
At Hightouch we are focused on delivering incredible value to our users. We accomplish this in a number of ways: unparalleled product, maniacal focus on the customer experience, and killer integrations that multiply the value of disparate tools. The Hightouch integration with Databricks is a prime example of all three.
First, a little background on Databricks. Unlike classic data warehouses, the Databricks Lakehouse prioritizes machine learning, data science, and streaming use cases. Databricks helps organizations centralize and unify their customer data at scale, making it a powerful foundation for enterprise marketing. This makes Databricks a compelling solution for huge consumer brands and enterprises, like ABM AMRO, H&M, Shell, Comcast, Biogen, and thousands more representing every industry vertical.
Their lakehouse platform gives organizations the ability to unify their customer data in a single platform, unlocking powerful marketing activation use cases, thereby unlocking tremendous value: Conde Nast reported a 50% reduction in IT operational costs. Comcast boasts a 10x reduction in overall compute costs to process data. JB Hunt reported $2.7M savings in IT infrastructure. All of these organizations have been able to efficiently tackle their analytics use cases and increase their ROI by consolidating their data into Databricks.
We are constantly focused on developing product features, integrations, and looking to expand the use cases that we can address. That’s why we are excited to partner with Databricks. The Hightouch integration with Databricks makes it easier for organizations to extract more value from their lakehouse by enabling marketing teams to easily build audiences, personalize campaigns, and engage customers across every marketing channel. No engineering resources required where customer engagement occurs and revenue is generated.
No more exporting CSV files. The days of passively looking at a BI dashboard are over. The incentive to put all of your data in your lakehouse has never been greater because all of your data can be activated, via Hightouch, at the push of a button.
Case Study: Nauto
One company already taking advantage of the Hightouch integration with Databricks is Nauto, a real-time AI-enabled driver and fleet safety company that predicts, prevents, and reduces high-risk events to improve and impact driver behavior before collisions happen.
With over 1 billion AI-analyzed video miles, Nauto’s machine learning algorithms have helped fleet drivers avoid more than 70,000 collisions and save nearly $300 million. Today, Nauto enables their business users and “Go-to-Market” teams to use Databricks insights directly within the tools they’re comfortable with, powering mission-critical workflows and customer experiences.
“Hightouch makes it trivial to pull data out of Databricks directly into the business systems that are familiar for business users and their workflows like Google Sheets for our Operations teams and Salesforce for our Support teams. With Hightouch, we use our single source of truth of our organization’s data to drive mission-critical workflows.”

