
Data apps are starting to drift into the greater conversation among data teams, mainly because data warehouses are getting faster and more widely adopted.
This very good primer on data apps refers to them as “the future” because companies already own the data in the warehouse and have full control over that data.
But especially in the tech world, it can sometimes be very difficult to tell a fad from a trend. Are data apps the future or just a flash in the pan?
First—let’s define our terms.
What are Data Apps?
We define a data app as: any app built on top of your data warehouse instead of a transactional database.
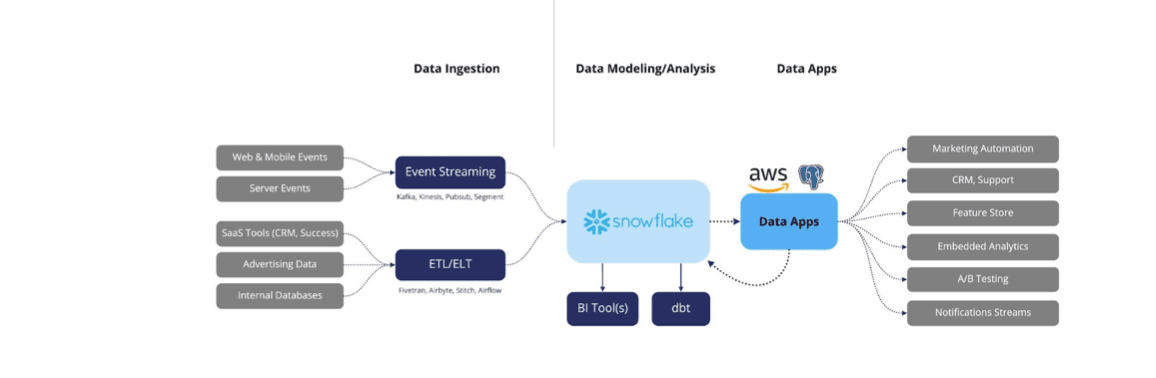
This means your data warehouse becomes the app’s primary data store or persistence layer. For example, if you’re building a customer success dashboard to display app usage metrics of a given workspace, you can build it directly on top of your data warehouse, giving your dashboard access to all of the data in your company and making the dashboard easier to customize because you own the schema. Given the right toolkit, you can get up and running quickly without complex technical integrations, making it accessible for non-technical teams, and you could imagine your existing data assets powering the underlying logic for the app, enabling marketers to act on insights without waiting for engineering support. The underlying models could even power simple parts of the frontend like table-views, but the rest of the frontend will be custom to the app.
Data App Common Characteristics
There are two characteristics that most data apps share:
1. Caching layers
It is common for data apps to have a caching layer that can help with real-time reads, and that cache should be a reflection of the warehouse. This means you can replicate small parts of your data warehouse into a caching layer, and then make a production application on top of that caching layer. That way, you can get the benefits of a transactional database with quick look-ups and read capabilities without having to worry about a replica that diverges from the data warehouse.
2. Any server can serve the app
With data apps, it doesn’t matter where the server that serves the UI on the frontend sits—it can be on or off the warehouse, or on-prem—because what you really care about is the persistence data store being the data warehouse.
Advantages of Data Apps
Data apps provide two primary advantages:
1. Single source of truth
As previously touched on, with data apps, you have total control over your application data because you can turn your data warehouse into your single source of truth and draw data from it as needed. You no longer have to create replicas of your warehouse data across transactional databases, eliminating data silos.
2. Accelerated development
Data apps empower marketing teams to quickly build and deploy customer-facing experiences directly from their existing data, without requiring engineering resources. As an example, if your organization already has data centralized in a warehouse, you can quickly stand up new data apps without complex technical overhead, accelerating time-to-value for marketing initiatives. Since all of your business logic resides in the warehouse, there’s no need to perform API calls on different tables and spend time creating “joins.”
Disadvantages of Data Apps
There are actually quite a few disadvantages to data apps, which is why you still don’t see them in practice too often today.
1. Transaction processing
Data warehouses don’t tend to support transaction processing (although Snowflake does), which means it’s hard to enforce consistency. If you have two different operations happening, you can't necessarily guarantee that both operations will succeed. An example could be transferring money from one bank account to another. The problem is if only one of these operations succeeds then one account will have too little money and the other too much.
