
Moving data to and from various data systems is extremely difficult. Every data system has its own unique schema structure to designate how your data is organized and stored across objects and tables, and a unique API to control precisely how you can send and receive data. Unfortunately, most APIs and schemas are designed solely to address the use cases predicted by the provider, which makes building and maintaining data pipelines quite challenging.
What is Data Mapping?
Data mapping is the process of taking specific fields from a data source and syncing that data to related fields in your target database. Data mapping helps eliminate the complexity of having multiple different schemas across data systems, so you can focus on replicating the same data from your source to your destination.
How Does Data Mapping Work?
To understand how the data mapping process works, you first must understand the data integration landscape. Data integration refers to moving data to and from various systems. It's a process for combining data from different sources into a single unified view.
These data sources can include anything from SaaS tools, CSV files, databases, data warehouses, etc. In either case, data can originate or be stored in many different tools. Data integration enables you to merge different datasets together and consolidate your data into the tool of your choice.
At its core, data mapping is a data integration challenge, and data integration can essentially be broken into three core pillars: extract, transform, and load. Data engineers defined the ETL process to denote that you're moving data from one location to another.
- Extraction focuses on collecting and aggregating data from your source.
- Transformation is the process of standardizing, validating, and restructuring your data into relevant data models suitable for analytical processes.
- Loading focuses on ingesting your data into your desired destination (e.g., your production environment.)
The data mapping process takes place in the ingestion phase, and it's necessary because every system has a slightly different way it organizes and structures data.
For example, your data warehouse might have a users table with fields like ID, First_Name, Last_Name, and Email. On the other hand, your CRM might have a similar object, but the overall structure for these fields might differ slightly (e.g., Customer_ID, Customer_First_Name, Customer_Last_Name, Customer_Email, etc.) A data map will usually end up looking something like this:
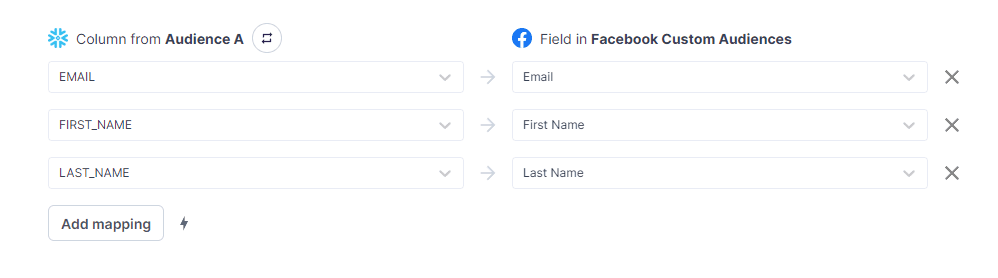
Data Mapping Example in Hightouch
This is just one example; you also have to account for variables like schemas, primary keys, foreign keys, data hierarchy, and a whole litany of other challenges related to data types like XML, JSON, flat files, etc. In addition to this, the size of your datasets and the number the different systems can quickly add to this complexity. Data mapping isn't the most straightforward process and becomes even more challenging when you tack on third-party APIs.
Data Mapping Use Cases
Generally, there are two use cases for complex data mapping projects: Analytics and Data Activation.
Analytics
With analytics, you're focused on consolidating your data into a centralized data platform (e.g., Snowflake or BigQuery) so you can use that data to drive high-level business decisions. For most companies, data is often siloed across multiple disparate data sources. Building ETL pipelines to push all of this data into a warehouse eliminates these fragmented data siloes and ensures all of your data is in one place.
Data Activation
Data Activation sits on the opposite side of the spectrum when you compare it to a typical analytics use case. Rather than focusing on loading data into a single platform, Data Activation is all about making your analytics data available in your operational tools so you can leverage it to build personalized experiences for your end customers.
What’s the Difference Between Analytics and Activation?
The main difference between Analytics and Data Activation comes down to the sources and the destinations. With Analytics, all your data is being ingested into a centralized data platform, meaning you're writing to a single API. With Data Activation, your sending data to multiple destinations, and this means you're writing to multiple different APIs. This may seem like a small difference, but writing to an API is always harder than reading from it.
Using ETL to push data to your warehouse will always be easier because you have complete control over how you structure your databases and tables. Unfortunately, this is not possible when syncing data to your operational tools. For an analytics use case, you define precisely how and where your data should be structured in your warehouse. For Data Activation use cases, you're at the mercy of your SaaS provider.
Data Mapping Processes
Data mapping has three central processes: manual, semi-automated, and automated. All of these options still use conventional ETL processes.
