
Last updated: April 17, 2024.
When we first published this blog in 2022, we started with a hot take:
Customer Data Platforms (CDPs), as we know them, are fundamentally broken. In the next few years, every CDP vendor will either pivot their offering to a composable, warehouse-first offering or completely lose relevance in the market.
This prediction has absolutely come true. In this blog, we introduced the idea of a “Composable CDP” centered on the cloud data warehouse. It’s become the preferred way for enterprises to use customer data– and the broader CDP landscape has been scrambling to embrace Composability. Read on to see the fundamental flaws we saw killing traditional CDPs and how we introduced the Composable CDP to better meet marketers’ goals.
What is a Customer Data Platform (CDP)?
A Customer Data Platform (CDP) is an all-in-one data platform built for marketing teams. It serves as a database for all your customer information with a bundled activation layer to help you leverage your data for marketing automation.
All CDPs have at least three core components:
- Data Collection: Since CDPs are a database of customer data, they need to give you a way to send data to them. To solve this, CDPs expose an API for developers to track user traits and events users take across applications.
- Data Transformation: All CDPs usually have an out-of-the-box identity stitching functionality and tools to create custom traits on user profiles.
- Data Activation: CDPs are useless unless they help you act on your data, so they have integrations to sync enriched profiles and audience segments to marketing channels.
All of these features are bundled together in a tightly integrated all-in-one solution.
What is a Composable CDP?
Even if you’re unfamiliar with CDPs, the idea of having all your customer data collected, cleaned, and available to take action via a unified off-the-shelf platform sounds like the holy grail.
As always, the devil is in the details.