2. Difficulty with writes
There’s a bit of debate around whether data apps should have the ability to write to the warehouse, or whether they should be read-only, or both. This exposes a pretty big flaw in data apps—writes, which could take an hour or more to materialize downstream into the affected metrics. Since warehouses are not transactional, a second user might wait an hour before they see the same data on their screen, or the same user may even refresh and no longer see consistent data because the write has not yet affected the model being read.
3. Constraints
The second main issue is constraints. Because warehouses are columnar, you can’t do constraints. For example, if you wanted to do a foreign key on another table you can’t enforce that foreign key and also can’t enforce things like cascading deletes. You also can’t search by IDs with a data warehouse, which can make certain types of queries very impractical from a cost and speed perspective.
4. Query speed Caching layer solves this, but in the absence of a caching layer this would be a huge problem If you don’t use a caching layer then you’ll end up waiting around five minutes for your page to load.
Ultimately, the four disadvantages above leave two questions unanswered:
How do you reconcile the fact that updates need to be fast enough to reflect in the UI?
Most end users are accustomed to something like a 100-millisecond latency for them to click a button and see an action happen. However,in the data app world, that may not be possible, so use cases like order management and customer support are not well-supported by data apps today.
Which data warehouses are fast enough to support data apps, if any?
Certainly, Materialize and Firebolt are promising here, but it’s TBD. With caching, it may not make a significant difference between different warehouses
Data App Examples
Here are a few examples of data apps from the ever-growing data apps landscape.
1. Streamlit — Streamlit primarily helps you build UIs on top of your existing Snowflake data, to tackle analytics use cases. With just a couple of lines of python, you can turn your Snowflake instance into a database that you can run applications on.
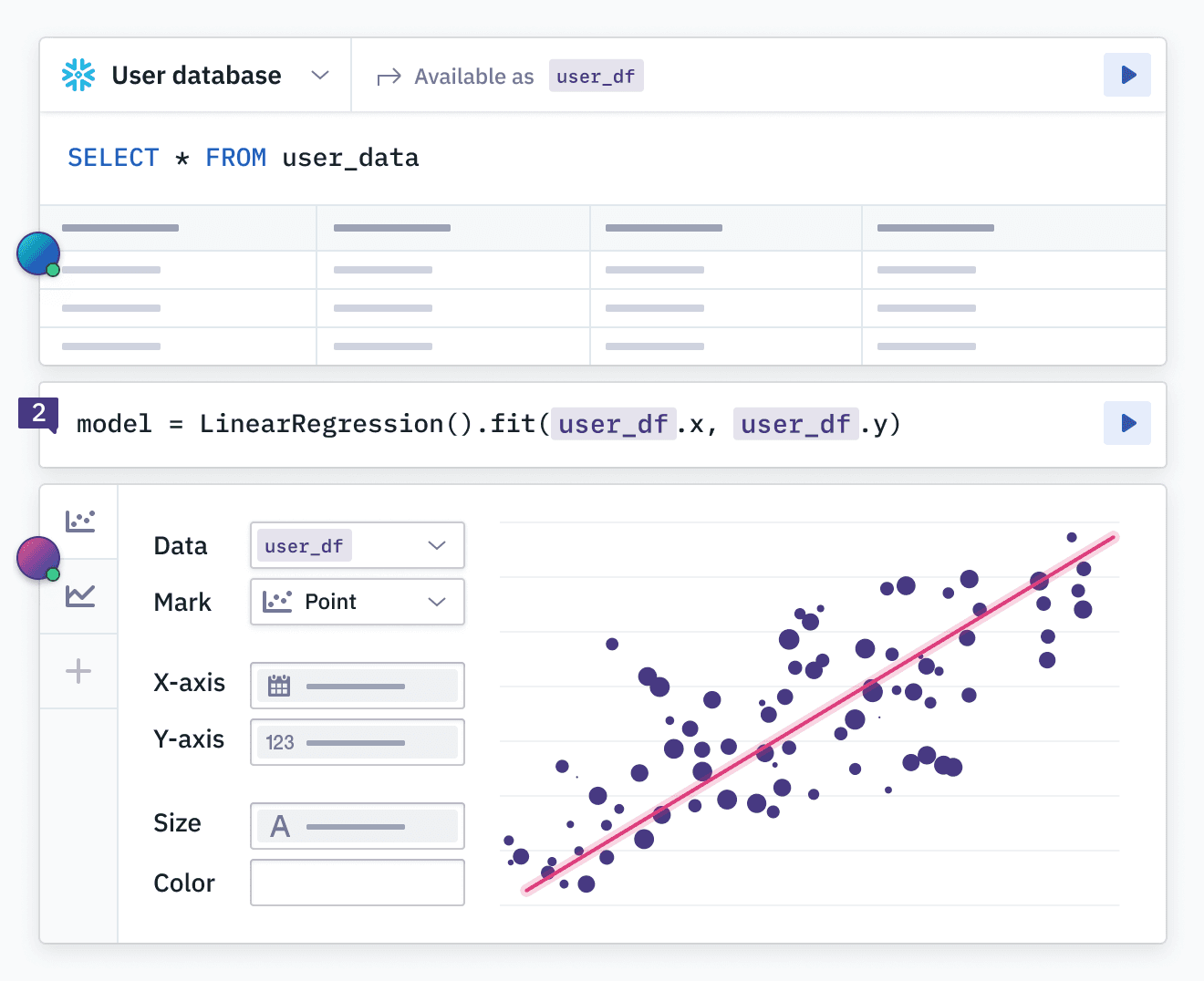
