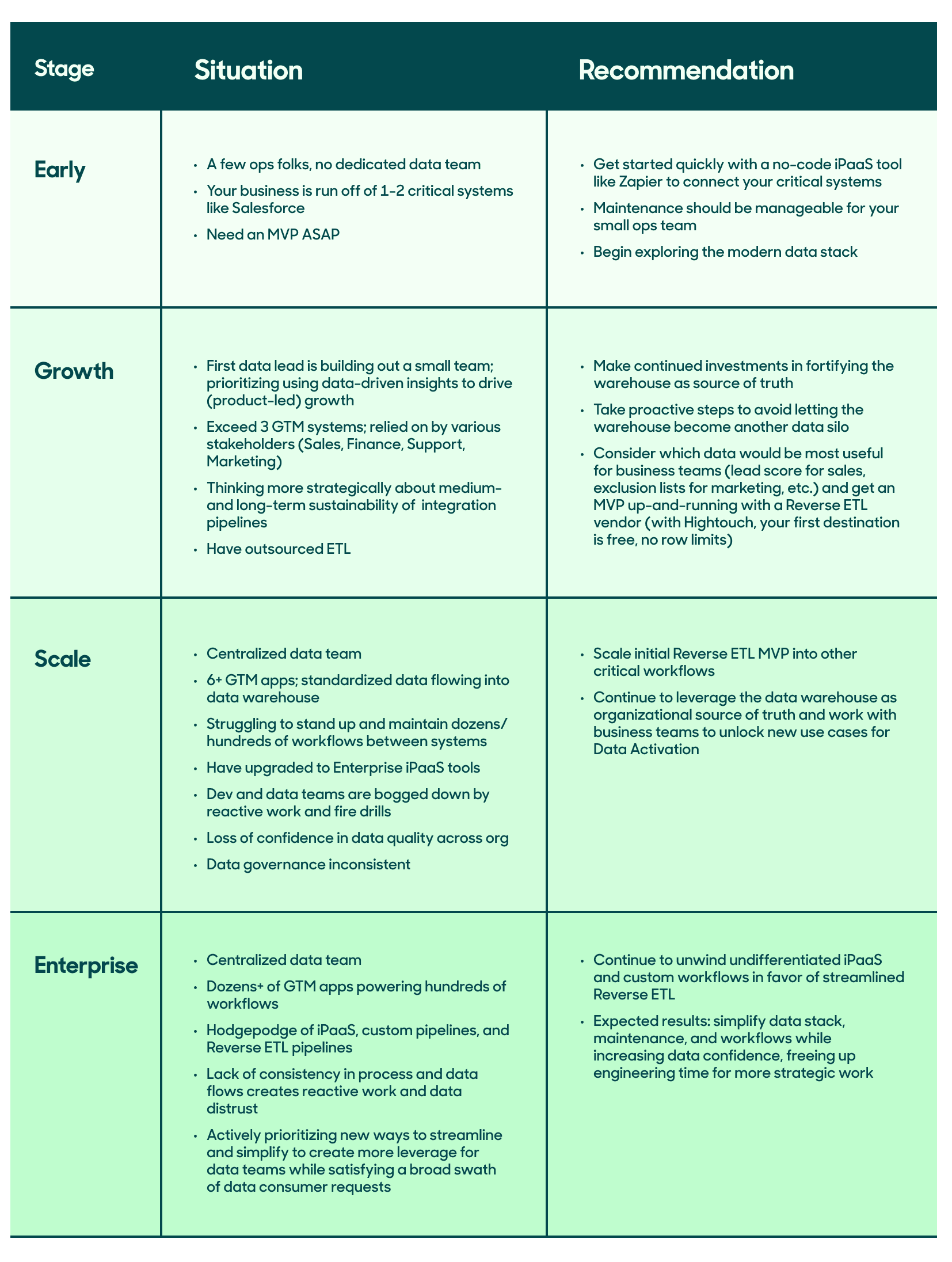
Data integration approach scorecard
Real-World Migration Models
We have many customers who have followed a similar strategy to unwind their iPaaS workflows as their systems, teams, and needs have scaled. A few recent examples:
- NWN Carousel, a cloud communications service provider, was a Workato/Celigo shop before migrating to Hightouch. The impetus? They had an onslaught of employees leaving the company because of the extra hours and manual work they had to put into using and maintaining those tools 😬. It became a big enough problem that the CIO stepped in to make a change.
- Another customer recently migrated off of Workato in favor of Reverse ETL. They were maintaining a 25-step Workato job to get data from Snowflake into Salesforce 😵. In addition to the tedious maintenance, they were frustrated at the lack of visibility into pipeline slowdowns or issues. They chose Hightouch because of the simplified architecture and deep observability features that help them understand what’s happening “under the hood” with each sync.
If you’re ready to get started with Reverse ETL, you can try out your first destination with Hightouch for free, and start syncing data into downstream tools in minutes. We’d also be happy to set up time with you to learn more about your use cases and walk through a platform demo.

















