
The Last Mile of the Modern Data Stack
Reverse ETL is one of the emerging trends in data engineering, and while it is gaining in popularity many are still wondering what is Reverse ETL and where is it going? We already have a great in-depth guide to Reverse ETL but to quickly summarize, Reverse ETL is the last-mile of the modern data stack pipeline, concerned with taking data out of the warehouse and into various tools and services that benefit from data that has been cleaned, aggregated, and converted from a source-centric view to one that is rich in semantic meaning.
In this post, we're going to give an overview of the different types of data integrations we see being used in Reverse ETL pipelines, explore the current trends in Reverse ETL, and look at the future of data integrations.
Types of Data Sources for Data Integrations
Looking at the overall Reverse ETL landscape, we see a few broad ways of looking at data integrations. In general, our data integrations take data from a source and send it to a destination, and so it one easy way of looking at the different types of Reverse ETL workflows customers have is by looking at data across two axes: types of sources, and types of destinations.
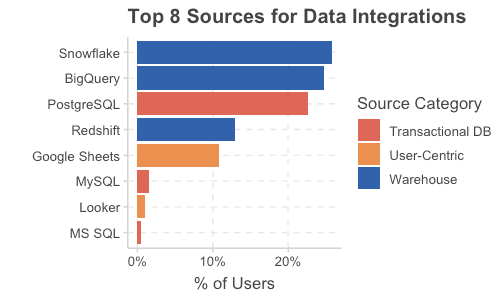
With sources, we see three main types: warehouses, transactional/real-time driven, and user-centric sources.
Warehouses
Warehouses, like Snowflake, BigQuery, and Redshift, drive the majority of use-cases. With excellent analytic performance, plus a great tooling ecosystem when it comes to modeling and visualization, they remain the standard choice for data integration pipelines.
Databases
Transactional databases, like PostgreSQL and MySQL, help support more real-time access patterns. While they're not as performant as data warehouses for very large analytic patterns, they are the standard for high-performance systems that need lower latencies than what has traditionally been possible with warehouses. The downside with transactional systems is that they are often constrained in the breadth of data available. While you might have application-level transactions available, you likely won't have data from various other systems like billing, invoices, CRMs, emails, customer service tools alongside.
User-Centric
The final source is what we term user-centric sources. These are not traditional data systems, but they are systems of record for many users. Spreadsheets are the obvious one here, but other systems such as Looker and AirTable can also be classified under this use case. While some might sneer at the idea of using Google Sheets as a data source, the truth is spreadsheets are not going away because they provide something the other systems lack: a simple, intuitive interface for recording data. I challenge anyone who disagrees to write the exact query for inserting a row of data into a table in SQL, without looking up the documentation.
Types of Destinations for Data Integrations
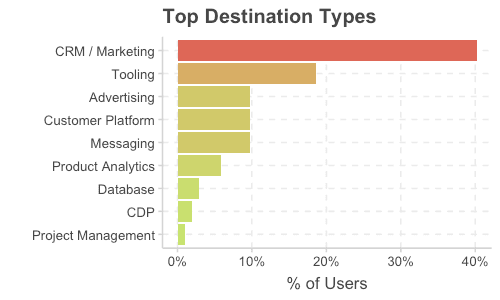
As for data integrations, the ecosystem is by its very nature much larger.
CRM / Marketing
If we look at broad categories, CRMs and Marketing platforms like Salesforce and HubSpot dominate. For many, getting data into these systems involves a lot of complexity. Questions around how to handle conflicts, missing data, eventual consistency, handling errors, and converting types all make integrations into these systems difficult.
Being able to out-source the difficult parts of an integration into a CRM to a third-party vendor like Hightouch, while being able to describe the data models through SQL powered by a data warehouse has become the standard for solving these issues. Use cases are broad: adding product analytics, updating compliance information, adding leads and renewals, linking accounts to objects, syncing confirmation information. There's really no limit to what can be done, and getting accurate, timely data in front of your sales and marketing team is a no-brainer. The results speak for themselves, with customers seeing double-digit increases in reply rates when outreach is personalized.
Custom Tooling
Tooling, a broad category that covers everything from direct webhooks to spreadsheets are another popular destination for data integrations. Webhooks are particularly powerful because they can help cover any use case that can be handled through custom code. Whether it's a custom transformation that needs to happen or hitting an internal API, Webhooks provide a level of customizability that cannot be beaten.
Spreadsheets are powerful for a different reason, they provide users with a simple interface for looking at tabular data and for building simple charts and summaries. We've seen use cases as varied as capturing attribution information, to demand planning, to sales opportunities exported to spreadsheets for internal use.
Advertising
Another powerful use case is advertising workflows. With changes coming to how online advertisers can track users across sites, being able to send conversion information back to your advertising platforms can help increase the accuracy of your conversion tracking. Building audiences powered from data off your warehouse in an automated way helps free up your marketing team to focus on what they do best, and not on downloading spreadsheets and manually uploading them.
Customer Platform
Customer platform is a generic term that refers to destinations that have some direct relationship with supporting your customers. Tools like Intercom, Zendesk, Totango, ChurnZero, and MoEngage all aim to help make the custom success experience better. With this in mind, we're seeing more and more companies sync product data into these platforms to help drive automation and personalization. Whether it's updating customer's name and payment information in Zendesk, or sending product metrics to Totango and ChurnZero to help prevent churn, being able to sync insights from your warehouse to your customer platforms is a major driver of improved customer retention and experience.
