
As a startup founder, I make it a point to invest my spare time listening to our sales call recordings. It's one of the best ways to continuously build customer empathy and learn about where the market stands today.
Last week, one call stuck out like a sore thumb. Mid-presentation, the customer interrupted our sales team and said…
You have to realize that not every company is running out of California, and not every company has a Modern Data Stack. The rest of us live in the real world, where people have to work in a typical warehousing environment and generate millions of revenue using Teradata.
First, I love that this person just said it like it is.
They're also not the first person to call this out. The fading hype around the "Modern Data Stack" has recently been a popular topic amongst the data community.

According to search trends, it very well may be a Bay Area + New York fad that saw hyper-growth but is starting to flatten out. The customer is always right!
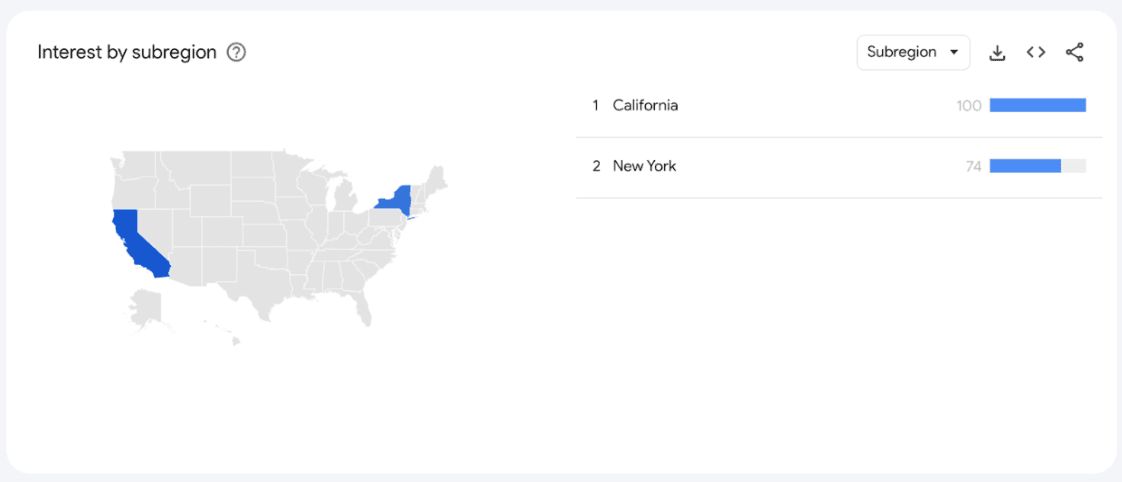
We work with many enterprises at Hightouch, including many in the Fortune 500. I know for a fact that most of them use something other than the Modern Data Stack. Statistically, less than 50% of our enterprise customers use another major solution in the MDS.
These companies use their data warehouse across the business for analytics and BI reports. They activate that data across their business systems and initiatives with Reverse ETL and a Composable CDP via Hightouch.
Is their data warehouse perfect? No, but is anyone's? In spite of that, their warehouse is still, an essential tool powering much of their business.
So, where does the Modern Data Stack fit in - if at all? Let's dig in, starting with a bit of history on what got us here in the first place.
Driving Personalization at Scale
Read our whitepaper to learn how you can hyper-personalize your customer experiences on top of your data warehouse.

The perils of marketing your data startup in 2021
In 2021, Snowflake had the largest software IPO ever. This set things off. Since then, hundreds of VC-backed startups have been founded in the data space. This was around when we started getting traction at Hightouch with our customer data platform, helping marketing teams activate their warehouse data without engineering dependency, so I vividly remember these days.
Soon enough, the concept of a "Modern Data Stack" emerged. I don't know who coined it, but MDS quickly became all the buzz. Every week, I'd see a new post from vendors, VCs, and data thought leaders on the Modern Data Stack. They'd each have their own diagram similar to the one below.