Implementing a CDP can be quite challenging, especially at an enterprise level. Because CDPs revolve around their own customer database, your product engineering team must implement data collection by tracking user traits and events across your various websites, backend services, and apps via your CDP’s APIs and SDKs. This can often take 3-6 months to start, but it is not a one-time project– it’s a continuous investment as you build new product features, data sources, and campaigns.
On top of that, CDPs cannot serve as your single source of truth. Their “cookie-cutter” data models and reliance on tracking standard user events prevent you from properly representing their business-specific data models like products, groups, coupons, artists, etc. Finally, they’re often missing critical data from outside of your applications–for example, SaaS tools like Salesforce, point-of-sale (POS) systems, and data science models that are often only in the data warehouse.
We've introduced the Composable CDP to solve these problems!
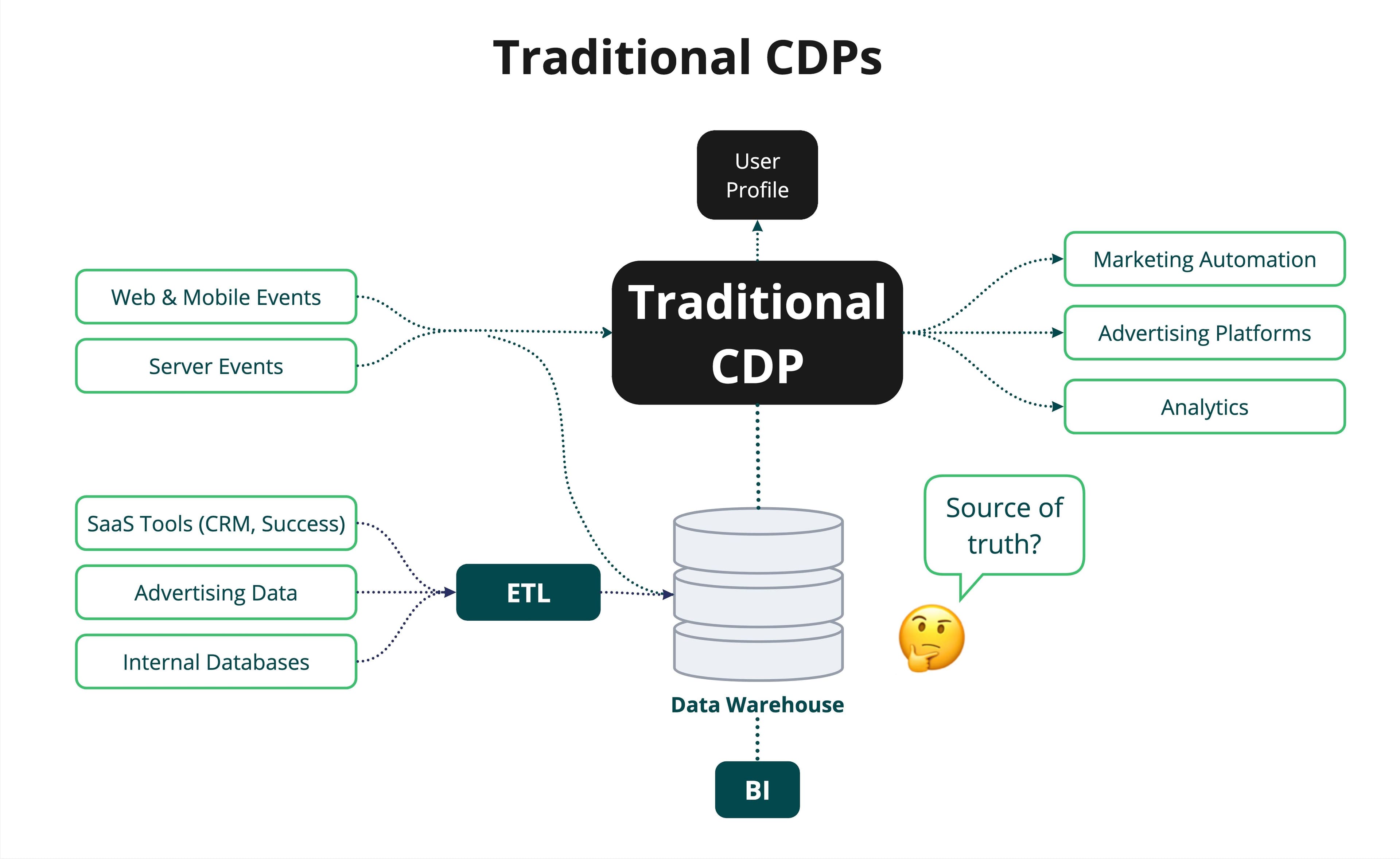
Traditional CDPs operate in a separate data silo from the Data Warehouse.
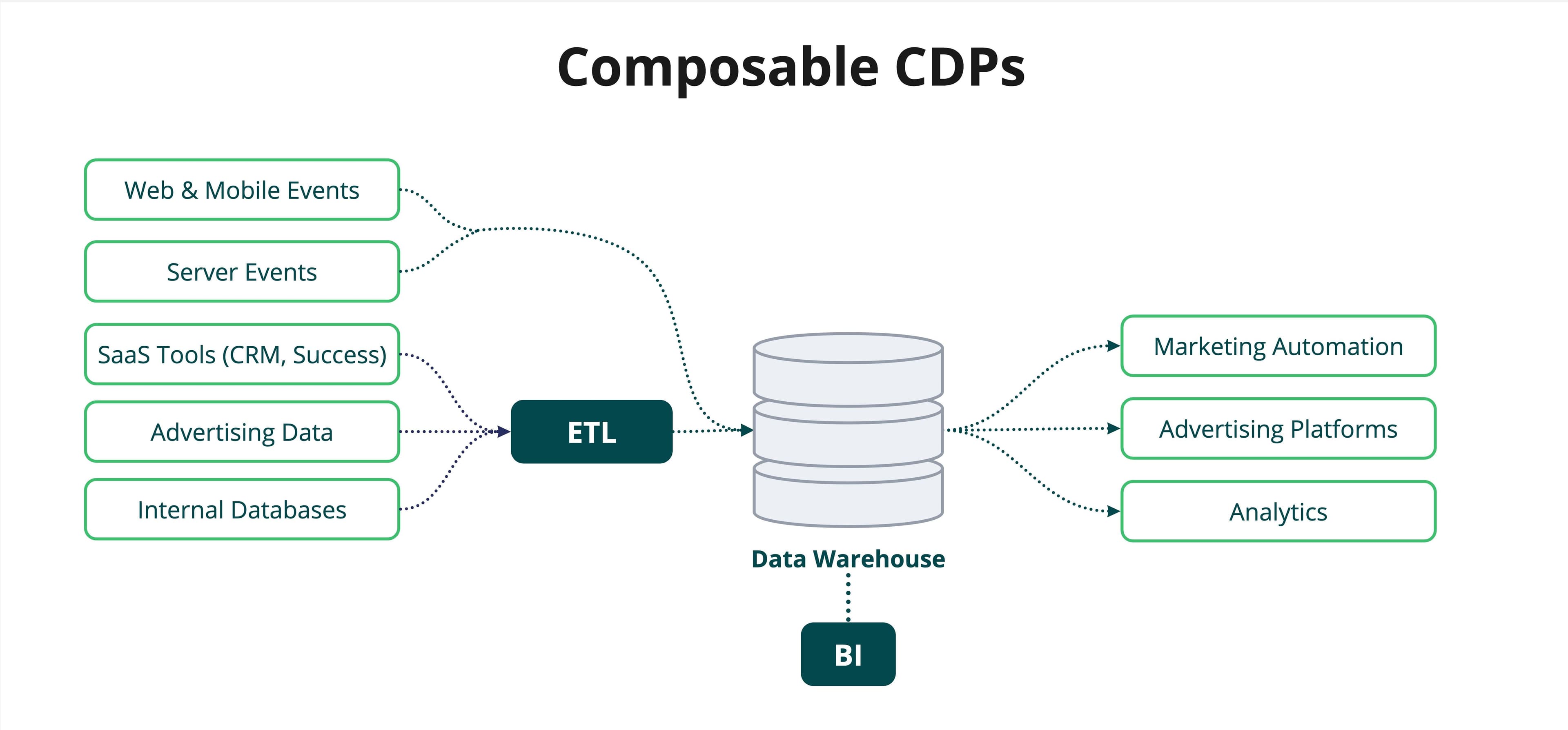
Composable CDPs operate directly from the data warehouse.
Building one source of truth is hard, so why create two? Over the last decade, every company has been investing in building out its data analytics and business intelligence practice. In almost every case, customer data from across your business is unified in a central data warehouse like Snowflake, giving marketing teams a trusted, single source of truth to power personalization and campaigns to answer critical business questions via BI tools like Looker or Tableau.
Instead of just analyzing the data in their data warehouse, companies are turning their data warehouse into a CDP and using the data within to power operational business processes like personalized marketing campaigns in tools like Salesforce, Braze, and Facebook Ads.
The Evolution of CDPs and Data Warehouses
Why weren’t CDPs always built on top of the data warehouse? Why did CDPs develop their own source of truth? It’s easy to discard CDPs by saying they’re all-in-one solutions and not “best of breed”, but if you pull back the curtain, there’s more to the story.
Prior to founding Hightouch, I was an early engineer at Segment, the leading enterprise CDP that was acquired by Twilio for $3.2 billion. When I joined Segment in 2016, Snowflake had 100 customers and the “modern data stack” was unheard of.
