
Most of your time as a data scientist or data analyst is spent working with data. This means a lot of time working within Python with libraries such as Pandas and NumPy or in R and libraries such as dplyr and tibble to get data in a format that can be used.
You would think doing such tasks would be better suited in a relational database management system (RDBMS), so you can use SQL to perform joins, aggregates, transformations, and filters.
However, there are major issues when using RDBMS, such as being difficult to install, set up, and maintain. Data transferring can be slow to transfer to and from the client, and they have a poor interface with the client application.
Even though logically, using SQL to interact with data would be a better choice because it is a more common method for manipulating data, these problems prevent it from being used.
Until now.
DuckDB addresses all the problems that an RDBMS has so that a data scientist or data analyst can have a world without the difficulty in setup but still have faster queries. Let’s find out what exactly DuckDB is and some of its benefits.
What is DuckDB
Hannes Muhleisen and Mark Raasveldt created DuckDB, with the first version released in 2019. DuckDB is a free, open-source embedded analytical database. Hannes and Mark knew that using a database system was the better option in a data science role because of how they offer ACID properties, they offer fast and flexible query execution, and offer integrity checks.
However, the reality is that because of how difficult they can be to set up (a PostgreSQL instance can take over an hour to setup) they are typically avoided. They can also be costly, making data scientists turn to other solutions, creating libraries like pandas and NumPy or dplyr and tibble to interact with their data.
These problems were what Hannes and Mark set out to solve and what drove DuckDB to be built.
DuckDB has been described as the SQLite for analytics. SQLite is a popular solution for RDBMS because it’s embedded, meaning that it has minimal setup required, and you can get started within minutes.
And this is the same as DuckDB.
The difference between SQLite and DuckDB is that SQLite is an embedded online transaction processing (OLTP), whereas DuckDB is an embedded online analytical processing (OLAP).
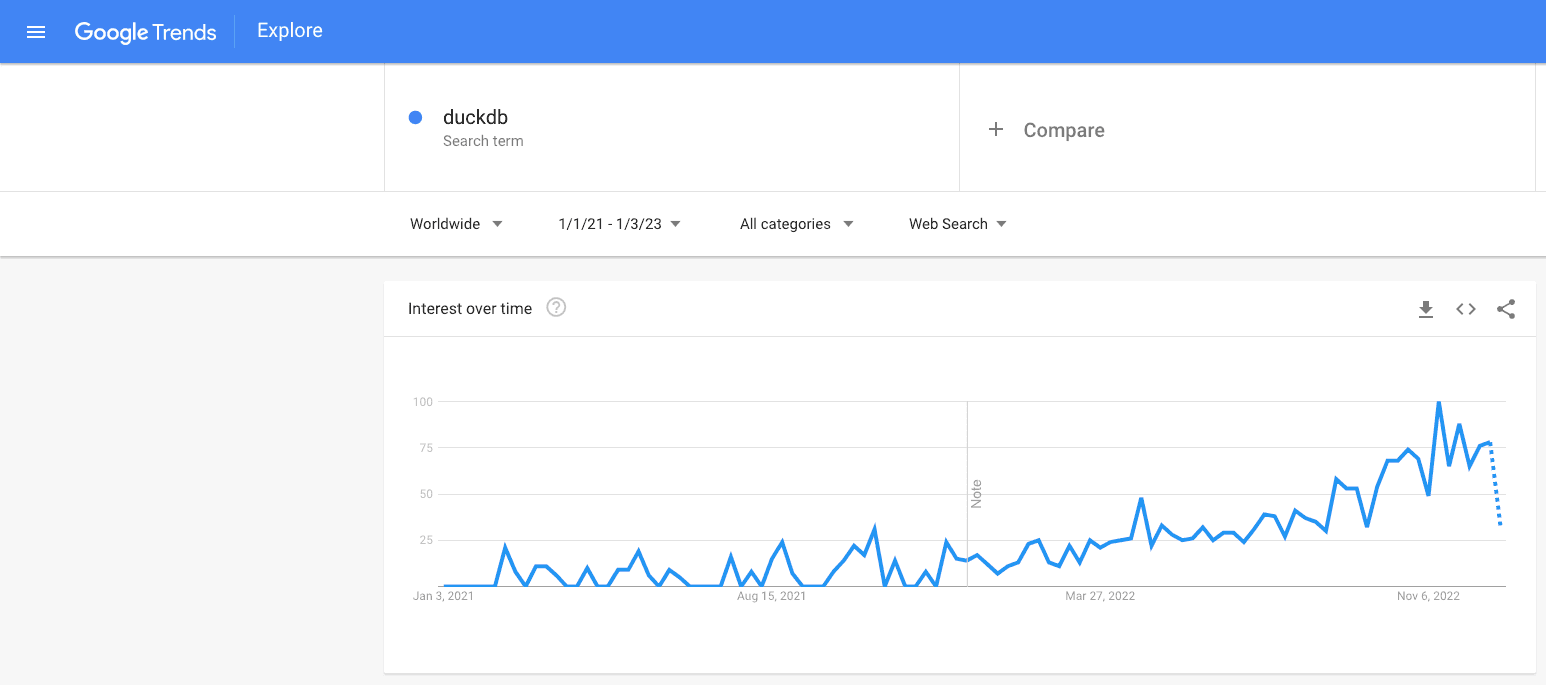
DuckDB is growing in popularity which you can see from the search trend on Google. DuckDB is one of those tools people are just waiting to find; once they have, it will change how they work. And companies like Hex and deepnote are already using DuckDB to power their software.
