
Introduction
As the folks at dbt like to say, dbt represents the T in ELT. The transformations powered by dbt are critical because they convert data into a structure that makes the data a lot more usable for businesses. The types of transformations can vary from simple ones such as cleaning up strings or changing data types to applying complex business logic for metrics such as customer retention.
It used to be the case that Engineers owned the transformation process, typically within an ETL tool where data was extracted and transformed into pre-determined structures, and then loaded into a warehouse for Data Analysts and Scientists to work with.
In the current paradigm, with the advent of dbt and other SQL-based transformation tools, there’s no longer a skill gap preventing analysts from creating the transformations themselves. One of dbt’s core themes is to empower analysts, and as we’ll see, there are many reasons analysts, and not engineers, should manage the transformation process using dbt.
Create effective data transformations
Every data analyst and scientist has dealt with difficult data structures. For instance, in one of my first jobs analyzing product sales, I had to recreate many of the transformations outside of the data pipeline just to determine what plan a customer was on at the time of the purchase. These types of difficulties arise from many factors such as the wrong data granularity, bad or missing logic, or sometimes even a lack of transparency.
As a result of these issues, dbt came up with an idea that analysts should own the data transformations. Analysts could create more granular structures where necessary, aggregate views for simplification, and apply the logic and business requirements they’ve gathered.
Backend engineers shouldn’t be responsible for any of these tasks. It’s out of their purview to track definitions of metrics and long-term analytics goals. Additionally, it has an obvious flaw that the designers of the data structures aren’t the ones actually using it.
dbt allows companies to maximize the strengths of both analysts and engineers. Engineers can ensure data is captured and stored properly in the backend, while analysts can use dbt and other tools to derive meaning from the data.
Test accuracy of data transformations
Similarly, Data Analysts should constantly test whether their transformations actually work properly. dbt provides two main ways to test data transformations — schema tests and data tests. In both cases, analysts are preferable to engineers to ensure the accuracy of the transformations.
dbt Schema Tests
dbt schema tests are used to check basic information about the columns in a given table. Basic examples include verifying if a field is unique, not null, or contains specified values.
With this in mind, it’s clear that analysts should manage these tests. It’s one thing for engineers to be responsible for these checks on the source data. However, when considering downstream models built on complex logic and joins, the analysts are the only ones with the necessary knowledge to design and enforce these tests.

dbt Data Tests
dbt data tests are much more flexible than schema tests. They allow users to create any query on the data that should return 0 rows if successful.
From the dbt docs, an example of a basic data test checks whether all orders have a payment that is at least $0. In their example, the test simply aggregates the data for each order and then looks for records that don’t match the criteria in the “having” clause.
Data tests can become much more complicated and can involve complex joins and logic. Just like we saw with the schema tests, the analysts are better suited to come up with all of the scenarios they’d like to test. Analysts will know what use cases to watch out for, and since dbt just requires SQL, they’ll be able to implement and monitor the tests themselves.

Test underlying source data
Because the underlying source data is so valuable, it’s actually helpful for both analysts and engineers to be responsible for checking its accuracy. While the engineers track whether all data is captured and can be used properly by the frontend, analysts check that the data makes sense from a business perspective.
Based on these differences and the function of dbt, once again it’s evident that the dbt source tests should be managed by the analysts. The source tests allow analysts to check assumptions they have about the underlying data.
Both the schema and data tests mentioned previously can be run on the source data. One of the most critical tests to run on source tables is to verify the granularity using the unique schema test.
Additionally, dbt allows analysts to check the freshness of the sources flowing through the system, which can even be configured to send alerts if the data becomes too stale. In my experience, stale data has often been the culprit behind issues that stakeholders notice in downstream analytics dashboards, and that is why analysts should always ensure that data freshness is taken care of.

Provide transparency with data documentation
In order to make data-driven decisions, many companies strive to provide all employees with the data and tools they need to excel in their functions. In practice, this means various stakeholders may have access to the data warehouse, business intelligence tools, and even sales tools like Salesforce that are populated with data using a Reverse ETL tool like Hightouch.
However, simply providing access to data is not enough. Data-driven companies must commit to making their data usable by taking the time and effort to document how employees should use the data. As we all know, documentation is not something that can be set and forgotten. It’s a living document (sorry, I had to) that must constantly be monitored and updated.
Once again, engineers cannot assume the role of communicating and sharing best practices. Instead, data analysts and scientists must ensure that their stakeholders understand the context of the data, and there’s no reason this duty should change in the context of dbt.
dbt provides very simple and effective methods for analysts to create data documentation. Through dbt, users can generate descriptions for every table and for every column in those tables. As much as I like using tools like Wiki for general notes, it makes much more sense to create and update the documentation directly in the source. And by doing so in code also enables version control over the documentation.