2. Hex — Hex is building data science notebooks on top of the data warehouse. Depending on the data warehouse, Hex lets you run both code and SQL on top of your warehouse, enabling you to run any type of analysis you want. You can even run only the parts of the computation that are relevant to changes that you make.
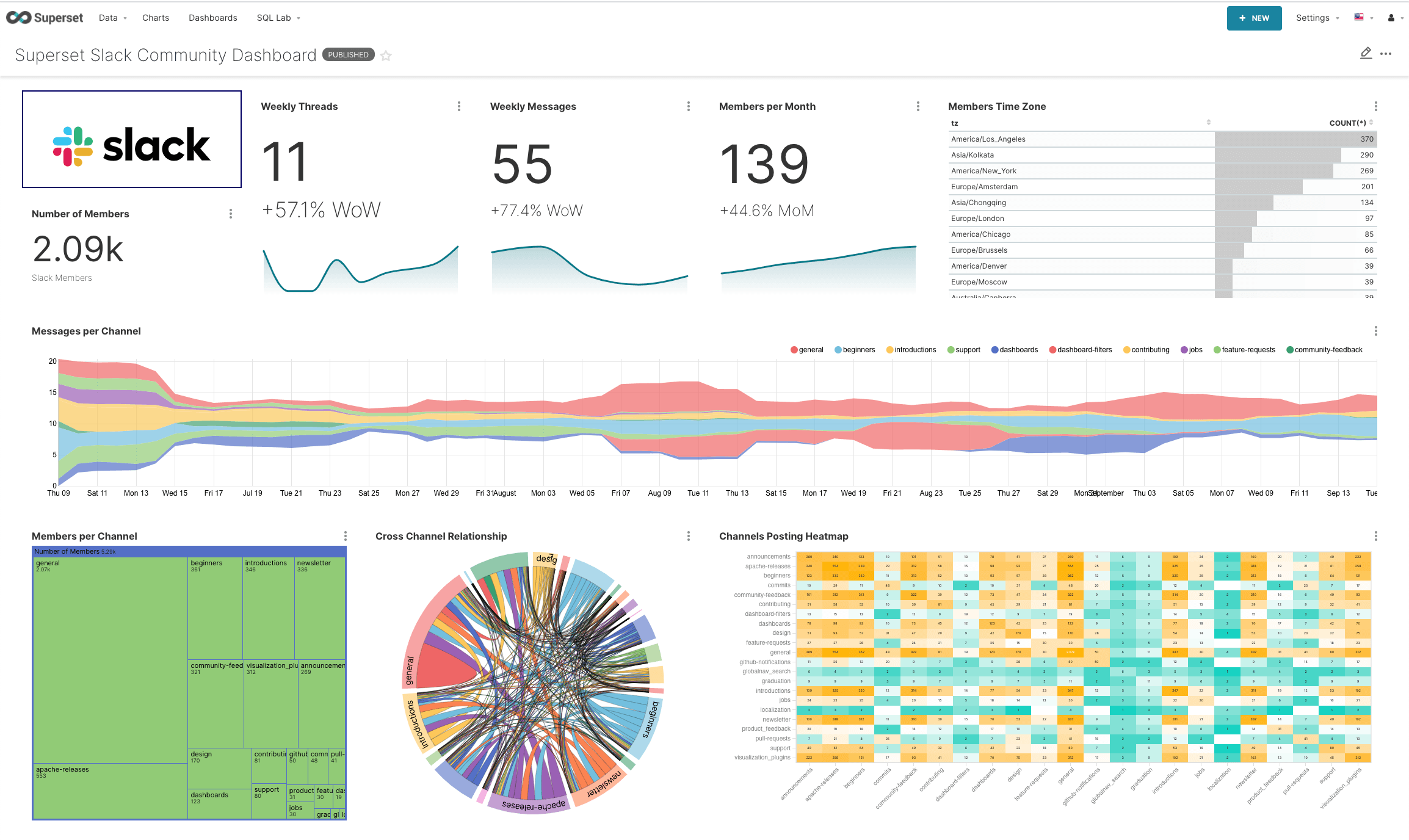
3. Preset — Preset is the cloud version of Apache Superset that can be used for embedded analytics. For example, each user of a SaaS application needs a custom dashboard where they can play with their usage data. They want this dashboard to be interactive, rather than static so that they can run different types of analysis on their usage data, but all of the data lives in that SaaS platform’s data warehouse. Preset provides a white-labeled embedded dashboard that exposes only the data relevant to that specific customer.
4. Retool — You can basically build anything you want in Retool and then read from the data warehouse. There’s no write layer—you would need to use a RestAPI to write anything back—but you can build CRMs and customer support apps out of Retool. You can use it to build essentially anything on top of the data warehouse and it will let you write JavaScript or SQL on top of