Features of DuckDB
We’ve mentioned some of the features of DuckDB, but let’s look at all that DuckDB has to offer.
Simple Installation
Because DuckDB is an embedded solution, it is super easy to install. The installation instructions differ depending on the environment you want to install DuckDB, but usually, it only consists of a line of code or two.
Looking at the installation of DuckDB into Python, it’s simply:
pip install duckdb==0.6.1
SQL Support
In the 2022 Stack Overflow developer survey, SQL was the third most popular programming language, and the fact that it’s still around after being developed in the 70s clearly shows a stickiness that will take a lot to replace it.
Because SQL is easy to learn, versatile, and ubiquitous, DuckDB set out to be a SQL database from the beginning. They also aim to stay as compatible as possible with the SQL syntax already widely used in the industry, like SQLite, MySQL, and PostgreSQL.
Free and Open Source
One of the great features of DuckDB is that it’s free to use and open source. There will likely be some sort of monetization in the coming future, but it’s great to see helpful free solutions. Being open source also increases the number of people who can contribute to the project, allowing development and improvements to happen faster.
Built as an OLAP Data Engine
To better understand this technology, it’s worth briefly mentioning the two main forms of data processing systems; online transaction processing (OLTP) and online analytical processing (OLAP).
OLTP is usually used for supporting user-facing applications as the queries are short and fast, the tables are normalized, and transactions such as INSERT, DELETE, or UPDATE are processed.
OLAP is typically used for analyzing massive amounts of data. You’ll likely see the data stored in a data warehouse or a centralized location. It’s typically used to perform analysis to make data-driven decisions. OLAP systems and workloads run complex queries, their tables are de-normalized and are focused on the speed of read operations.
DuckDB is designed as “embedded OLAP,” making it perfect for the role of a data scientist or a data analyst, exploring and uncovering insights from data.
Fully ACID Through MVCC
DuckDB provides ACID properties giving you guarantees on your transactions, so it doesn’t fetch back incorrect results. It does this via DuckDB custom bulk-optimized multi-version concurrency control (MVCC).
The Complete Guide to Reverse ETL
Read our whitepaper to learn where Reverse ETL fits in the modern data stack.

Benefits of Duckdb
Now that you’ve seen the features of DuckDB, what do they actually mean to you? Here are some of the amazing benefits of DuckDB.
It’s Fast
DuckDB is fast, which you might not think is possible, as you’re running the queries locally. DuckDB uses vectorized data processing, which helps make efficient use of the CPU cache. It also allows batch values to be processed rather than tuple-at-a-time or column-at-a-time. All of this produces speeds 20 to 40 times faster than traditional systems.
Ease of Use
As mentioned before, DuckDB is simple to install. Choose your environment, run a simple line of code, and it’s ready to go. DuckDB is created to have no external dependencies, so you don’t need to worry about neglected libraries causing problems.
No Management Needed
Because DuckDB runs like a CLI or a Python library, you don’t need any type of management. DuckDB just works! The lack of management means removing the admin that would have been needed to manage permissions, and you don’t need to worry about managing the server, as DuckDB runs locally.
Makes Getting Started with ML Easy
DuckDB helps to skip learning any Python or R libraries that assist with data wrangling. Without DuckDB, you would have to learn something like Numpy or Pandas. However, with SQL being one of the most popular programming languages, the barrier to entry into data science has just got easier.
A Reddit user in a discussion about DuckDB commented,
"I never heard of DuckDB until I read this thread. I'm a noob to this stuff, and I've been lurking on this thread for only a few days, but I'm figuring out how to get into machine learning. For the last few months, I've been following the DS channel, looking at YouTube on learning data science, and looking at a few books. They are all like, "well first, you first need to learn numpy and pandas or R." In my current day job, I only have two tools- SQL and excel, so I've got pretty proficient at building lengthy SQL queries for exactly the type of tasks which DuckDB is designed to streamline. Looks like DuckDB will get me up and running faster than the more common paths."
DuckDB Use Cases
Interactive Data Analysis
The most popular method for data scientists working on data is to use programming languages like Python or R, along with libraries such as Pandas and dplyr. DuckDB is coming along and breaking the mold and letting data analysis be performed locally at great speeds and using a more common and simple programming language, SQL.
Edge Computing
As edge computing has gained popularity in recent years, using an embeddable database like DuckDB to analyze data at the edge has become more common. Edge computing is a type of distributed computing that brings computing and data storage closer to where it is needed, improving response times and conserving bandwidth. Better results can be obtained quicker by using an embeddable database like DuckDB to analyze data at the edge.
Getting Started with DuckDB
Getting started with DuckDB is simple. Because it's embedded within the host process, doesn't need a server of any type, and has no external dependencies, it is as simple as running a couple of lines of code.
You can find full DuckDB installation instructions depending on the environment you require over at the DuckDB documentation.
If you want some more resources to learn about DuckDB, have a look at the list below:
- DuckDB – The SQLite for Analytics [Video]
- DuckDB: an Embeddable Analytical Database [PDF]
- What’s up with DuckDB (A Toronto Modern Data Stack Meetup) [Video]
- DuckDB Docs [Website]
- DuckDB blog [Website]
The Complete Guide to Reverse ETL
Read our whitepaper to learn where Reverse ETL fits in the modern data stack:
- The evolution of data warehouses
- The key to activating your data
- Reverse ETL use cases
- Build vs. buy

















