
Getting your head around cloud data warehouse pricing can cause you a headache. Different providers offer various pricing models; pay-as-you-go, on-demand, and reserved instances–all of which make comparing costs hard.
Costs vary depending on storage, compute resources, data transfers, and other underlying services. This comprehensive guide will help you understand how Redshift pricing works. In this article, you’ll learn:
- The different architectural components that impact price
- How computing and storage costs are calculated
- The additional services you can have with Amazon Redshift
What is Amazon Redshift?
Amazon Redshift is a cloud data warehouse provided by Amazon Web Services (AWS). It offers scalable and secure analytics over multiple databases and supports structured and semi-structured data, so you can easily query your data to unlock new insights.
Redshift is a centralized repository that stores and manages large volumes for analysis, activation, and reporting. It offers the capability to store, organize, and analyze data from various sources, such as internal databases, server events, and SaaS tools.
The platform has a column-oriented architecture, deep integration with AWS services like Amazon S3, and compatibility with SQL-based clients and business intelligence tools, enabling real-time data analysis with exceptional performance for data teams.
Architecture
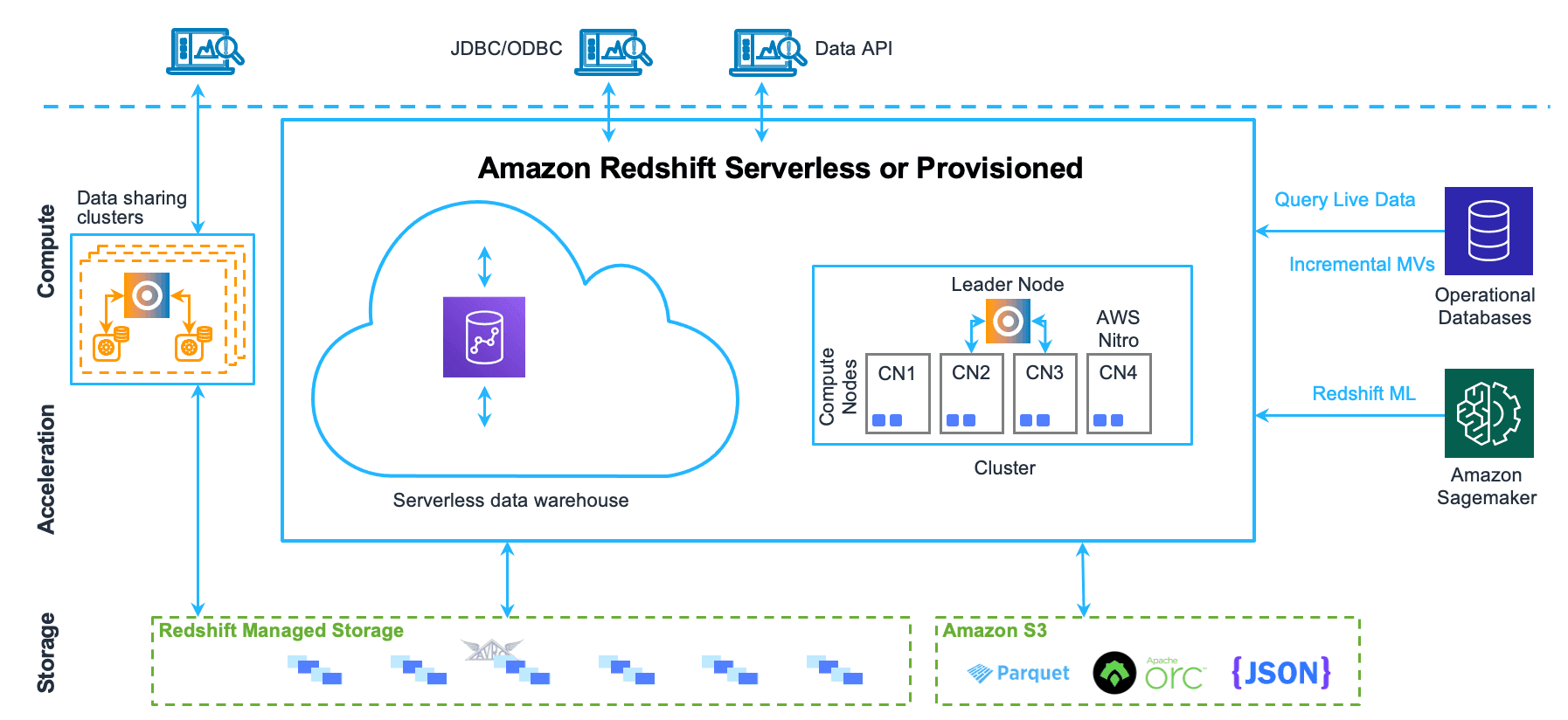
Data warehouse system architecture - Source
While the value Redshift provides is relatively straightforward, the underlying architecture which powers the platform is more complex. There are eight main components that make up Amazon Redshift architecture.
