
Chances are you've leveraged Salesforce in some capacity in your lifetime. As a customer relationship management (CRM) platform, it stores a ton of valuable data, whether it's related to individual contacts, accounts, deals, orders, products, etc. The problem is Salesforce doesn't store everything.
In many cases, there is data from external sources that you need to ingest directly into the platform to empower your business users and enrich your current data. Ingesting data into Salesforce is challenging. You're forced to either upload manual CSVs or rely on engineering teams to build and maintain custom integrations just to keep your marketing and business tools up to date with the data they need. Neither of these solutions is optimal.
What Is Salesforce Data Pipelines?
Salesforce Data Pipelines is a relatively newer product that Salesforce offers underneath CRM Analytics (formerly Tableau CRM). If you're unfamiliar with CRM Analytics, it's a suite of analytics tools that sits on top of your CRM. Salesforce Data Pipelines is a data integration feature that helps marketing teams consolidate customer data from multiple sources directly within Salesforce to create richer, more actionable customer profiles.
It's designed to simplify the process of aggregating, consolidating, and calculating core metrics about your customers. Salesforce Data Pipelines aims to help you perform simple and complex calculations on all of your data within Salesforce so you can calculate totals and create aggregations to create an enriched view of your customer.
Looking to modernize your customer data stack?
Download our Complete Guide to the Composable CDP and learn why leading companies are moving beyond traditional CDPs.

How Do Salesforce Data Pipelines Work?
There are many components to Salesforce Data Pipelines, and the solution offers several different connectors for various sources for applications, databases, object stores, etc. There are both input and output connectors. Input connectors let you ingest data into Salesforce, and output connectors allow you to activate your Salesforce data across your marketing and customer engagement tools. However, these connectors are relatively few, and there are very limited options for activating Salesforce data across your broader marketing stack and customer engagement platforms.
Within CRM Analytics, there are two core features: Data Manager and Data Prep. Data Manager is a scheduling and monitoring tool that gives you a high-level overview of every pipeline or transformation job in your Salesforce environment. Here’s an example from the Salesforce documentation.
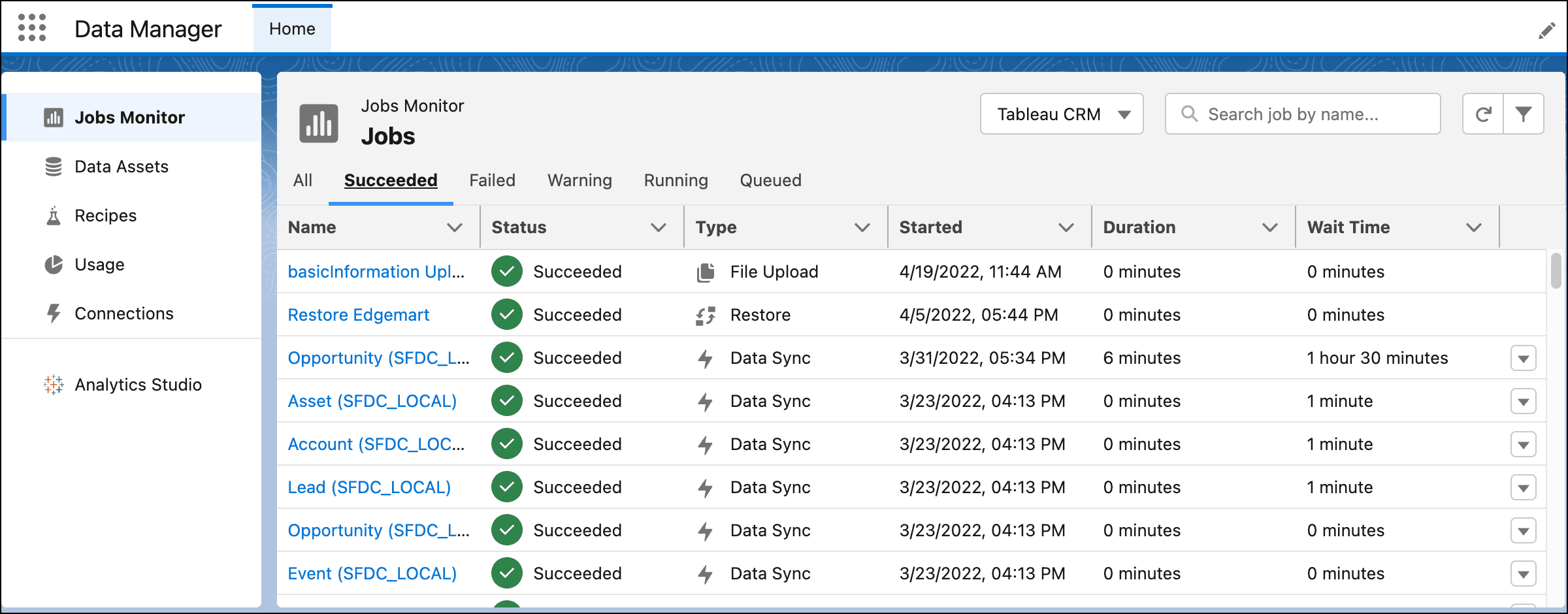
On the other hand, Data Prep is a visual UI that lets you build Recipes. These Recipes use a visual, no-code workflow builder that empowers marketers to combine, transform, and enrich customer data without relying on technical resources. Recipes can combine data from multiple sources or even transform the data within your own local Salesforce environment. Here's an example Recipe from the Salesforce documentation.