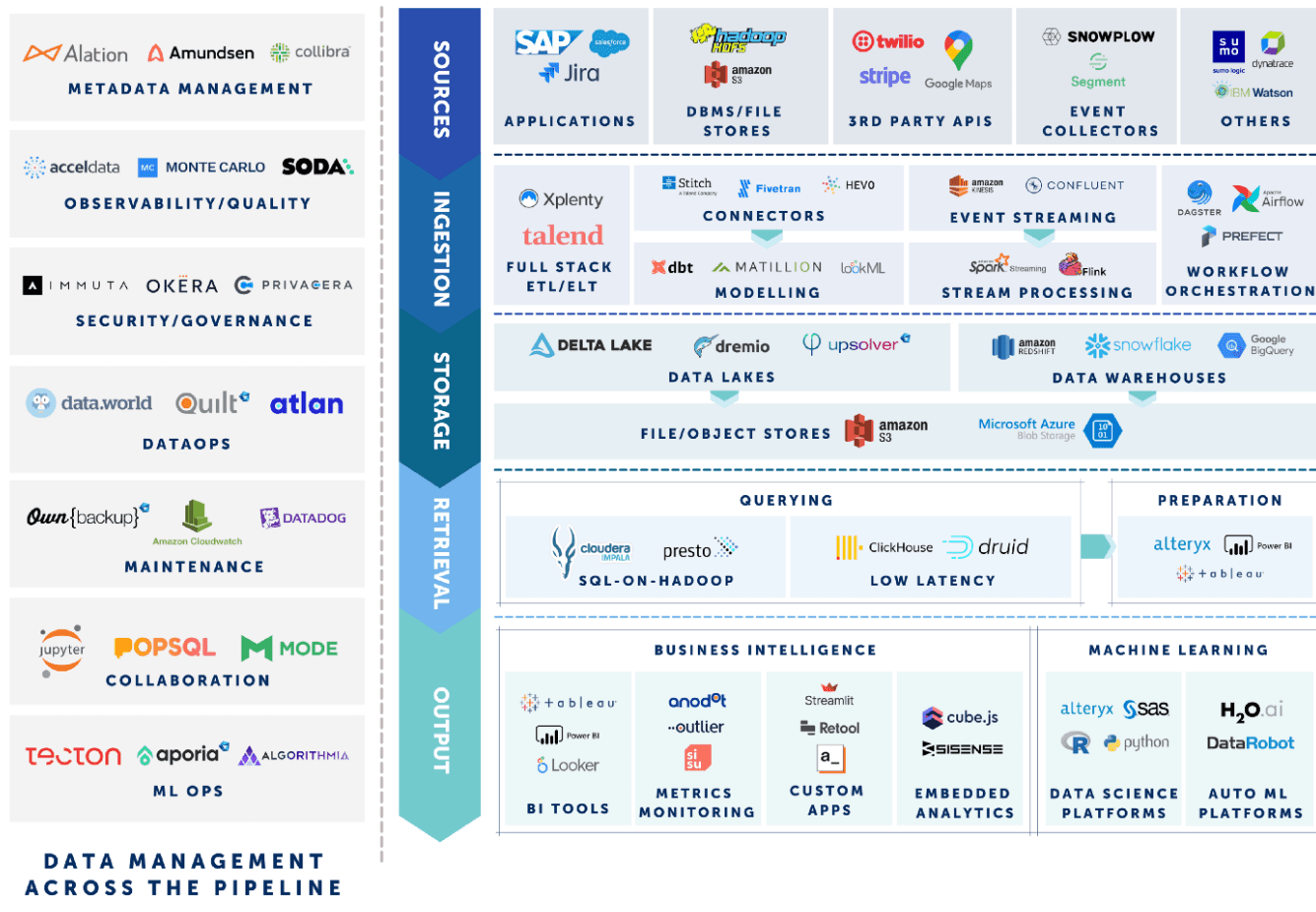
The "Modern Data Stack" became a target for technology buyers everywhere. Startups would book sales calls with vendors saying they're implementing a Modern Data Stack and XYZ tool is next. Consultants started branding themselves as experts in MDS.
The problem was that people were often collecting tools to complete or 'future-proof' their stack rather than assembling tools to solve their most pressing business problems. It was a classic boom market buying frenzy - similar to what was happening in real estate and the broader stock market at the time.

Candidly, Hightouch benefited from it. We were considered by many organizations that might not otherwise have prioritized activating their warehouse data because the concept of a Modern Data Stack was so omnipresent and exciting.
In 2023, however, budgets were slashed, and the frenzy started to dissipate. Companies could not go around buying all the tools in the world as an end in and of itself. Buyers began to question if they were heading down the right path.
