
Many companies are looking for ways to operationalize data from their data warehouses and data lakes. One company in particular, Datadog, is already leveraging the power of their cloud data to supercharge their business teams. The question is how?
To answer that question, we recently spoke with Romoli Bakshi, Engineering Team Lead at Datadog. Specifically, Romoli leads the Internal Analytics Infrastructure & Enablement (IAIE) team, which aims to provide data to the rest of the company on how customers use Datadog’s products and how the company operates internally so that they can make better, smarter decisions.
Q: Please tell us a little about Datadog and your role in the company.
A: Datadog is a SaaS monitoring platform that gives everyone in your organization — developers, ops, security, and business users — a shared understanding of your systems and the ability to resolve problems immediately as they arise. It allows you to access data on infrastructure health, application performance, logs, and more, so that you can see and analyze it all in one place and take action once you have that visibility.
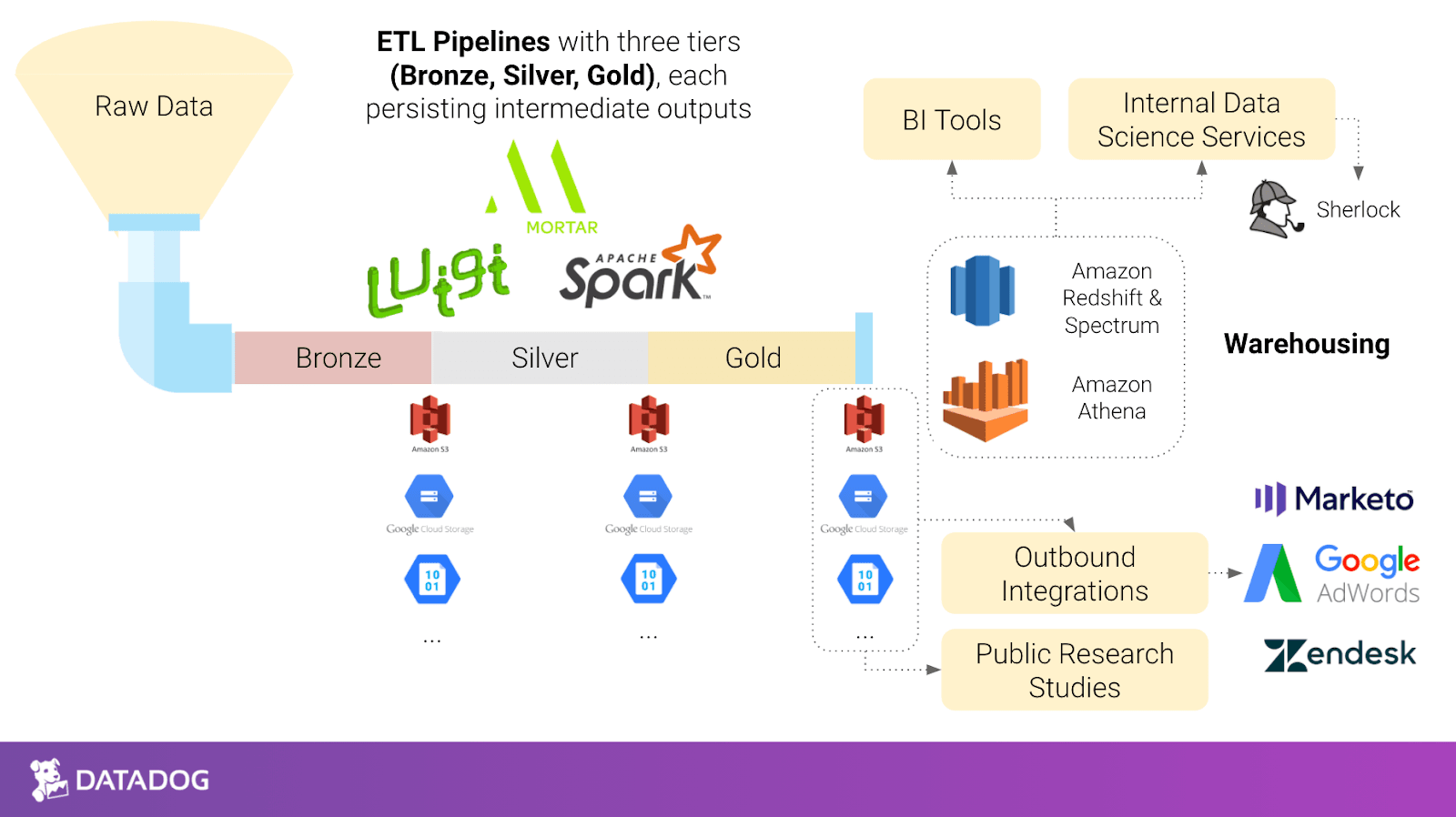
IAIE works specifically on both the infrastructure and enablement parts of providing analytics to Datadog teams internally. On the infrastructure side, we build and optimize Datadog’s analytics tooling, which includes designing Luigi and Spark-based frameworks to run our ETL pipelines, optimizing the performance and reliability of our data stores, and deploying and managing our BI tools and other in-house applications on Kubernetes.
The enablement part of IAIE focuses on making our data available where it’s needed most internally. Our goal is to integrate our data into other internal tools (such as Adwords, Zendesk, and Marketo) so that other teams can automate their workflows. We also analyze industry trends for both internal and external research and build prescriptive and predictive applications from scratch to influence action around the company.
Q: What is the "analytics stack" at Datadog?
A: Our ETL pipelines are built on Luigi and Spark. We use Luigi for task dependency management and Spark for heavy batch processing. Our pipelines are built with a standard tiered architecture in mind, and so we save intermediate ETL outputs to cloud storage (AWS, GCP, Azure, and more) and load our final datasets to Amazon Redshift, Spectrum, and/or Athena for analytics. Finally, we have a suite of BI tools, notebook tooling, and other services that enable people to interact with our data. All of those tools read from our data warehouses or intermediate cloud storage locations.