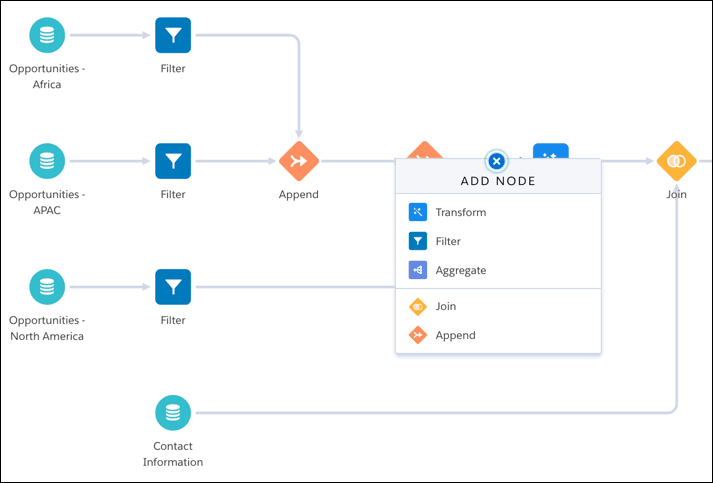
Every icon within this Recipe represents a specific node type.
- Input Nodes represent the data you bring to create a recipe.
- Aggregate nodes help roll up data to a higher level (e.g., sum, average, count.)
- Append nodes enable you to stack rows from different data sets.
- Filter nodes let you remove rows you don't need.
- Join nodes help you add columns of data from related objects to existing data in your Recipe.
- Transform nodes give you the ability to manipulate the data and standardize formats.
- Update nodes allow you to swap column values with data from another data set.
- Output nodes represent the target destination for the data results.
At their core, Recipes give you the ability to shape and manipulate your Salesforce data or combine it with data from external sources. Running a Recipe creates a new dataset or updates an existing one. Datasets can also be used as sources for other recipes.