- Leader Nodes: Manage communication with client programs and compute nodes. It distributes compiled code and assigns portions of the data to each compute node.
- Compute Nodes: Leader nodes assigns code to compute nodes which run the code and send results back to the leader node.
- Node Slices: A partitioned compute node that processes a portion of the compute node’s workload. The leader node distributes the workload of queries or database operations so the slices can work in parallel to complete the operation.
- Massively Parallel Processing: Enables fast execution of complex queries by distributing data across multiple compute nodes, optimizing workload balance, and minimizing data movement.
- Columnar Data Storage: Reduces disk processing and improves query performance. Appropriately sorted columns enhance data filtering capabilities.
- Data Compression: Reduces storage requirements, improves query performance by minimizing disk processing, and allows for efficient memory allocation by compressing data during query execution.
- Query Optimizer: Leverages columnar data storage to enhance the processing of complex analytic queries, including multi-table joins, subqueries, and aggregation.
- Cluster Internal Network: Ensures secure and efficient communication between leader and compute nodes through private, high-speed network connections, utilizing custom protocols, and isolating compute nodes from direct access by client applications.
Computing Costs
There are some major contributing factors that make up the computing costs of Amazon Redshift. These are the chosen node type to build the cluster, where you deploy it, and the billing strategy. There are three options for billing; a free trial, on-demand pricing, and serverless pricing.
Free Trial
Amazon offers a free trial if you haven’t used Redshift Serverless. If Redshift Serverless is unavailable in your country, they offer a two-month free trial of DC2 large node in provisioned clusters.
The free trial gives you a $300 credit for computing and a 90-day usage timeframe. The free trial of a DC2 large node gives you 750 hours per month.
The free trial is perfect for experimenting to see if Redshift meets your company's needs. However, you may need more than $300 credit to try everything, and there may be restrictions on certain features.
On-Demand Pricing
On-Demand pricing has an hourly rate for the specific node type you want to run your warehouse on. Each region and node type will change the price.
On-Demand pricing is great, as you only pay for the resources you use. You can use Redshift without commitments or upfront costs and easily scale your cluster based on your needs. however, the On-Demand price can be higher compared to a long-term contract and can make budgeting costs difficult as the pricing fluctuates based on usage patterns.
Pricing for on-demand in US Ohio ranges from $0.25 to $13.04 per hour.
Serverless Pricing
Amazon Redshift Serverless is a fully managed warehousing solution offered by AWS. It can automatically scale resources based on your workload requirements, eliminating the need to manage infrastructure.
Redshift Serverless eliminates the task of manually provisioning and managing compute resources and lets you pay only for the computing you use during query execution.
Pricing for Redshift Serverless in US Ohio is $0.36 per hour, and you only pay for the compute capacity your data warehouse service consumes when it’s active. Amazon Redshift measures data warehouse capacity using Redshift Processing Units (RPUs) and charges you based on the workloads you run in RPU-hours, billed on a per-second basis with a 60-second minimum charge.
Storage Costs
Amazon Redshift provides two types of storage, and each serves a distinct function with separate pricing structures.
Traditional CDP vs. Composable CDP
See how the two approaches compare across speed, compliance, cost, and scale—all in one chart.

Managed Storage
Redshift Managed storage is the primary storage capacity of Redshift Serverless, which you pay at a fixed monthly rate per GB of storage, depending on your region. Managed storage uses RA3 nodes exclusively. RA3 nodes are compute nodes for high-performance data processing, and they combine compute power with storage capacity, allowing for efficient data analysis. Pricing for managed storage is calculated per hour based on the total data in the managed storage and pricing in US Ohio is $0.024 per GB.
S3 Storage
S3 storage refers to Amazon Simple Storage Service, a highly scalable and durable cloud-based object storage service that Amazon Web Services (AWS) provides. It offers a simple and secure way to store and retrieve data anywhere on the web. S3 provides unlimited storage capacity and stores and retrieves data objects, such as files, images, videos, documents, and backups.
There are multiple tiers of S3 Storage depending on your needs. The options available include:
- S3 Standard: Ideal for general storage that is frequently used.
- S3 Intelligent: Ideal for data with unknown or changing access patterns.
- S3 Standard - Infrequent Access: Ideal for infrequently used data that need fast access.
- S3 One Zone - Infrequent Access: Ideal for re-creatable infrequently accessed data that needs fast access.
- S3 Glacier Instant Retrieval: Ideal for archive data accessed once a quarter and needs fast retrieval.
- S3 Glacier Flexible Retrieval: Ideal for long-term backup storage and archives that need retrieval from 1 minute to 12 hours.