Messaging/Notification
One of the most used destinations and in some ways an unsung hero of data integrations is messaging, using tools like Slack and Mattermost. There are times where you need to get relevant information quickly in a place where people are most likely to see it. The possibilities are really endless here. Everything from power a live users feed, to bringing high-intent leads in front of your sales team, to notifying a customer success team when an account has gone dormant, messaging and notification systems are seen throughout.
Some great use cases to call out are getting useful links in front of your internal users. Whether it's a direct link to Hubspot when a sales opportunity arises, or a shipment tracking link when there's a delay, having a user-minded approach here can really pay dividends and help bring a little bit of joy to routine tasks.
Product Analytics
Product Analytics platforms like Amplitude and Mixpanel help companies develop better insights into how their customers use their product. Syncing data back into these tools can help augment the quality of those analytics. One of the most common use cases we've seen is getting something as simple as a user id, service area, or product usage information in these product analytic tools to help drive greater insight. This enables more complex analysis, either on a more granular level, or by building out particular user cohorts.
Databases
It may seem counterintuitive at first to take data from a data warehouse and put it back in a database but it's a pattern we are seeing more and more. As the data warehouse has become the central library of information about a company's systems, other internal applications soon require access to that information, but with lower latencies. One option has been to query that data directly from the warehouse, but this can lead to tight coupling to data models. A preferred approach being used by companies is syncing modeled data from the warehouse to a database which can then be used by the application to serve users with low-latency results.
Great examples of this are performing complex calculations and modeling on user data to generate features which are then used by user-facing applications to serve personalized experiences. The features do not change frequently, but having access to them quickly is important. Syncing data a few times a data from the warehouse into a PostgreSQL database provides exactly this capability.
Customer Data Platforms
While traditionally seen as a data source rather than a destination, we are also seeing an increase in data integrations going from the warehouse back into CDPs. This Reverse ETL process is driving a variety of use-cases, whether it's powering customer journeys or user segments enabling better marketing campaigns and analytics.
Project Management
One of the newest use cases we're seeing which has a ton of potential are workflows centered around project management. Perhaps nothing better demonstrates how operationalizing your data in the warehouse can put your data into action that creating reminders and tasks and even categorizing and assigning them directly off data in the warehouse. There are many possibilities here as well, such as helping reduce customer churn by creating tasks to follow up with customers who meet certain criteria or creating an onboarding flow for users who have just signed up. This is an exciting space to watch as operational analytics becomes more than just data syncing but about enabling entire end-to-end workflows.
Future Trends in Reverse ETL
We hope this has been a helpful exploration of some of the trends we are seeing in the data integration space, but we've only scratched the surface. Reverse ETL is a fairly new concept, and we're really excited about what the future has in store. While it's always hard to predict where we will be in a few years, there are a couple of places we've got our eye on.
From Batch to Streaming in the Warehouse
Warehouses have traditionally been batch-focused, but more and more customers are moving toward streaming and event-based architectures. Snowflake is already working on streaming solutions and we certainly expect this space to continue to evolve. Being able to combine data from various sources, while streaming reads and writes is extremely promising and a complex engineering problem. While solutions like Kafka are highly performant and redundant streaming solutions, other vendors such as Materialize have take this a step further and created materialized views on top of streams to power real-time applications. Bridging the integration divide between streaming solutions and batch-based integrations still is an open question, but one we're excited to see develop.
Integrations as Infrastructure
The data world has, to some extent, been given a pass when it comes to some of the better practices we've come to expect from software engineering principles. You might hear that it's not possible to test data the same way we test applications. Concepts like unit-testing, staging environments, and continuous deployments have different characters when it comes to working with data rather than with code. Data is messy, ugly, and refuses any attempt to keep it from diverging from expectations.
Perhaps this is why most data integrations tend to not have the same set of standards we'd expect. Most applications that sync into CRMs don't offer a compelling way to test the integration before hoping that everything works well. One of the biggest barriers to treating integrations with the level of respect they deserve is that it has traditionally been a black box that is UI driven. We see a shift occurring though, where companies become more comfortable with the idea of declarative programming that describes the intended state, rather than a specific set of instructions.
Declaring the state of an integration via code opens a lot of doors. It makes it easy to swap out testing environments with production ones. It allows static analysis of decisions, and makes version controlling changes to that state easy to reason about. Being able to deploy data integrations via a CI/CD process that is peer-reviewed, tested, and documented will help give data teams more comfort in their data pipelines. We think it's only a matter of time that integrations into third-party tools like CRMs, which have become more and more critical, start to follow the same patterns of software development elsewhere within companies.
Conclusion
We hope this has been an informative exploration of the current state of Reverse ETL and data integrations. This space is rapidly evolving and our customers are one of the biggest drivers of what's possible. At Hightouch, we love customer feedback, it informs everything from our product design, to our engineering philosophies, to the integrations we queue up. If you're interested in trying out Reverse ETL for yourself, sign up today and get started. No credit card required, and you'll be up and running in minutes.

