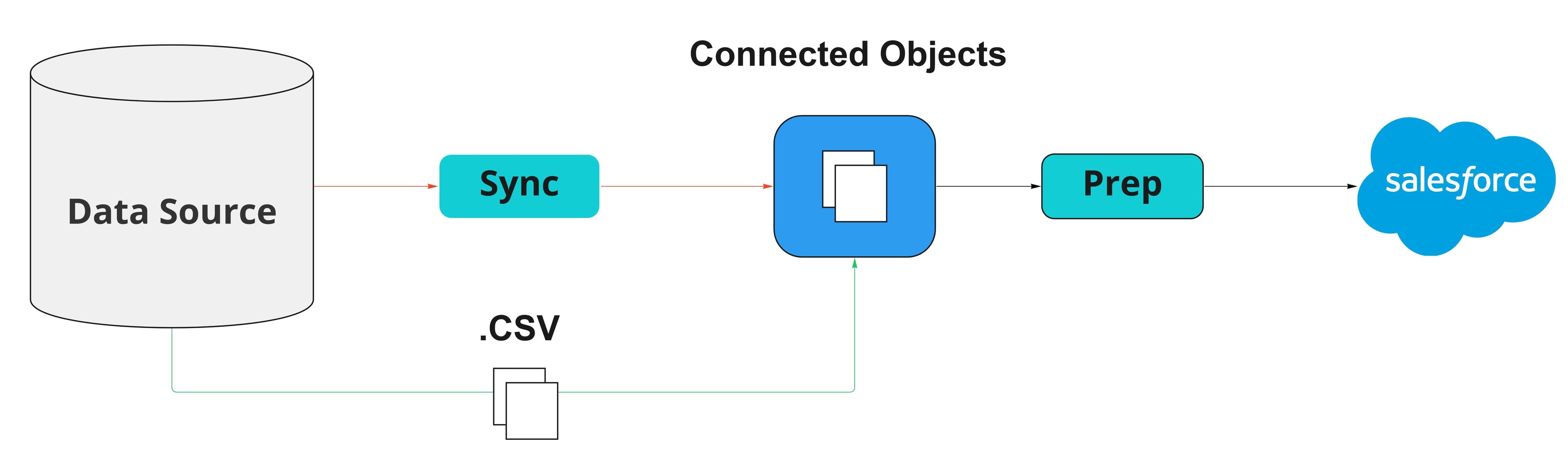
Before you can even run a recipe, you first have to create a connection between your sources. If you're transforming local Salesforce data, you can use your existing objects to fulfill this role. However, suppose you're leveraging another data source like AWS S3. In that case, you'll need to run a sync to extract data and store that information in Salesforce as a connected object for later use.
This is not exactly a simple process, and most of the time, the most straightforward workaround is to download a manual CSV file from your source and upload that to a dataset in Salesforce.
Example Use Cases
Although Salesforce Data Pipelines can be used to move and merge data from other external sources, the best use case is for your existing/local Salesforce data.
One of the most practical use cases for Salesforce Data Pipelines is standardizing your contact and account records. Since most data within Salesforce is manually input by your individual sales reps, keeping consistent formatting across your organization is nearly impossible. Manually updating fields like phone numbers, addresses, zip codes, and first/last names is a nightmare. You've seen this problem firsthand if you've ever received an email addressed to first_name or last_name. Your automation in Salesforce is only as good as the accuracy of your fields/columns.
Another example could be doing something as simple as rolling up your account level opportunities to see which regions are generating the most pipeline and which regions need additional support. You might also want to conduct correlations on the average number of meetings before a deal closes. The point is the transformation capabilities in Salesforce Data Pipelines are tailored toward BI use cases and less towards Data Activation.
- What happens if your marketing team wants to launch a nurture campaign to your most recently churned customers?
- What happens if your product team wants to tailor your in-app experiences based on key events from your website or user-related behavior?
- What happens if your sales team wants access to product usage at an account level?
- What if your support team wants to know which tickets they should be prioritizing?
- What if your finance team wants access to critical metrics like annual recurring revenue (ARR), lifetime value (LTV), monthly recurring revenue (MRR), or churn rate?
The Problem With Salesforce Data Pipelines
The premise behind Salesforce Data Pipelines is solid. However, building data pipelines and running complex transformation jobs in your CRM creates several problems because it's not a single source of truth or a true analytics platform. Salesforce Data Pipelines more closely aligns itself to a point-to-point iPaaS solution because it's based around workflows that are notably hard to scale and prone to failure. You're forced to try and balance dependencies across nodes rather than write simple SQL.
When something goes wrong in your workflow (and it inevitably will), your only option is to open a support ticket and wait for a response. In addition, Salesforce Data Pipelines focuses on ingesting raw data, which means you can't leverage any of your existing data models or core definitions your data team has built in your data warehouse (e.g., workspaces, subscriptions, LTV, ARR, MRR, etc.)
In reality, all of your data and all of the core business logic for your customers already exists in your data warehouse. After all, this is where your data analysts and engineers spend all of their time. Your data team doesn't want to learn an entirely new tool to join, aggregate, and transform your data, and they definitely don't want to use Salesforce to tackle this function.
