
This is a guest blog post from our friends at Castor. Castor is a smart data catalog that helps companies improve their Data Experience. They offer an automated, plug-and-play solution to unify the modern data stack through intuitive data discovery, documentation, and lineage capabilities.
Data Catalogs: What and Why?
In the past few decades, a major focus of innovation has been on generating more and more data. However, the current challenge is how to effectively manage and govern this data. This is why Data Catalogs are becoming increasingly popular, as they provide a solution for organizing and governing data assets at scale.
A Data Catalog is a system that stores and organizes information about data sources and their contents. Data Catalogs are used to facilitate data discovery and exploration, enabling users to quickly find and access data for analysis and decision-making.
Data catalogs help data and business teams with the following:
- Data Governance and management: a Data Catalog serves as a central hub for metadata and definitions for data assets within an organization. It provides a single location for storing, managing, and accessing this information.
- Discoverability and accessibility: find your data faster through a powerful searchable interface and standardized metadata. Discoverability improves data stakeholders’ productivity.
- Collaboration and sharing: stakeholders can use the Data Catalog to check for ownership of datasets or leverage the work done by peers by browsing through popular queries.
- Data lineage and traceability: data lineage shows how data assets are related. This allows stakeholders to understand data flows and thus troubleshoot data issues faster.
- Security and privacy: Data Catalogs help enforce data policies and provide controls for access to data assets
Data Catalogs also contribute to enabling Data Activation, the approach consisting of making actionable data accessible to business teams, for operational use cases (sales, marketing, finance, customer success, etc.).
Enabling Data Activation requires business teams to access meaningful, trusted data. Reverse ETL and Data Catalogs both play a role in bringing this about, and their interplay unlocks unprecedented levels of data democratization.
Overcoming Obstacles to Unlock the Power of Data Activation
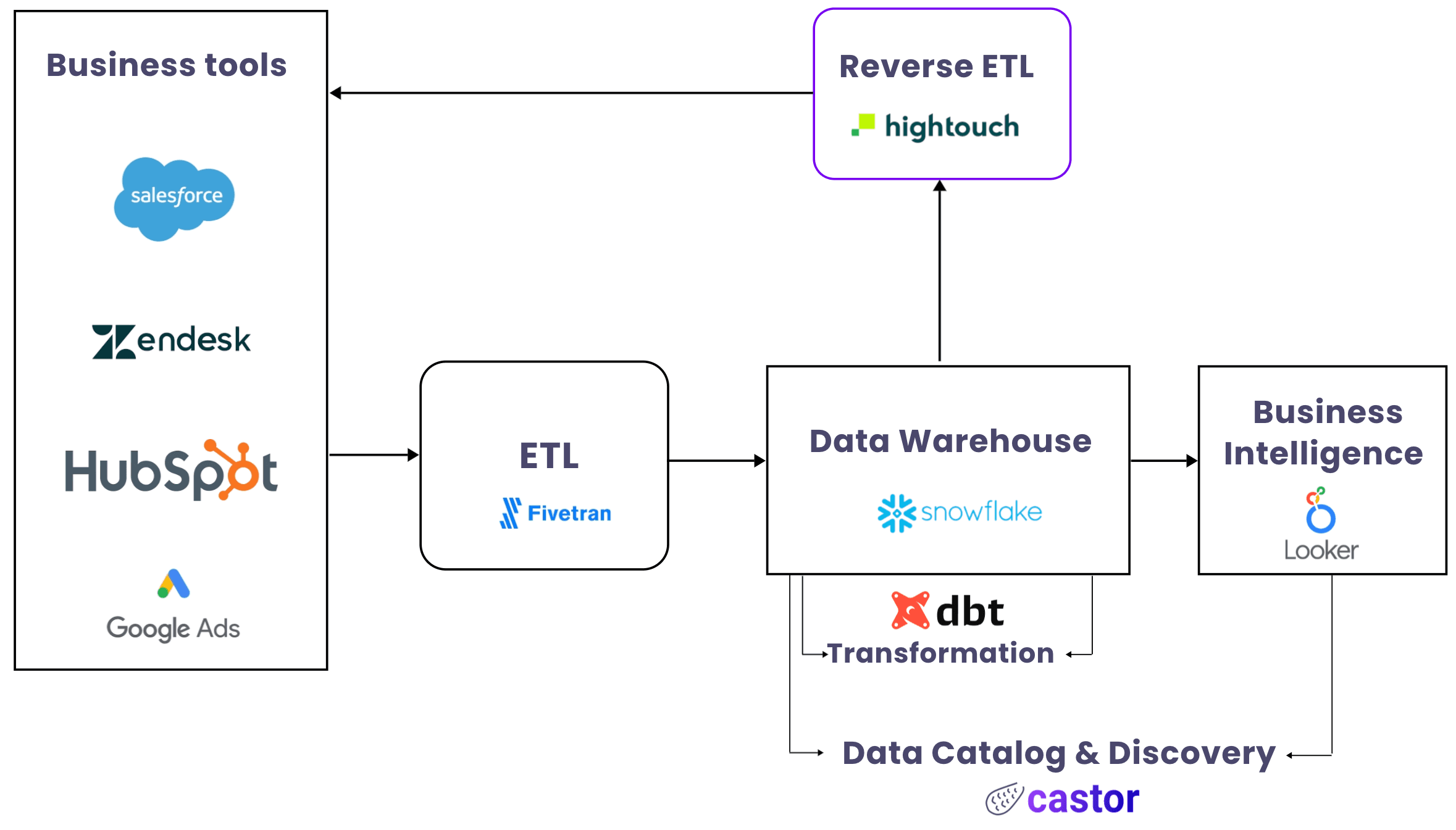
The Data Discovery and Reverse ETL Tandem
There are two barriers that block business teams accessing data:
-
The data is stored in the warehouse. Non-technical teams can't access or query the warehouse because they aren't familiar with SQL.