While turning your data warehouse into a Customer Data Platform was a valid solution technically, it wouldn’t have made sense for most of our customers back when I was at Segment. Data warehouse adoption outside of the largest companies was extremely low, and even at the enterprise level, popular technologies were not easy to operate.
Simply put, CDPs like Segment built their own source of truth because there was no other source of truth available. CDPs did use data warehouse technologies–just “under the hood” because customers didn’t have their own warehouse ready to activate their data.
Fast forward four years to 2020, Snowflake had the largest software IPO ever. In 2022 any business not leveraging a cloud data warehouse is rapidly falling behind. Building a data analytics platform is a top priority for virtually all executives, whether that’s a CIO, CTO, or CMO.
Towards the end of my time at Segment, it became clear that the way customers viewed data warehouses and BI had totally changed. The warehouse was no longer just an advanced analytics tool you reached for when you couldn’t get an answer in Amplitude or Mixpanel–it was the source of truth across your business. Businesses were no longer just dumping data into the warehouse. With technologies like dbt and broader trends like ELT, the data warehouse became the place where definitions lived (e.g. high-value customer, LTV, churn risk, etc. ).
Data mature companies no longer need the all-in-one ingestion and unification components of a CDP. Instead, they just need tools like Hightouch to activate the data in their warehouse.

How Do I Start With a Composable CDP?
So, what does it take to implement a Composable CDP? If you can’t use an all-in-one platform, does that mean we’re back to building everything in-house? Fortunately not- the rise of cloud data warehouses has created a thriving ecosystem of tools around the data warehouse to help with every task imaginable.
-
Data Collection:
- Hightouch Events: Collect and store digital events directly from your website or mobile app into your data warehouse.