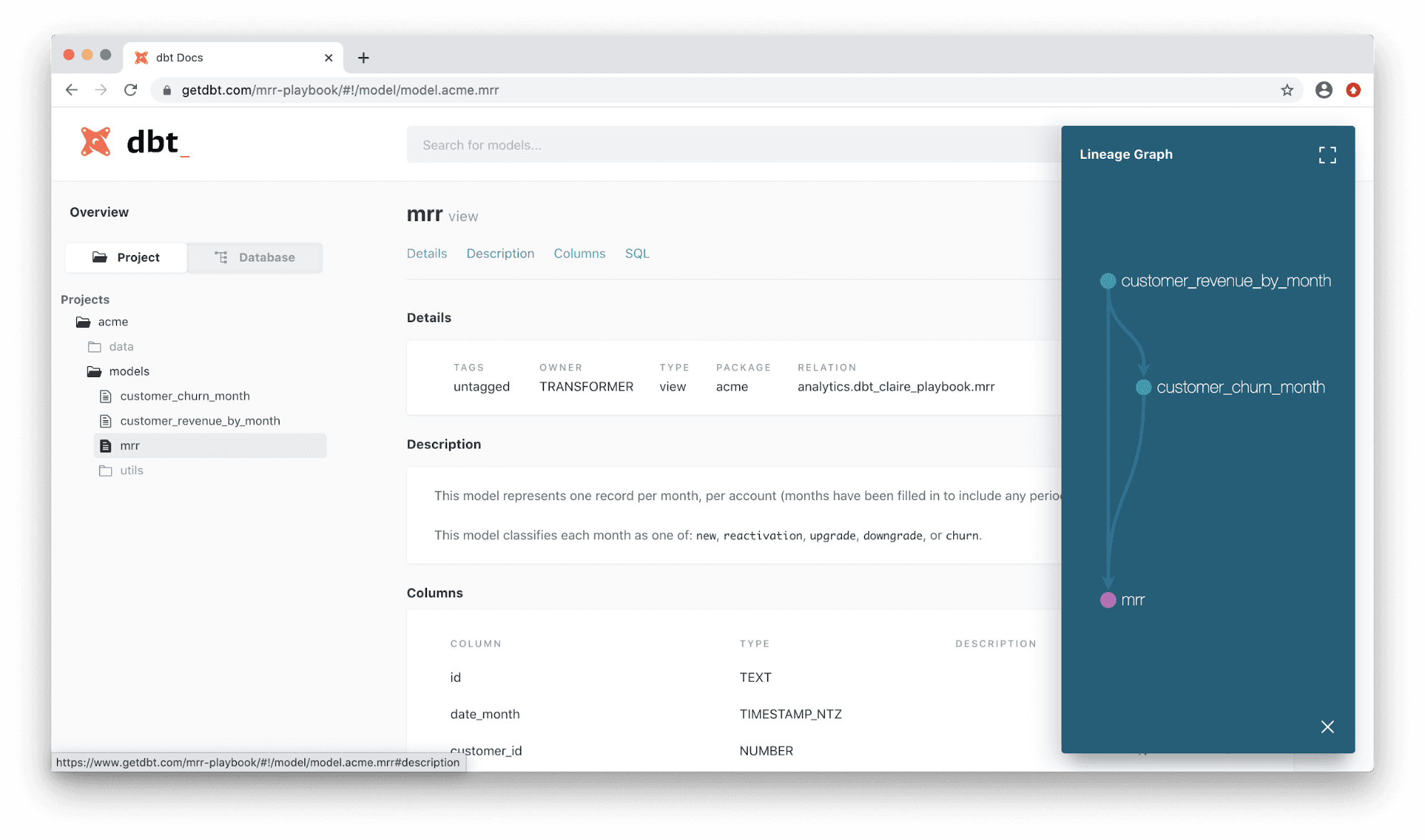
Now, one of the questions I’ve always run into from non-analysts is “How do I know which table to use?”. It’s a great question. Because the number of tables and columns can quickly become overwhelming; it’s not always straightforward.
With dbt’s documentation and other functionality, analysts can address this in a couple of ways. The simplest way is to create specified data marts for end-users that contain all the information they need for a specific use case. Having data marts makes it possible for users to learn only about a few relevant tables.