Q: What are some of the projects your team owns?
A: Our team covers a wide array of projects at Datadog. We work on very diverse initiatives and wear a lot of hats!
On the infrastructure side, we’re currently working on redesigning our ETL pipelines and user-facing services to work with the company’s multi-regional presence. Datadog operates in every major cloud provider and region, and so expanding both our developer and user tooling to support that and grow with that is critical.
We’re also working with other data engineering teams internally to deploy a new service that tracks data quality and data lineage for all of our datasets. This service will keep track of what data is healthy and what’s not and automatically trigger self-healing mechanisms on demand. It’s just one of our many investments in pipeline observability.
On the enablement side, we work mainly on outbound integrations, internal data science projects, and research.
Outbound integrations are the services I mentioned previously that push our data to other tools (Marketo, Zendesk, GoogleAds, and more). Other Datadog employees leverage our product data to automate actions in those tools and make more informed decisions.
For the internal data science projects - we’ve built a few from scratch already and are continuing to build new features on top of them. In the past few months, we launched a new project called Sherlock; it’s an internal notification system that looks for specific insights or signals in our customer data and alerts the appropriate Datadog employees of these insights so that they can take action.
Finally, the enablement part of our team also collaborates with Product Management, Writing, and Design to publish data-driven research studies about what technologies are hot right now and how they’re being used by our customers. Datadog is in a unique position where we can learn a lot about technical best practices from people who use our product, and so we use the vast telemetry and observability data we have to derive insights and publish them on the Datadog site. If you’ve ever seen our State of Serverless piece or our Container Study — we worked on those!
Q: When did your outbound integrations project start?
A: The first engineer who started Internal Analytics at Datadog actually came from the Research & Writing team, which was historically part of Marketing. At the time, he and the rest of the team witnessed the challenges the Marketing teams faced in their daily operations and realized that automating their workflows would be a super valuable and necessary next step.