the data. If you have any internal tools you need to build and you already have a Snowflake or a PostgreSQL working, Retool can do that for you in about 10 minutes, which is very exciting from a data apps perspective.
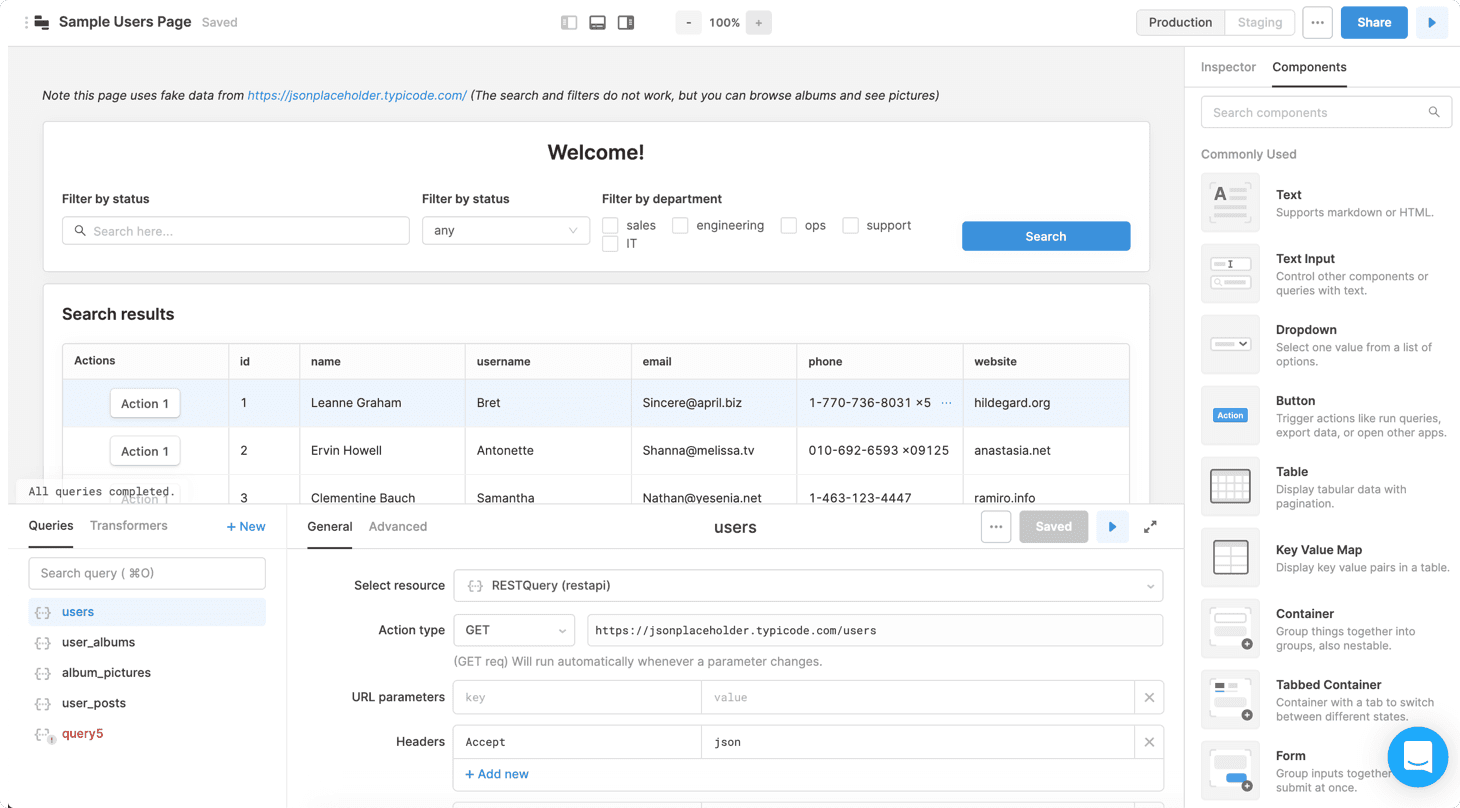
5. Looker and Mode — This could be the most contentious one because it’s questionable if we can count BI tools as data apps. Looker does pull from your data warehouse and doesn’t have a data store. It does provide dashboards that business users can look at and filter on to see important information. So these BI tools, by our loose definition, qualify as data apps.
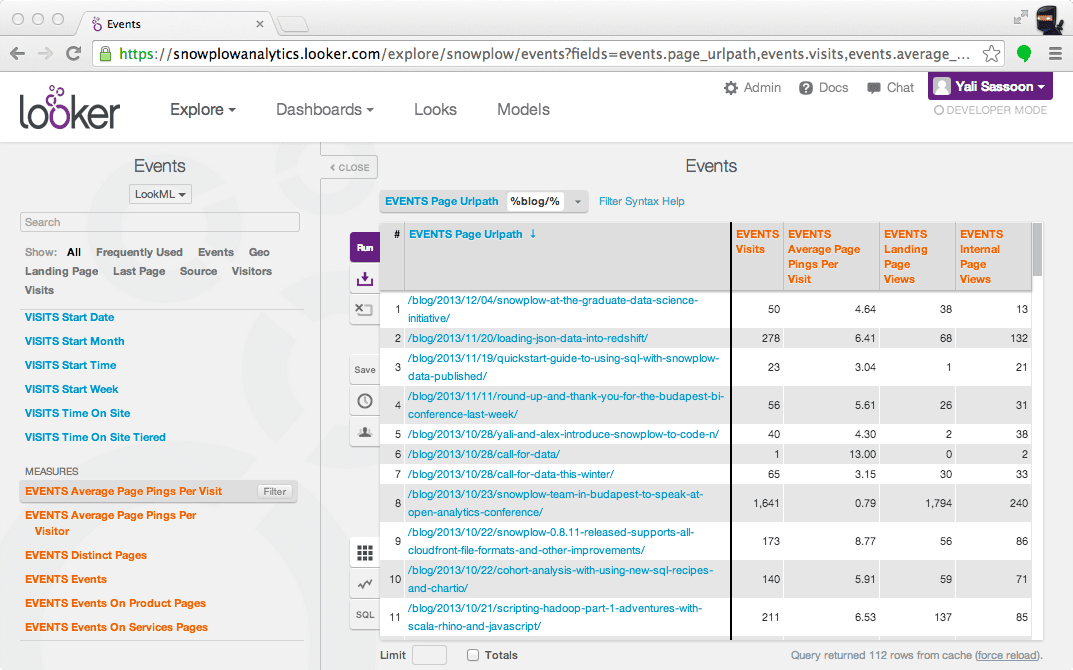
6. Pocus — Product-led growth (PLG) CRMs are basically the new-age Salesforce. They help you, as a company, identify which product users are most likely to buy or convert. The interesting thing here is that in order to do this, you ETL your warehouse into a Postgres and then from there it goes into the Pocus app. So Pocus is actually warehouse-native with a Postgres caching layer. With Pocus, your sales users can define a PQL or metric without having to go to your data team every single time.