Since Salesforce Data Pipelines is a bi-product of CRM Analytics, it lends itself to a BI tool because every time a recipe finishes running, your data is persisted into a new dataset, making it easy to visualize from an analytics perspective. The question is, do you want your single source of truth to be your CRM or your data warehouse? The answer is blindly obvious. Salesforce is a fantastic platform, but the data pipelining feature was created solely to tap into the demand of the major cloud providers.
It's just easier to write standard SQL and use the computing capabilities of a data platform like Snowflake or Databricks. Dedicated modeling/transformation tools like dbt have made it even easier to configure, manage, automate, and run your transformation jobs on top of your warehouse. And data integration or ELT (extract, transform, load) tools like Fivetran have become a no-brainer for moving data into your warehouse.
Unless you don't have a data warehouse, there's no reason to use Salesforce Data Pipelines because it completely goes against the entire premise of a data warehouse in the first place.
Alternatives to Salesforce Data Pipelines
Ultimately, you just need a tool that runs on top of your data warehouse and syncs data directly to your downstream business tools (e.g., Salesforce). This is exactly the problem Hightouch addresses with Reverse ETL. Hightouch gives your data team the complete flexibility of SQL and lets them leverage the existing data models in your warehouse.
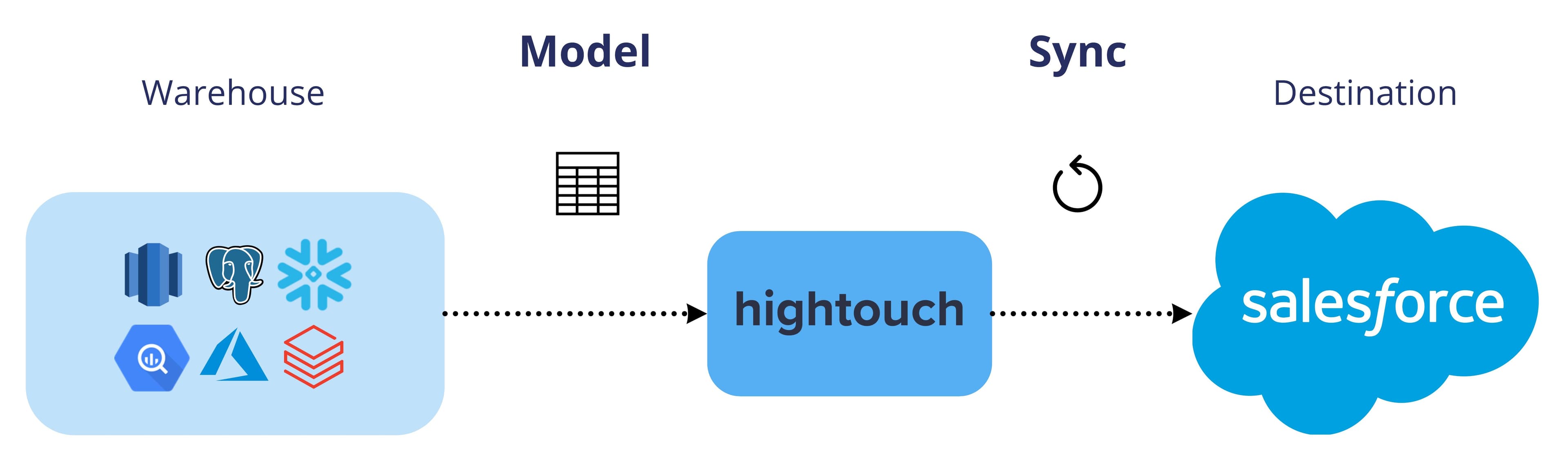
With Hightouch, you connect to your data source and map the appropriate columns to the matching fields in Salesforce or another destination of your choosing.