- S3 Glacier Deep Archive: Ideal for long-term data archiving that are accessed once or twice a year and can be restored within 12 hours.
Pricing for S3 Storage in US Ohio ranges from $0.00099 to $0.023 per GB. S3 storage is ideal for building data lakes where large volumes of structured and unstructured data is needed for advanced analytics and machine learning. S3 also makes for a cheaper storage solution, as you can select a tier depending on how frequently you want to access your data.
Additional Costs
Computing and storage are the main drivers of costs for Redshift, but there are other services you can pay for that add additional benefits.
Redshift Spectrum
Redshift Spectrum enables you to run queries directly on data stored in Amazon S3 without loading the data into tables. It extends the querying capabilities of AWS Redshift to include data in S3, allowing you to analyze vast amounts of data stored in different file formats, such as CSV, JSON, Parquet, and more.
Amazon Redshift Spectrum bases its billing on the amount of data scanned, rounded to the nearest megabyte, with a 10 MB minimum per query. So if you scanned one terabyte of data, you would be charged $5.
Concurrency Scaling
Amazon Redshift's Concurrency Scaling is a feature that automatically adds temporary capacity to ensure consistently fast performance, even during peak usage with numerous concurrent queries and users. This scalable capability eliminates manual resource management, has no upfront costs, and does not charge for transient clusters' startup or shutdown time.
You can accumulate one hour of Concurrency Scaling cluster credits every 24 hours while your main cluster runs. If your usage exceeds the free credits, you are billed the per-second on-demand rate for the Concurrency Scaling cluster, with a minimum charge per activation.
The number and type of nodes in your Amazon Redshift cluster determine this rate. However, with Amazon Redshift Serverless, resources automatically scale up and down based on workload needs, and there are no separate charges for concurrency scaling. The pricing for concurrency scaling in US East per second ranges from $0.00024 to $0.00362.
Redshift Backups
Amazon Redshift provides automatic backups for your data warehouse at no additional cost. While these backups are sufficient for most scenarios, taking manual snapshots at specific points in time can be beneficial. The storage pricing bases these additional backups on standard Amazon S3 prices for clusters using RA3 node types. For clusters using DC nodes, manual backup storage exceeding the specified rates are charged at standard S3 rates.
Amazon does offer other backup alternatives, such as Amazon S3 Backup and Amazon Redshift Cluster Snapshot.
Each backup option gives you the choice of warm and cold storage. Warm storage lets you access your data fast, which is ideal for data you want to access daily. Cold storage gives you slower access to your data and is more used for archived data that isn’t often needed. Pricing for Amazon backup storage in US Ohio ranges from $0.01 to $0.10 per GB per month.
Reserved Instance
Reserved Instances offer significant cost savings for steady-state production workloads compared to on-demand pricing. Customers typically purchase Reserved Instances after validating their production configurations through experiments and proof-of-concepts.
By committing to a one- or three-year term, you can benefit from substantial discounts over on-demand rates, with pricing specific to the purchased node type. Reserved Instances include additional data copies, backup, durability, availability, security, monitoring, and maintenance services.
There are three pricing options available: No Upfront, Partial Upfront, and All Upfront. While Reserved Instances are not used to create data warehouse clusters, the associated upfront and monthly fees apply regardless of cluster status.
Redshift ML
Redshift ML helps data analysts and database developers to create, train, and apply machine learning models using SQL commands familiar to Redshift data warehouses. You get access to Amazon SageMaker, a fully managed machine learning service where you can use SQL statements to create and train Amazon SageMaker machine learning models from your AWS Redshift data to make predictions.
Redshift ML provides two free CREATE MODEL requests per month for two months, with up to 100,000 cells per request. Beyond that, you get charged for the number of cells, starting from $20 per million cells.
Final Thoughts
Understanding the pricing of Amazon Redshift is crucial for optimizing costs and maximizing the benefits of its features. Redshift offers different pricing models, and comprehending each aspect will enable you to make informed decisions regarding workloads, compute resources, storage, and overall spend.
Traditional CDP vs. Composable CDP: Which Fits Your Data Strategy?
Cut through the noise with our side-by-side guide. See exactly how traditional CDPs stack up against Composable CDPs across cost, speed, compliance, and flexibility.
- Faster time-to-value: Why Composable CDPs launch in weeks, not months
- Complete flexibility: Compare schema limits vs. support for any data model
- Better compliance: GDPR, CCPA, and HIPAA readiness at a glance
- Cost transparency: Bundled MTU pricing vs. unbundled features
- Built for scale: How Composable CDPs enable advanced personalization
Get the guide and decide if it’s time to modernize your CDP strategy.

