Manual Data Mapping
Manual data mapping forces your data team to build connections from your data source to a target destination (this destination is usually a database or CSV document.) This means they have to write complex code. The advantage of this approach is that it gives you the ability to fully control and customize your data map for your specific use cases. However, the double-edged sword to this approach is that it's incredibly time-consuming to build and maintain bespoke solutions. A single change to a systems API or schema can break your entire data pipeline.
Semi-Automated Data Mapping
With semi-automated data mapping, you can take advantage of an existing integration platform that allows you to use software to map schemas together with little intervention. The software compares your data sources to your target schemas to generate a connection. Once you've established this connection, your data team can check and optimize the data map as needed. The upside of this approach is that you don't have to build and maintain integrations. The downside is that these tools can often have a steep learning curve, and they usually require a substantial amount of code to create your desired outcome.
Automated Data Mapping
With automated data mapping, you're taking advantage of a fully managed SaaS tool that handles the entire process for you. This approach provides a significant advantage over the previous two options because your data team only needs to know how your source and destination work. They don't have to account for everything that happens between the two. With automated data mapping, you leverage a simple drag-and-drop UI and point your data toward your end destination and run your sync. All of the complexity is removed and taken on by your SaaS provider. Very little training is required for automated data mapping, which translates into fewer errors.
Types of Data Mapping Tools
Every major cloud vendor has a data mapping tool that provides a graphical interface to define your mapping rules. However, many technology companies have sprung up to tackle the challenge of data integration, and several categories of data mapping tools have risen up. Ultimately, each of these categories takes a slightly different approach when it comes to ETL, but all of them tackle data integration and data mapping in their own unique way. All data mapping tools essentially work the same way. The difference lies in the use cases they address and their overall architectural approach.
Open-Source Data Mapping Tools
Open-source data mapping tools are categorized by their publicly available code base. Anyone can inspect, modify, and ship changes to the code controlling these tools. The premise behind open-source platforms is to foster a community of users that can support one another by building and maintaining their own unique connectors or data mapping tools. One of the significant advantages of open-source data mapping tools is that they give you direct access to code errors so you can correct them immediately, rather than waiting on a support ticket with a third-party vendor. Every open-source platform in the data mapping space is focused on helping consolidate all of your data into a warehouse.
On-Premise Data Mapping Tools
On-premise data mapping tools have been around for the longest. They're primarily used for conventional analytics and ETL use cases (e.g., loading data into your warehouse.) With an on-premise data mapping tool, all resources are deployed and managed in-house within your infrastructure. The downside to this approach is that anytime you need to scale up, you're forced to provision more hardware. On the flip side, you can pay all your software costs upfront instead of at a monthly subscription fee.
The primary users of on-premise data mapping tools usually tend to be organizations with highly sensitive data (e.g., healthcare/government.) With an on-premise ETL tool, you're in complete control of every aspect of your data pipeline, from the point your data is extracted, to the point your data is loaded into a staging area, to the point where it's transformed. This process is relatively rigid to ETL, and it takes substantial work to switch to an ELT approach.
Cloud-Based Data Mapping Tools
Cloud-based data mapping tools have skyrocketed in popularity as companies have realized that it no longer makes sense to spend countless hours building and maintaining data pipelines. These data mapping tools offer out-of-the-box connectors/integrations to hundreds of data sources and the most popular data platforms. One crucial factor to note about these solutions is that they solely focus on taking data from your source and loading it into your analytics platform (e.g., your data warehouse.)
These platforms are the easiest to use when it comes to conventional analytics use cases and consolidating all of your data into a centralized location. You don't have to worry about anything aside from connecting to your source and mapping your data to the appropriate tables and fields in your warehouse. Since cloud-based data mapping tools run parallel to your data warehouse, they often follow an ELT approach, allowing you to transform your data directly in your warehouse. This approach offers a twofold benefit because you no longer have to predict your use cases when transforming and modeling your data, and you can speed up your ingestion process by loading it immediately.
Reverse ETL
Reverse ETL is a cloud-based data mapping tool. However, rather than focus on the conventional ETL aspect of moving data from your source to your warehouse, Reverse ETL focuses specifically on Data Activation (e.g., taking the transformed data from your warehouse and syncing back to your operational tools to optimize your business processes.) Since Reverse ETL tools query against your warehouse, they don't store any data. Once you've connected to your data warehouse, you can leverage your existing tables and models and make that data readily available in any destination you choose. All you have to do is define your data mappings.
Customer Data Platforms (CDPs)
CDPs also focus on Data Activation, but they operate as a separate entity in your tech stack, providing a standardized API that can integrate with your various downstream applications and business tools. In almost every case, you'll need to find a way to copy the data in your warehouse to your CDP before you can actually take advantage of these platforms, which means you inevitably end up paying for an additional storage layer.