- ELT: Replicate data from your SaaS tools and databases across marketing, sales, finance/IT, product, etc. into your data warehous with tools like Fivetran:
-
Data Transformation:
- Once all your raw data has landed in your data warehouse, you can use SQL or dbt to clean up and transform the data into clean tables/views.
- Hightouch’s Identity Resolution offers a code-free visual editor that makes it easy to unify customer profiles and other entities directly in your warehouse.
-
Data Activation:
- Hightouch's Customer Studio - Build audiences, run tests, and sync data from your data warehouse into the tools that your teams are already using, e.g. Salesforce, Marketo, Facebook Ads, etc.
Realistically, most organizations already have significant portions of this architecture in place from home-built solutions or already implemented vendors. Rather than make a large upfront (and risky) commitment to an all-in-one vendor, the Composable CDP allows you to solve the most important problem in front of you, incrementally. This allows you to choose the best solution and components for your business. You’re able to educate yourself throughout the process, and also future-proof and swap out certain components down the line when your needs change, or when a specific tool just isn’t “cutting it.”
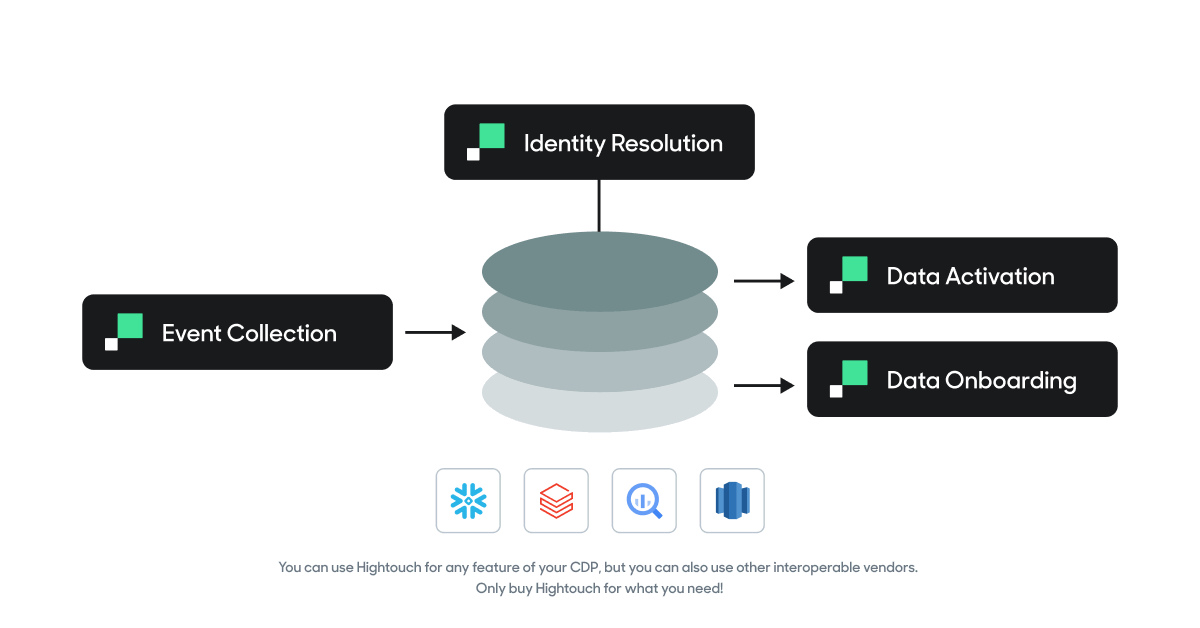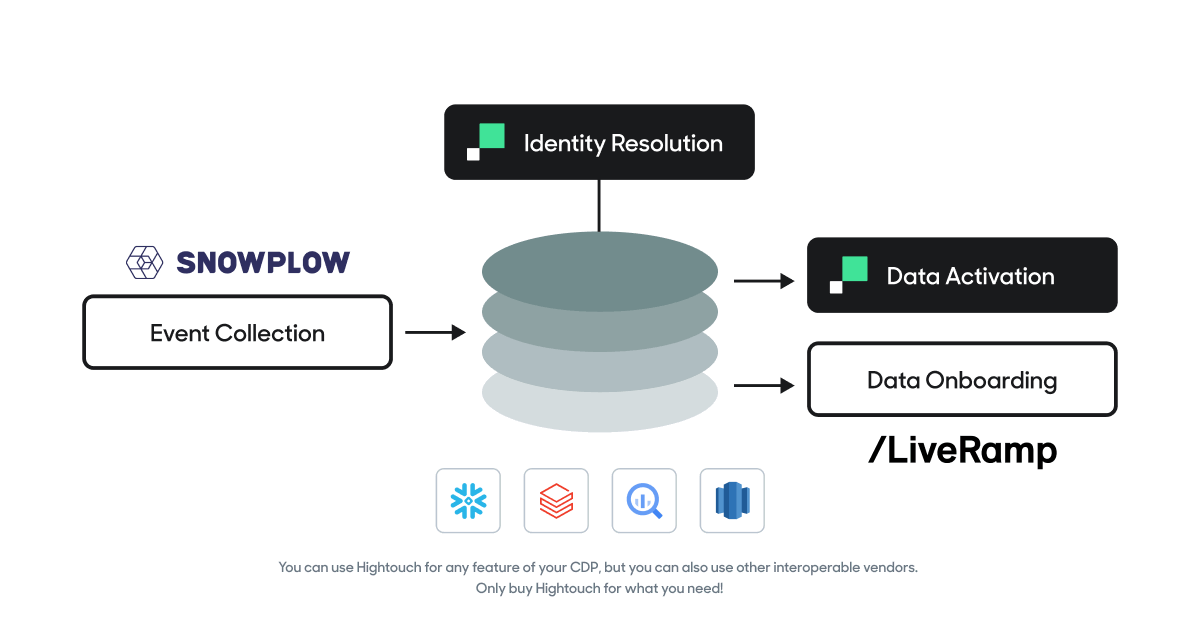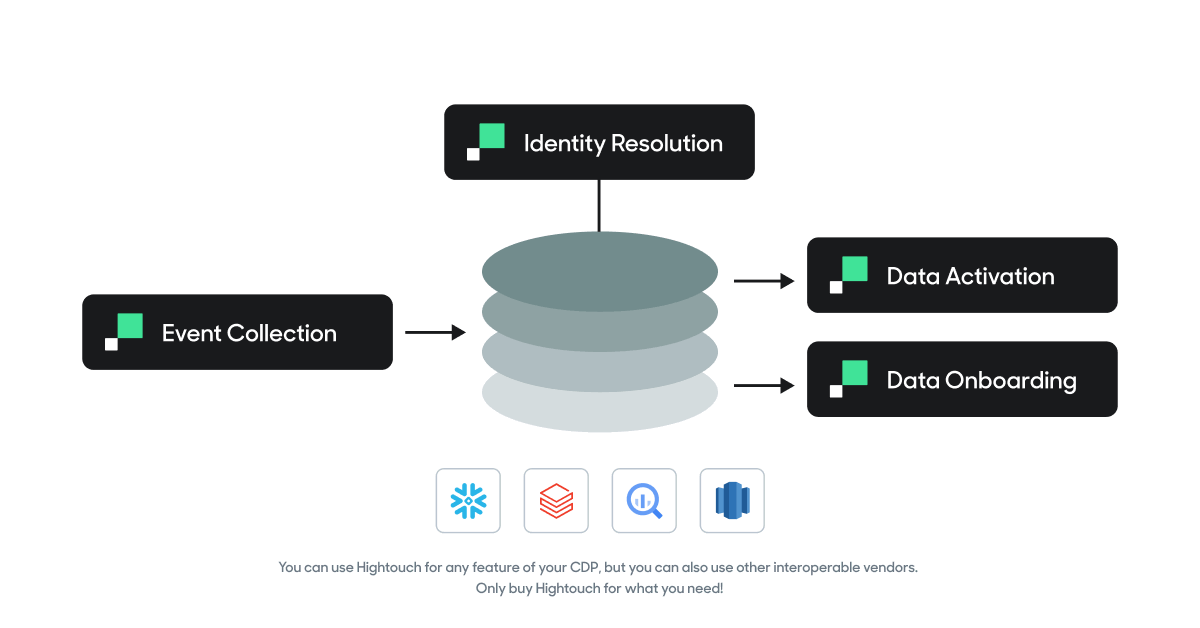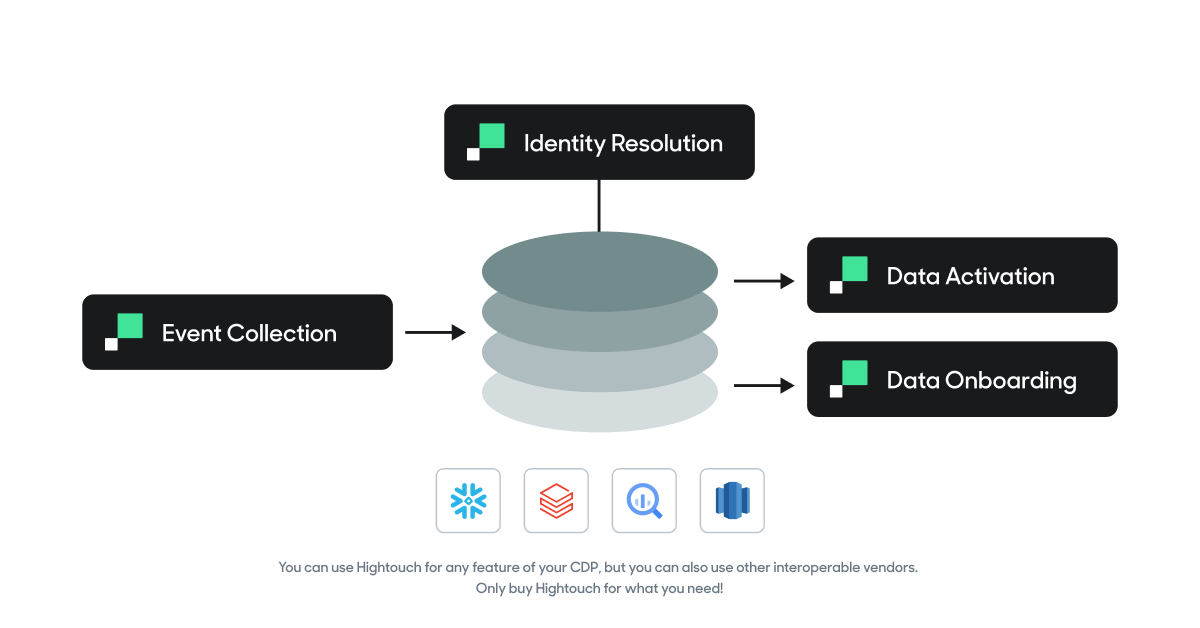
You can use Hightouch for any feature of your CDP, but you can also use other interoperable vendors. Only buy Hightouch for what you need!
Since all companies are already investing in their data warehouse for analytics, you can start activating your data in hours or days incrementally with a Composable CDP instead of months or quarters with a typical off-the-shelf CDP.
Getting Started
As the Composable CDP gains traction, we’ve seen several major CDP players develop Reverse ETL capabilities to stay relevant. We fully expect all CDPs (and even some marketing platforms, like ESPs and CRMs) to eventually embrace the data warehouse as their source of truth, further validating our approach from the beginning.
Hightouch is and always has been purpose-built for the warehouse. Modular components being tacked onto existing CDPs and other martech may sound nice, but at the end of the day will run back into the same architectural limitations– such as requiring that you still ingest data from the warehouse back into a CDP.
Ultimately, when you evaluate a CDP, take a hard look at its offerings. Regardless of marketing buzzwords, if it doesn’t run on your data infrastructure or it comes as a bundled all-in-one solution: it’s part of a legacy technology that’s been outclassed.
If you’re interested in exploring Hightouch’s products as you compose your own CDP, reach out to our solutions engineers for a demo. If you’re ever interested in nerding out about the data or marketing technology space, shoot me a note at tejas@hightouch.com.
Traditional CDP vs. Composable CDP: Which Fits Your Data Strategy?
Cut through the noise with our side-by-side guide. See exactly how traditional CDPs stack up against Composable CDPs across cost, speed, compliance, and flexibility.
- Faster time-to-value: Why Composable CDPs launch in weeks, not months
- Complete flexibility: Compare schema limits vs. support for any data model
- Better compliance: GDPR, CCPA, and HIPAA readiness at a glance
- Cost transparency: Bundled MTU pricing vs. unbundled features
- Built for scale: How Composable CDPs enable advanced personalization
Get the guide and decide if it’s time to modernize your CDP strategy.


















