
Customer Relationship Management (CRM) software has become a centrepiece amongst sales teams of all sizes. And today, Salesforce is the undisputed king among CRM software vendors. By acquiring a wide range of companies and solutions, Salesforce has embedded its CRM solution in an ecosystem that has managed to spread its tentacles far and wide. However, for those pursuing a best-of-breed architecture, integrating data from third-party sources into Salesforce is key.
This article will walk you through your options for pushing data to Salesforce from your data warehouse.
Organizations today rely on a patchwork of software solutions to engage with their customers across every possible touchpoint. In order to produce insights from those interactions, companies centralize all the data from various first-party and third-party systems into an enterprise data warehouse (EDW). However, it makes perfect sense to sync that data in the opposite direction too.
Since the EDW is the single source of truth (SSOT) for your data, there are many use cases for pushing data from your EDW into Salesforce. There’s a ton of valuable information that your sales teams can use to detect opportunities and facilitate conversations with leads. It would be a pity if your analysts spent so much time building meaningful segments in the data warehouse by combining data from various sources only for it to fuel analysis and not action.
In other words, acting upon the data by syncing it from your EDW to your sales and marketing tools is the next logical step.
It takes two to integrate — a source system and a destination system — so I’ve structured this article into two parts:
- Serving untapped data potential to sales teams: three ways that Salesforce CRM expects to receive data from external systems.
- Separating the valuable from the valueless in your EDW: a brief overview of how modern data teams extract what’s necessary from their data warehouse
Serving Untapped Data Potential to Sales Teams
In the following sections, I list several options for syncing data to Salesforce CRM. The three proposed paradigms are not exclusively tailored to enterprise data warehouses:
- Data virtualization
- Event-driven architecture
- An API-driven approach
However, within this scope, there are use cases for each paradigm that would satisfy various organizational and technical needs.
Data Virtualization with Salesforce Connect
Data virtualization is one of many ways to make data from external sources available in Salesforce CRM. Instead of copying the data from one system to the other, data virtualization focuses on mapping objects across multiple systems.
Salesforce Connect is Salesforce’s go-to-solution for data virtualization. It maps external objects—a Salesforce object entity— to tables in external systems. The data remains in the external system. It does not get copied.
Salesforce Connect supports data virtualization via three connectors:
- The cross-org adapter is designed to connect to external Salesforce organizations.
- The OData connector connects to any system that supports the OData 2.0 or 4.0 protocol.
- The Apex custom adapter leverages the Apex Connector Framework.
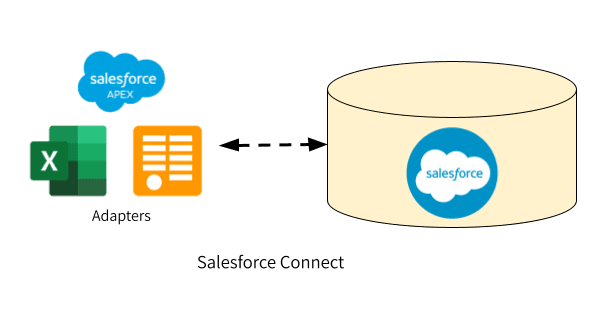
Whatever piece of information is requested is made available in real-time and reflects its current state. These external tables can be incorporated into your Salesforce data model, just like any other object.
Finally, by enabling writable external objects, Salesforce Connect goes beyond read-only operations.
Let’s wrap data virtualization up with an example.
Let’s assume that you store transaction information in an enterprise resource planning (ERP) system. You want to make those transactions available as a related list for each customer record in your Salesforce CRM. Salesforce Connect can create a lookup relationship between the customer object (in Salesforce) and the transaction object in the ERP. The page layout of the customer object can be set up to include a related list that displays the child records.
Salesforce Connect is a brilliant tool for connecting to legacy systems without needing any middleware. The data can be made available at the click of a button. From an operational perspective, Salesforce Connect is the go-to-solution for exposing external sources to your sales teams.
Because the data is not duplicated and not transformed in the linking process, all insights, segments, and opportunities should be specified in the source system. This reduces your data team’s flexibility to tailor their findings for each particular sales and marketing channel. You should also be aware that Salesforce Connect’s transformation capabilities are somewhat limited and costs scale with your plan and the number of licenses you have.
An Event-Driven Architecture with Salesforce Platform Events
A second way to sync data between multiple systems follows an entirely different architectural paradigm. Because of the growing popularity of microservices, event-driven systems have gained ground over the past couple of years.
Instead of giving a particular system mastership over a table or object, systems can subscribe to certain events that have been published on an event-processing platform. These events are changes of a state, such as a lead becoming a customer.
In an event-driven architecture, all services are decoupled; broadcasted events by one system can be consumed by multiple systems.
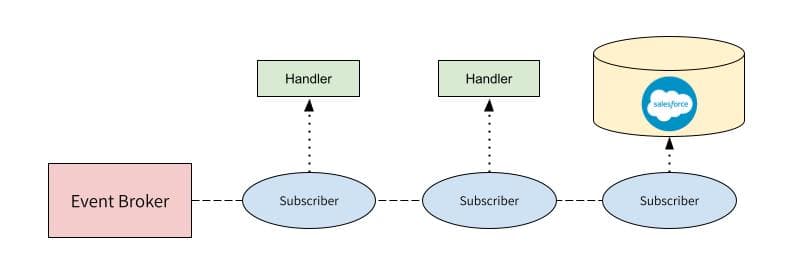
One can quickly see how this paradigm supports syncing data across systems that can scale independently according to its individual users’ needs. However, with real-time data comes a real-time data transformation solution.