Is the Modern Data Stack valuable?
As much as I like making fun of it, the Modern Data Stack conversation was disruptive to the way data teams operate and did unlock value. Like any boom frenzy, there is waste, but there is also often genuine innovation and value creation. I'll give you a few examples.
- Fivetran empowers anyone to load fresh, high-quality data into their data warehouse from 200+ data sources, including SaaS apps, ad networks, and databases. Simply put, Fivetran made the data warehouse accessible to startups (and easier to manage for the enterprise!). A 100-person startup can now operate a full-fledged data warehouse without hiring a team of 5 engineers to build and maintain ETL pipelines continuously.
- dbt empowers analysts to contribute to the core data models across their business with just SQL. It created a whole new discipline of "analytics engineering." Without dbt, analysts often copy around 1000+ line SQL queries or wait months for BI or data engineering teams to deploy changes to their core data models.
- Hightouch empowers anyone who knows SQL or, heck, is data literate (with our audience builder) to activate their data and power automated workflows across your company, whether that's pointing sales reps to the best accounts in Salesforce to delivering targeted ads in Facebook to personalizing your checkout flow.
For anyone tasked with this kind of work, the before/after of using these tools was night & day. They continue to disrupt the industry by presenting dramatically simpler solutions to everyday data problems while democratizing the ability to solve them across the organization.
So that raises the question…
Do I need the Modern Data Stack?
My #1 advice to folks architecting systems—whether data, MarTech, or software— is to stop thinking in "stacks." You have problems. There are solutions. You need to figure out what solution is right for your organization.
The Modern Data Stack is a helpful point of reference for understanding the landscape of tools available, but it shouldn't be the North Star for your architecture. The reality is that most businesses, especially in the enterprise, aren't starting with a clean sheet of paper. They have existing data pipelines, data catalogs built-in Notion or Google Sheets, BI reports in Tableau, and non-MDS tooling delivering value.
Start there. You do not need to buy the Modern Data Stack to get stuff done or before starting a new initiative. Narrow down your problem and figure out how to solve the gap.
Here's a great example. A couple of years ago, I spoke with the Chief Data Officer of a Fortune 500 company that had recently purchased Hightouch to help his marketing team deliver personalized campaigns. They were huge advocates and users of Snowflake, so I asked them if they'd considered taking the next step in the MDS and implementing an ETL tool like Fivetran. They had a large team of engineers on staff building ETL pipelines, so it made sense to me. The CDO asked me why they'd do that when their team of engineers had mastered ETL connectors over the last decade.
While I may not fully agree with the reasoning, the CDO of a Fortune 500 company has a lot more to worry about than doubling back on already solved problems. They had to prioritize the solutions that delivered value for their stakeholders and move the needle for their business… not just buy a paint-by-numbers stack.
In retrospect, they were spot on. In due time, they will adopt Fivetran or a similar solution for at least a subset of their pipelines. But, at the time, offloading ETL wasn't their biggest problem, and having an older data stack (including Informatica and Mulesoft!) wouldn't prevent them from supporting their marketing team with personalization.
There’s only one answer, and that’s pragmatism
It's not Modern Data Stack or legacy. The trend I see among the most successful data teams in 2023 is that they hone in on the most valuable, urgent business problem that their businesses face. Then they solve that problem with in-house processes or traditional enterprise technologies or yes, MDS tools if it’s warranted. For example,"We need Zendesk data in the warehouse for headcount planning and we don't have an ETL for that so let's try Fivetran… leave everything else as is!". Companies are seeking a pragmatic data stack rather than assembling the Modern Data Stack.
I continuously remind folks that our job as technologists is not to find the most sophisticated solution to a problem but instead the simplest functional one. This applies whether you're a data practitioner, product engineer, technical business person, or even a leader figuring out how to scale organizational processes. It's everywhere.
Marketing technology might be the worst offender here. I've seen some of the largest enterprises in the world convinced that they need to replace their decade-old email platform and go through a 12+ month migration process when they could have just worked with their data team to stand up a Reverse ETL platform or audience builder in front of it and suddenly be able to achieve "best-in-class personalization at scale" (whatever that means).
While your pragmatic architecture may not get a keynote at Snowflake Summit or rank #1 on Hacker News, you will deliver incredible outcomes, make your executives damn happy, and justify your next raise. That's the power of pragmatism.