For users who need access to more of the data pipeline, I’ve found dbt’s DAG, in conjunction with documentation, provides the necessary framework to understand which tables to use. The DAG shows users how data flows through the system into different tables, and the documentation provides more information about each table.
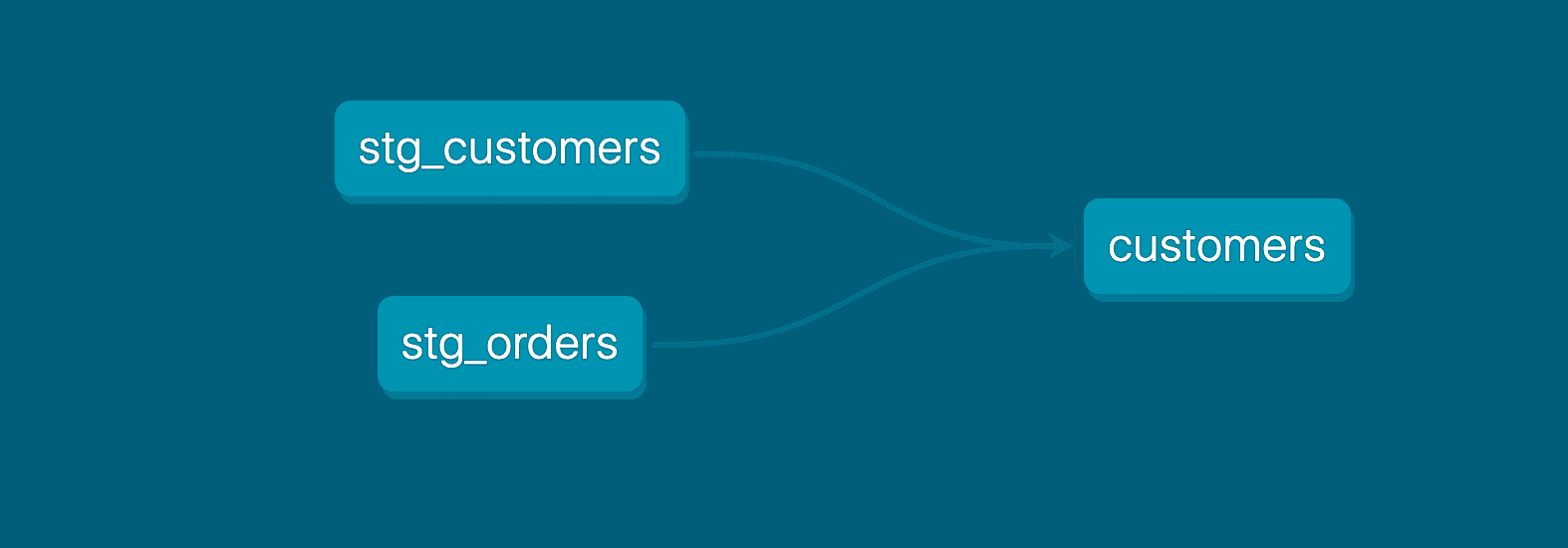
Practice DRY principles in analytics
Finally, dbt’s framework allows data analysts to continue the DRY principle of software development. Reducing redundant code not only saves time for analysts but ensures data methodology remains consistent throughout the pipeline.
dbt’s DAG, as discussed previously, is a great start for analytics teams to monitor their code. In my experience, the DAG should be consistently checked to see where metrics are defined. Oftentimes, the DAG makes it evident where code is duplicated. One other benefit of the DAG is that analysts can easily visualize how all of their data is flowing, making it clear when data is taking a circuitous or inefficient route.
By having analysts manage dbt, companies can empower analysts with the tools to track the effectiveness of their code. Understanding the source of truth for any metric is one of the biggest issues growing analytics teams face. Again, this could be due to data residing in various places or methodologies not remaining consistent throughout the pipeline. Although the DAG doesn’t completely solve this problem on its own, it is a primary tool that analysts should take advantage of to address these potential issues.
Conclusion
While dbt would inherently be useful for engineers as well, it marks the perfect transition point in the data pipeline to be managed by Data Analysts and Scientists. At this juncture in most architectures, data is simply being prepared to be consumed by downstream stakeholders.
Because analytics teams have the knowledge to apply data transformations, test whether they work properly or not, as well as document how they function for the organization, the analysts are most suited to manage dbt. dbt even provides the additional benefit to analysts of making their code more effective.
Lastly, and most importantly, because dbt is a SQL-based tool, it can be used almost immediately by analysts. They already have the skills necessary to take advantage of the wealth of features provided by dbt, and it even encourages them to grow their skills and start coding like engineers.

