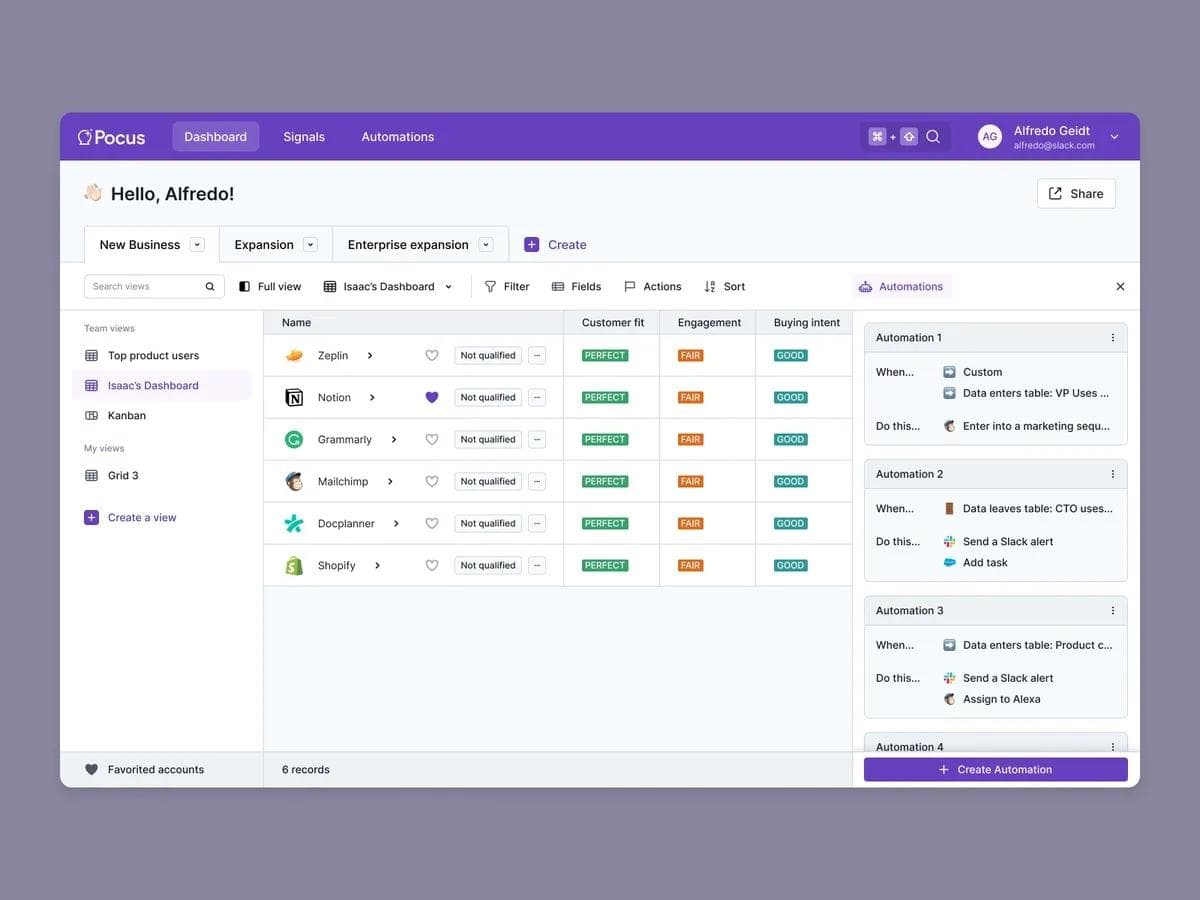
7. Indicative — Indicative is truly warehouse-native as well. Instead of having to send all your data to a product analytics tool for storage and then into a dashboard, you simply plug-and-play it into your warehouse, bring your own schema, and it will work for both events data and objects data.
8. Panther — Panther is security on the data warehouse and it also works out of the box. We see Panther as a best-in-class for security that is controlled by the data warehouse.
9. Eppo — Eppo is a new tool for experimentation on the warehouse. The idea here is that Eppo can help determine which users are in which test class, write that information to the warehouse, and also write the results of the experiments to the warehouse. It makes sense to be data native because oftentimes the results of the experiment will be needed for downstream data science.