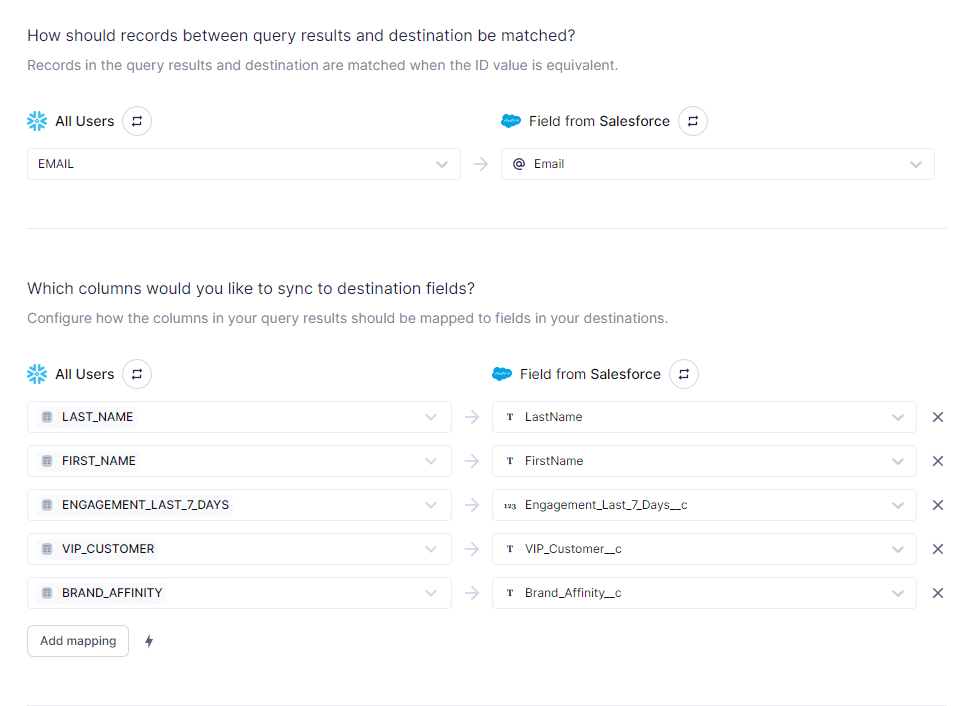
You can run your data syncs manually, schedule them to run on a set basis, or even after your transformation jobs have finished running in your warehouse.
There's also a visual audience builder that allows your business users to build custom audiences using the parameters your data team has set in place.
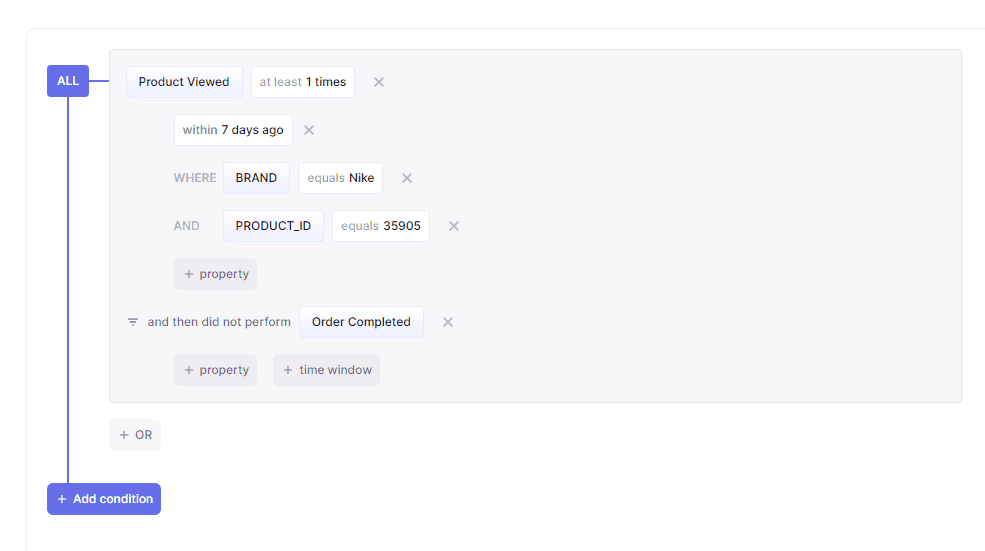
Best of all, you don't have to purchase a license to CRM Analytics. You can create a free Hightouch workspace and start syncing data to Salesforce immediately!
The future of customer data is composable
Traditional CDPs promise a single source of truth but often create silos, limit flexibility, and add complexity. A Composable CDP takes a different approach. By building on top of your existing data warehouse, you get:
- A single, trusted source of data without duplication
- Modular components that fit your current stack
- Greater flexibility and faster time-to-value
- Stronger governance and security controls
Download our Complete Guide to the Composable CDP to understand the shift, the benefits, and how leading enterprises are unlocking personalization at scale.

