Q: What teams and systems does Datadog power from its data warehouses?
A: Our BI tools and services as a whole serve every part of the company: customer success, sales, marketing, engineering, design, product management, executives, finance, recruiting, and everything in between.
Each of our outbound integrations generally focuses on helping specific teams with their workflows. For example, on the marketing side, we push data about what level of engagement each customer has had with Datadog and our products to Marketo to enable Marketing to more effectively reach out to people who show a real interest in Datadog. These people may have started a free trial, clicked around a specific part of our app, attended our Dash conference, or taken other actions indicating interest in the space.
We also push offline conversion data to Google Ads for our Demand Generation team within Marketing. Internally, we track what happens after someone clicks on a Datadog ad — for example, whether they later install the Datadog agent or start using a specific product. This information is valuable to the Demand Generation team because it allows them to track ad campaign efficacy.
To give another example - one other team we’ve created several “outbound integrations” for is our Solutions Engineering team; they provide support to Datadog customers through Zendesk. Because support tickets that come in can span a wide array of technologies and come from customers with varying needs operating in diverse environments, it’s often hard to route these tickets to the people with the right expertise. To help with this, we create organizations within Zendesk on behalf of Solutions and enrich that organization with metadata on our customers, so that they can quickly understand who has asked a question, what their Datadog environment is like, and how they use Datadog, before providing support.
We have many more projects in the works, but I’ll skip those for now.
Q: What is the business impact?
A: I’ll resort to the teams we work with to answer that. :)
According to Scott Anderson, Manager of the Demand Generation team:
The integrations created by the Internal Analytics team empower us to see down-funnel performance metrics in near real time, at a granularity that would otherwise be impossible. We now optimize our campaigns more efficiently and spend fewer hours every week focusing on manual reporting. The integrations have helped us save significant amounts of money, hundreds of people hours, and help us focus on the initiatives that will bring in new business.
According to Elizabeth Dahl from the Marketing Operations team:
By integrating usage data into Marketo, the marketing team is now able to target users based on the integrations and products they are using and actually care about. We can customize messaging based on usage and provide more meaningful content at the right time to the right people. For example, if we are promoting a webinar on Kubernetes, we now have insight into all users with a Kubernetes integration and build our target audience based on this information. It takes out a lot of the guesswork and we no longer have to rely on mass promotions to users about products and integrations they aren't using.
Having usage data at our fingertips has saved the marketing ops team countless hours of work. Before we had this integration, we would have to request segments from our Analytics team, import users into Marketo, and add the target audiences manually into our campaigns. Now, the whole process is automated and we've removed having to request lists and passing spreadsheets between teams.
Q: What are some technical challenges your team has encountered?
A: First and foremost: the tremendous scale of our data. This is something that teams at Datadog are familiar with already, since we ingest trillions of metric points daily. But parsing through that data to determine what’s useful and what’s not for each pipeline or model we write is tough. To help with the sheer amount of data, we rely on distributed tools like Spark and Redshift.
The scale of our data also impacts how we interact with third-party APIs, which we do a lot of since we ingest data from so many different sources. There was a point at which we were sending so much lead metadata through our Marketo outbound integration that we had to refactor it entirely to send batch jobs via the Marketo Bulk API and simultaneously avoid rate limiting. But making changes to match that growth forces you to rethink naive solutions and replace them with scalable ones.
Another technical challenge is the fact that Datadog operates in all major cloud providers and regions, and data in each region must comply with certain privacy laws. Creating a robust, multi-regional architecture that is legally sound is a huge must and hard to design for.
Q: What does your data architecture look like?
This is the architecture at a high level.
If you're interested in syncing data from your data lake or data warehouse into 300+ destinations (e.g. Salesforce, Marketo, FB/Google Ads, etc.) with just SQL, schedule a demo, email us at hello@hightouch.com, or try Hightouch now.

