In an architecture where every transaction, user action, and data change is published as an event, this would be the preferred solution. However, if your data-wrangling operations are focused on data that is at rest, publishing each transformation as an event is suboptimal. It’s like delivering a stack of bricks but transporting each brick independently, instead of renting a truck.
The Salesforce APIs
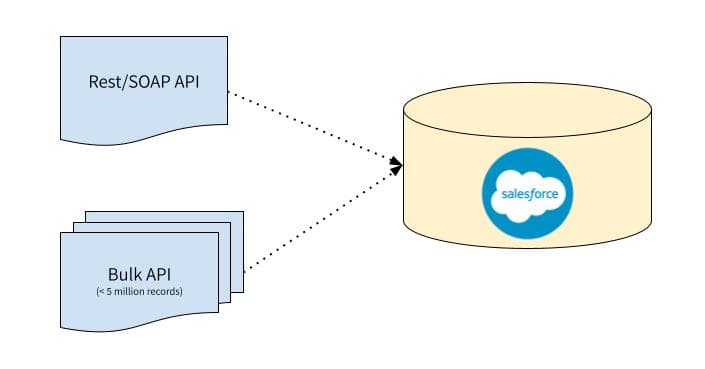
To facilitate data integration from external data sources, Salesforce CRM offers multiple interfaces: the REST API, the SOAP API, and the BULK API. These APIs are meant for copying external data, so they function according to an entirely different paradigm than data virtualization.
The SOAP and REST APIs
Both the SOAP and the REST APIs are convenient for interacting with the Salesforce CRM Lightning Platform. They’re optimized for real-time client-facing applications that update only a few records at the same time.
While they do support processing thousands of records, neither of these APIs are optimized for these kinds of loads. First of all, the amount of calls you can make to them is limited. Inserting vast volumes of data will make you run into these limits sooner or later. Furthermore, your inserts via the SOAP/REST API are atomic; if one row fails, the whole job will fail.
In the context of syncing the work of your data teams, the SOAP/REST API’s best use case would be quick and dirty uploading of a particular table because someone needs it very quickly.
The BULK API
The BULK API is built on REST principles and is the interface par excellence to load or delete data in bulk—as its name implies. The API operates asynchronously, consequently processing multiple batches that insert, update, or delete records in the CRM in parallel. No matter the size of the data set, the BULK API makes it particularly easy to process data from a couple of thousand to millions of rows.
If your data teams have a nightly job running that predicts each user’s propensity scores for a particular action—such as buying a product from a particular product category—the BULK API is best suited for processing these large volumes of data.
Using the BULK API, Salesforce CRM supports several configurations that allow you to integrate source data from your EDW using one of these APIs. A popular setup is to put a middleware in a position that performs updates in batches. Every time the middleware kicks in, it extracts the delta from the source system, transforms the data adequately, and calls the Salesforce BULK API to issue DML statements to make the required updates to the data in Salesforce CRM.
Another convenient way to use the BULK API is to use Salesforce Data Loader, an out-of-the-box client application.
Data Loader is Salesforce’s Data Import Wizard on steroids. While the latter only supports importing files of up to 50,000 records, Data Loader supports CSV files of up to 5 million records. Furthermore, it can be scheduled for nightly imports, making it another excellent choice to facilitate your data pipeline into Salesforce CRM.
Separating the Valuable from the Valueless in Your EDW
From the three outlined options for pushing data into Salesforce CRM, it’s clear that the API-centric approach is superior in a scenario where you want to shift control over the data-syncing process from IT to your data teams.
However, this isn’t a silver bullet. Pushing data is one thing; extracting it from your data warehouse and preparing it is another. One way to set this up is via a routine procedure that transforms the data and exports it as a CSV file to a storage bucket. Here, the file waits to be picked up by a nightly import configured via Salesforce Data Loader.
Nevertheless, having middleware sitting between your data warehouse and your CRM most likely is the best solution for decoupling the data wrangling from the ingestion as such.
Many middleware solutions that can sync data from one system to another with turnkey integrations are categorized as integration-platforms-as-a-service (iPaaS). Not only do they take away the complexity from integrating the data, but they also offer a visual low-code interface to set up the necessary transformations that precede it.
Any business user with a fair understanding of data principles can drag and drop elements to compile the data pipeline that serves the sales teams with the data and insights they need. Modern data teams prefer automation, versioning, and recycling. Those are three requirements that drag-and-drop solutions do not offer.
That’s where a tool like Hightouch comes in: an SQL-based middleware that syncs customer data from your data warehouse to your marketing and sales tools.
This saves your engineering team from having to write custom queries every time new business insights are needed, and it reduces the number of API calls you need to make to each platform because Hightouch diffs records rather than simply copying them. Teams that operate on a modern data stack paradigm should see Hightouch as the last mile of the stack that activates their efforts.
Wrapping Up
While there are many options for syncing data with Salesforce CRM, the BULK API is the way to go for batch uploading/updating data at rest in an enterprise data warehouse. With adequate middleware, you can put the responsibility of extracting, transforming, and pushing the data in the hands of business users or data teams.

