The main advantage of CDPs is that they provide proprietary event-tracking software you can run on your websites/apps to capture behavioral data (e.g., page views, session length, signups, last login date, etc.) They also provide a visual interface to build and define audiences quickly. The downside to this approach is that CDPs have rigid requirements for transforming and modeling your data, with the only two objects you can leverage often being users and accounts.
Integration Platform as a Service (iPaaS)
IPaaS platforms allow you to establish point-to-point connections with the various tools in your technology stack. Often this comes in the form of syncing data from Hubspot to Salesforce or vice versa. iPaaS tools make it relatively easy to establish these connections so you can move data between systems with relative ease. Most tools in this category offer a no-code visual interface where you can build workflows based on if/then statements and various dependencies you define.
The key factor to understand is that iPaaS tools can't send data unless a trigger is kicked off (e.g., when a new opportunity is created in Salesforce, create a contact record in Hubspot.) This can be a great approach if you have relatively simple use cases and needs. Depending on the number of data sources in your technology stack, iPaaS tools quickly become unscalable, and workflows can become a nightmare to build and maintain.
What Are the Best Data Mapping Tools?
There are a wide variety of data integration tools, so it would be impossible to evaluate them properly. Here's a list of the most popular data mapping software.
- Open-Souce: Airbyte is the largest fully open-source ETL tool that offers hundreds of connectors to various data sources. The significant advantage of Airbyte is that you can use the company's custom developer kit to build new connectors or even edit existing connectors to best fit your use case. Airbyte is pretty much solely used to move data from your source to your warehouse.
- On-Premise: Informatica is probably the most well-known data integration provider. The company offers a suite of products to tackle any data integration use case but it’s more commonly known in the on-premise world. The company has over 400 unique connectors to various on-premise sources and SaaS applications as well as data warehouses. Informatica is synonymous with conventional ETL use cases where you’re focused on centralizing and consolidating your data for analytics.
- Cloud-Based: Fivetran is a SaaS platform that provides over 100 fully managed connectors and focuses on extracting and loading data directly from your source to your warehouse. Fivetran automatically normalizes, cleans, sorts, and de-duplicates all your data optimally for your specific destination. All Fivetran pipelines are prebuilt and preconfigured to handle your needs automatically, and you can automatically schedule and orchestrate all of your pipelines.
- Reverse ETL: Hightouch is a Data Activation platform that runs directly on your warehouse and allows you to sync data to over 100 destinations. With Hightouch, you can leverage all the existing tables and data models in your warehouse and easily map data to the appropriate fields in your end destination. There's even a visual audience builder for non-technical users. Best of all, the first integration with Hightouch is free.
- iPaaS: Workato is a SaaS platform that allows you to build point-to-point integrations between your various SaaS tools to move data back and forth between platforms. Workato offers over a thousand connectors to various on-premise and cloud apps. The platform specializes in helping you automate menial tasks and workflows (e.g., notifying sales reps in Slack every time a lead is added to Salesforce.)
- CDPs: Segment is a CDP that integrates with over 300 different tools and SaaS applications, but the platform is more commonly known for its event collection and audience management capabilities. Segment CDP provides proprietary code that you can run on your website/app to capture behavioral data on your customers. This data is then tied to a user or account profile so you can create customized audience cohorts that you can send to your downstream systems.
Benefits of Data Mapping Tools
Dedicated data mapping tools offer several advantages and key features compared to traditional in-house approaches.
- Visual interfaces: Almost all data mapping tools provide visual UIs, making it easy for non-technical users to carry out data mapping tasks between objects, fields, and tables.
- Automation: Dedicated data mapping tools allow you to automate and schedule your ETL jobs consistently.
- Maintenance: You don't have to worry about all of the underlying maintenance involved with building and maintaining individual pipelines.
- Scalability: Since all data mapping tools typically come with prebuilt connectors, you can quickly scale your ETL jobs as needed at a moment's notice.
- Low-Code: Almost every data mapping tool uses SQL or a visual interface which means you never have to write complex code to move data.
- Error Handling: Data mapping tools make it much easier to do debugging and manage errors; whether it's related to data types, schema changes, API updates, etc., you can see exactly when and where something went wrong in your pipeline.
Final Thoughts
Ultimately, no single data mapping tool is going to solve all of your problems. You'll inevitably need a data mapping tool to get data into your warehouse and another tool to get data out of your warehouse. Every SaaS application has a unique API and every data warehouse has a single standard API, so reading from a source and writing to your data warehouse will always be much easier than reading from your warehouse and writing to a business application.

