Dr. Ernie Prabhakar
IT Biz Apps Manager
Integrating Hightouch with Databricks
Instead of manually exporting static files or building custom data pipelines out of Databricks, data professionals can now focus on driving business value by activating the data in their lakehouse. This integration between Hightouch and Databricks turns the lakehouse into a Customer Data Platform (CDP) and opens up myriad opportunities across business teams including:
- syncing custom audiences to ad platforms for retargeting,
- empowering GTM teams with product usage data,
- sending personalized emails based on customer behavior
- automating business processes
Moving data from Databricks to multiple destinations is easy with Hightouch.
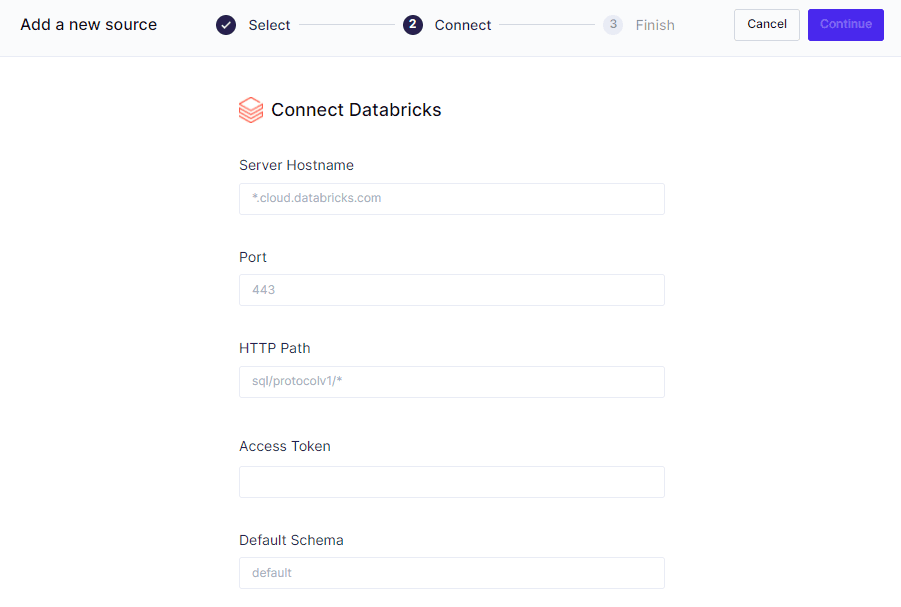
Step 1: Connect Hightouch to Databricks
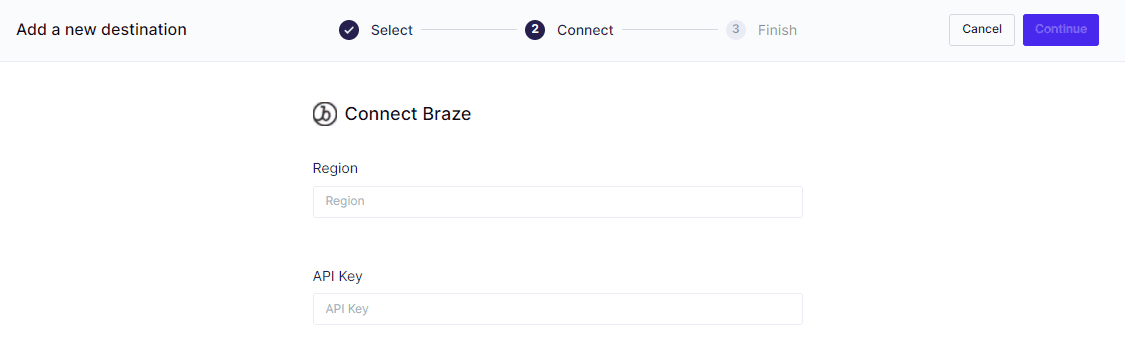
Step 2: Connect Hightouch to Your Destination
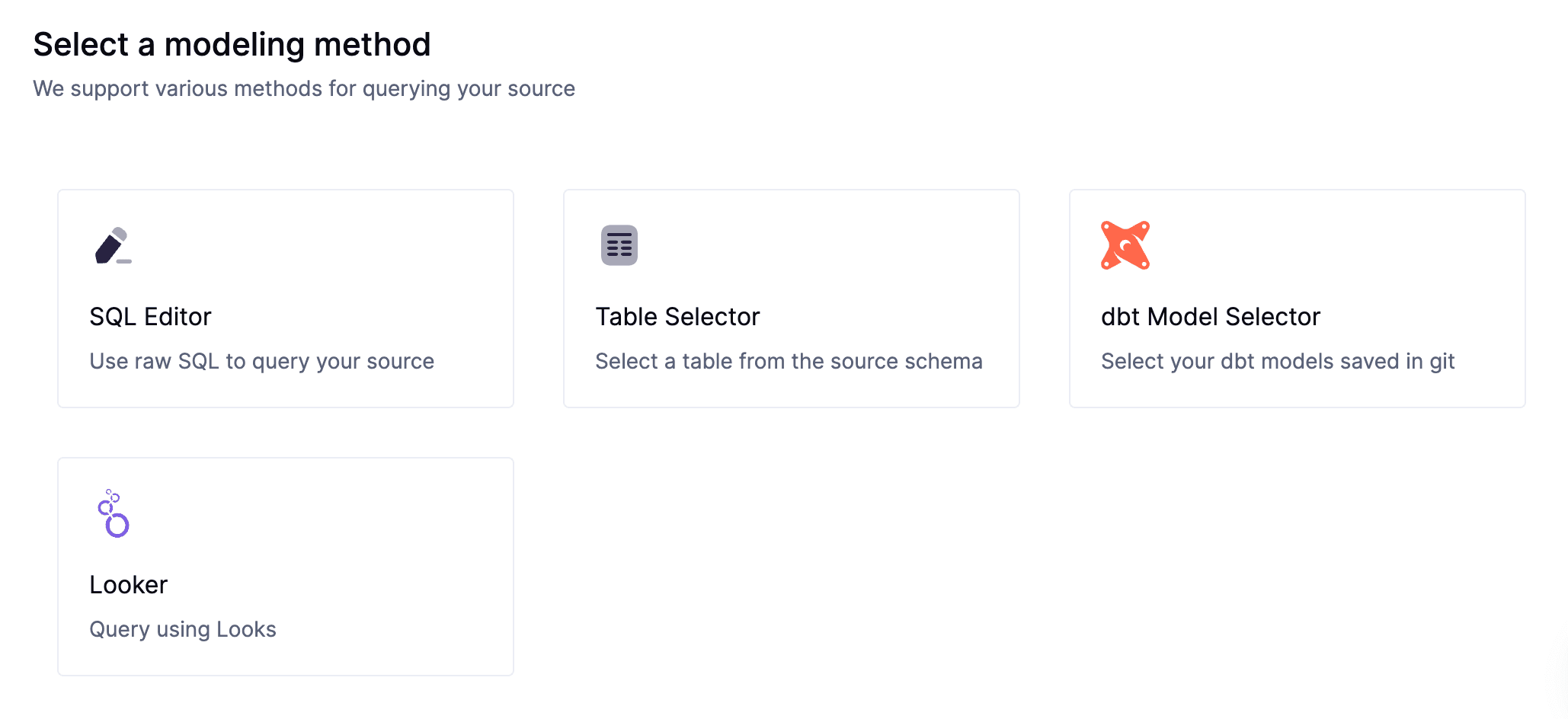
Step 3: Create a Data Model or Leverage an Existing One
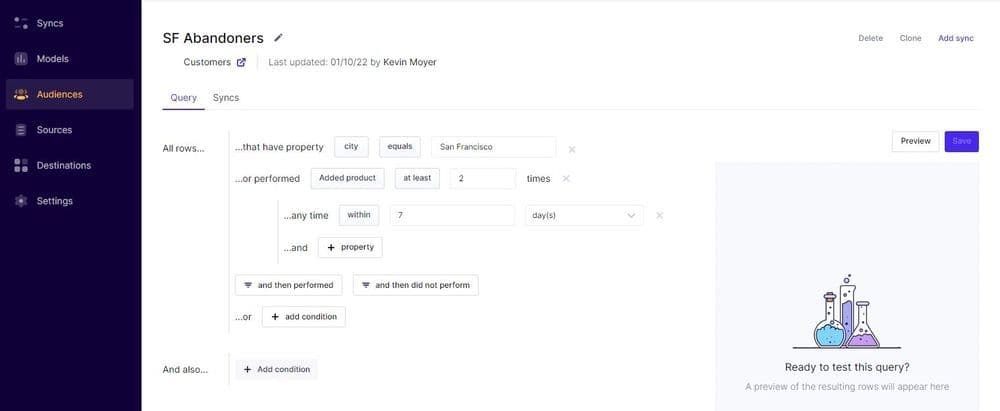
Step 4: Choose Your Primary Key
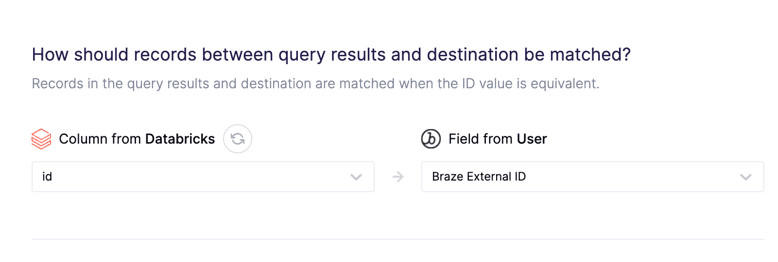
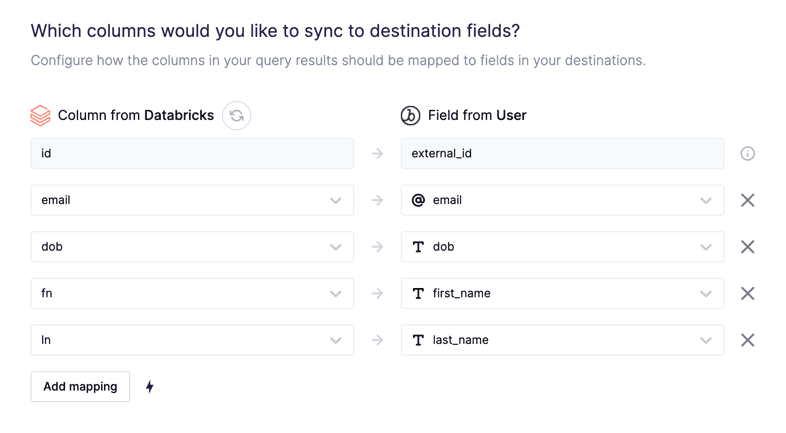
Step 5: Create Your Sync and Map Your Databricks Columns to Your End Destination Fields
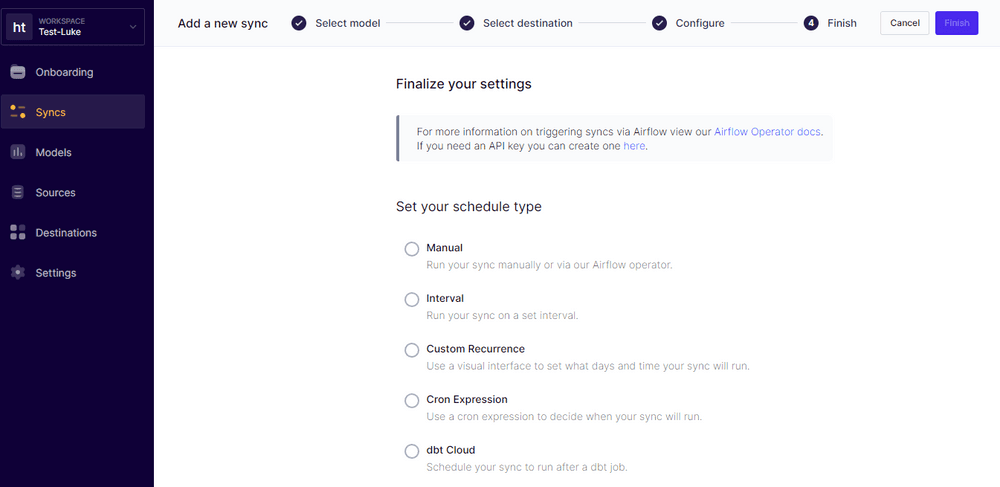
Step 6: Schedule Your Sync
Want to learn more? Check out our Complete Guide to Reverse ETL, or read our documentation on Databricks.

