-
The data warehouse is complex and ever-changing, and it’s often difficult to understand what’s going on in it, especially for non-technical employees. This complexity is driven by:
- Table proliferation: The data warehouse is constantly updated with fresh data from various sources. Thanks to dbt, data transformation and modeling have become much more accessible. Tools like dbt allow data engineers to easily create new tables for ad-hoc use cases; however, this explosion in table creation can increase the load on the warehouse and may lead to additional chaos.
- Poor documentation: In many organizations, the data sitting in the warehouse is not well-documented. This makes it near impossible for non-technical people to accurately locate or understand the tables they need for their use case.
Yet, data democratization requires that people in the organization can both access and use the data.
This is where Data Catalogs and Reverse ETL come into play. Reverse ETL provides access to the data, while a Data Catalog provides the trust part. Both approaches focus on resolving the challenge of leveraging untapped data sitting in your warehouse. We’ll explain how these tools can work in tandem to enable data democratization.
The Data Catalog and Reverse ETL in Tandem: Creating the Virtuous Cycle of Data Activation
Your Data Catalog helps to create context around the data, while Reverse ETL brings the data to the right places. These two processes are complementary
The relationship between Reverse ETL and Data Cataloging is based on the idea that Reverse ETL excels at moving transformed data to a myriad of destinations, without needing to explore a data warehouse to discover which datasets should be moved. By contrast, Data Cataloging helps you explore a data warehouse and discover which data might be worth moving. This motion is known as Data Discovery.
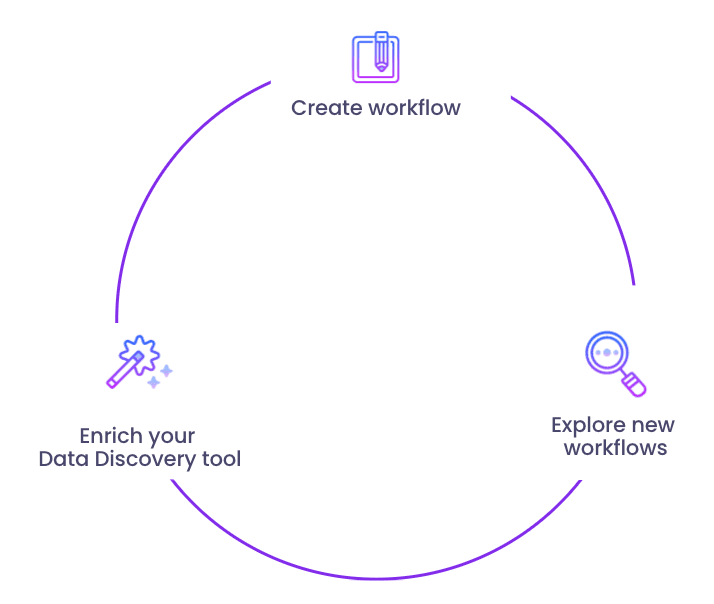
The virtuous Cycle of Data Activation
The interplay of Data Discovery and Reverse ETL creates a virtuous cycle:
- Data discovery supercharges your ETL tool when it comes to workflow creation. Data discovery helps you find the right data assets to send into downstream SaaS tools. Before sending data from the data warehouse to operational tools, you first need to understand what’s sitting in your data warehouse. For example, let’s say you have a Lead Scoring table in your warehouse, and you would like to send it to Salesforce to make it accessible to your sales teams. Your sales operations team can rely on a Data Discovery tool to find the right lead-scoring table in the data warehouse. This ensures the correct metric is then synced into Salesforce (via Reverse ETL).
- Your Data Catalog also helps uncover other potential Reverse ETL use cases. Let’s say - sales ops is enabling a workflow to move a specific business metric into a downstream tool (e.g syncing lead scores into Salesforce). While exploring the Data Catalog to find the lead score metric, sales ops might unearth a new data point worth activating to business users, for example exporting customer segments calculated on top of the warehouse to Intercom. By assisting in data discovery, your Data Catalog can help you more fully leverage your Reverse ETL tool.
- The more Reverse ETL workflows you want to deploy, the more warehouse exploration you must undertake. As you do so, your Data Catalog usage will rise and become more important in your company. This will contribute to making data documentation a priority in your company as you'll need to make sure that your Data Datalog can keep up with all of your business-critical Reverse ETL workflows to make sure your business continues operating smoothly.
The combination of Reverse ETL tools and Data Catalogs is like a superpower duo. The more Reverse ETL workflows you create, the more Data Catalog usage increases. The more Data Catalog usage increases, the more Reverse ETL use cases you uncover and the more powerful your organization becomes. This is the virtuous cycle of Data Activation.
Get Started
Activating your data means putting trustworthy, quality data in the hands of your business teams. Data Catalogs like Castor help with the “trustworthy” part, while Reverse ETL tools like Hightouch makes it easy to sync that data into the right places.
The interplay of both tools is extremely powerful. Your Data Catalog helps you ensure you are migrating the right data from the data warehouse to business tools. In return, reverse ETL improves your Data Catalog’s usage and the quality of the documentation.
If you want to learn more about how to enable this virtuous cycle for your teams, get in touch with Hightouch and Castor.