What should I prioritize? How can I be pragmatic?
If the top priority isn't to build the best data stack possible, what is?The key to leading a pragmatic data team is aligning with your stakeholders. You must work with them to determine what will move the business forward.
I was catching up with Abhi Sivasailam last week about this topic; he had some great thoughts. Abhi previously led Growth & Analytics for Flexport and now runs a data consultancy called Lever Labs and is building out a project called SOMA (Standard Operating Metrics & Analytics). I'll paraphrase Abhi's advice that he recently gave another client.
First, it comes down to understanding the key metrics in your business and what it takes to influence them. Abhi likes working with your business stakeholders to build a metric tree for your business.
The example metric tree below is generic for B2B SaaS businesses. You can build your own, but the general idea is to align on key metrics and their drivers (aka, what influences them).
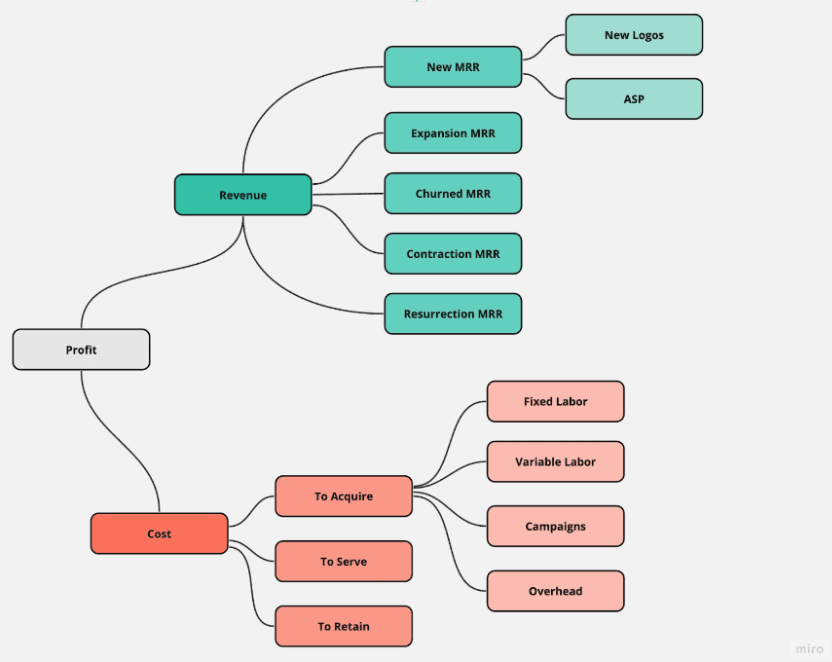
For anyone interested in learning more about Metric Trees, check out Abhi’s talk from Data Council a few months ago.
Once you have the lay of the land, start talking to your business counterpart about how you can help. Abhi drafted a series of questions recently.
Which drivers…
- Are the biggest priorities for the company?
- Are most expensive/intensive/difficult to influence?
- Do we have the most/least uncertainty around our ability to influence?
- Do we think we have the most "slack" to influence?
And:
- Where has data produced the most substantial value in the past two quarters?
- Where do we think we can deliver value?
Now that you're aligned on the business potential, it's time to start thinking about your data maturity, what assets you have to work with today, and where it may make sense to prioritize new technologies.
There's a lot here. I'll have to do another post with Abhi sometime.
Closing the loop
Ultimately, the Modern Data Stack concept is a useful reference point. Still, the idea of needing a 'modern' stack to keep up with the times is unnecessary.
The practice of buying all the tools in a "stack" and implementing unnecessary reference architectures as part of a trend is over, and we're all going to be better for it.
The path forward is simple - work closely with your stakeholders to understand how data can help drive the business forward. There is an answer. That answer may lie in a fancy systems diagram, but to be honest - it probably doesn't.
Thanks to Abhi Sivasailam, Taylor Murphy, Pedram Navid, and Lee Hammond for reading drafts of this post.
Driving Personalization at Scale
Read our whitepaper to learn:
- How PetSmart delivers personalized messages
- How IntelyCare increased controlled experiments by 700%
- How Warner Music Group manages fans, artists, and labels

