10. Explo and Hyperquery — These are notebooks or documents on your warehouse. You can write both SQL or code and you can turn that into dashboards. You can build dashboards that automatically update by pulling in data from the warehouse. They are often customer or user-facing, which is what distinguishes this category from Hex and puts it closer to Preset.
All of the above data apps allow you to build on top of the warehouse, which means directly building on top of the models created by your data team. Data apps should provide faster time to value and it should be easier to transform their underlying data.
The Future of Data Apps
It’s exciting to think about what hasn’t yet been done with data apps. Vendors are helping us use the data warehouse in new ways, and that’s a good starting point. But internally, in our own companies, we can actually build data apps sooner in a more custom way.
CRMs
Some companies have homegrown CRMs because traditional CRMs don’t fit their needs. Over time, we could see in-house CRMs being built on the data warehouse in replacement of Salesforce. The customer data is already in the data warehouse, so the CRM would really just be a visual layer to expose that data and allow sales users to take action on the data. Some actions, such as changing the opportunity stage or issuing a refund, would require a database operation, while others would require an API call to an internal system. The benefit of building an in-house CRM on the warehouse is that it would support any object schema, rather than being prescriptive with objects such as Contact and Account.
Feature Flags
ML model features are commonly computed and then stored in a data warehouse. The same goes for feature flags. Normally, you would ETL your data from a data warehouse into an in-memory database such as MemSQL or a SaaS product such as LaunchDarkly to serve the feature flag. The product team would use that database/SaaS tool to power a production application (e.g., letting the iOS app know what percent coupon to give a certain user, or letting the iOS app know which product recommendations are relevant to a certain user).
This is where a data app could come in handy because it would replace the need for maintaining data between the data warehouse and MemSQL/LaunchDarkly. Instead, the data app could update a cache every hour and serve an in-memory database itself as a REST API to the product team. The feature flags would be available in real-time but refreshed every hour. An added benefit is that your data team would own the feature flags without relying on your engineering team to help make them available to the product.
Should I Build Data Apps?
The reality is that you likely already have data apps at your company because any consumer of your warehouse is probably building some sort of data app; they just may not be calling them data apps yet because the term is not yet industry standard.
Not everyone needs to start building data apps tomorrow, but if you have a good use case for them, such as enrichment, then you may want to.
The Verdict on Data Apps: Fad or Trend?
Even when data apps do become mainstream, they will not replace all internal tools. Especially at most companies, SaaS vendors and legacy tooling will still exist for a majority of use cases. At best, data apps may replace a small subset of use cases in the near to moderate future.
For things like embedded analytics (because it’s okay if those analytics compute every hour) data apps seem to make a lot of sense. They’re practical for read-only use cases, too, but for write use cases, using data apps gets very complicated.
In the meantime, Reverse ETL can help get data from your data warehouse into your SaaS applications. It may not always be practical or efficient to build applications on the warehouse, when SaaS tools already exist with widespread adoption for those use cases. Reverse ETL will still help turn those SaaS tools into a reflection of the data in your data warehouse.
Data apps are neither fad nor trend—yet. But very soon, data apps will likely be a new trend and not just a flash in the pan.
Our Data Apps: Hightouch Audiences, Traits, and Notifications
As you may already know, Reverse ETL uses a SQL query to replicate data from the warehouse into other applications such as Salesforce. But Hightouch Audiences instead provides a point-and-click UI where users can define customer subsets in plain English. This interface is entirely based on data from the warehouse, and allows marketers to segment their customers and run campaigns on those customer subsets.
Instead of having to write a query as, “all users left joined with the orders table where order placed in last 30 days,” you can instead use point and click in plain English—“users that placed an order in the last 30 days”—and Hightouch Audiences will compile that down to SQL for you.
Hightouch Audiences essentially opens up the data warehouse floodgates to users that might need to access that data to run campaigns. And that was just the ads use case. You can also use it for emails, push notifications, TikTok ads, text messages—pretty much anything that a marketing team might want to do, you can power using Hightouch Audiences. We call Hightouch Audiences a data app because it exposes the data warehouse via a point-and-click UI where you define your user specifications and lets you run campaigns on the data.
Hightouch Notify is another example of a data app, where you can create a notification stream off of the warehouse. You could, for example, get a Slack feed of all users that sign up. You could also get a Slack feed for all user workspaces that grow beyond 10 users and automatically trigger alerts to account executives telling them to sign these accounts up for the business plan.

















