
We recently took another pass at saving on Snowflake compute costs, and once again were surprised by how much we found. This time we took a more targeted approach, focusing on a particular dbt workload.
We looked into 1 warehouse that supports some of our dbt Cloud jobs, and were looking for the following:
- Could this warehouse be bigger than it needs to be?
- How is the total duration of these jobs trending over time?
- Are there any long-running models that are bottlenecking our DAG, and can we optimize these or re-evaluate their materialization method?
1st Observation and Action:
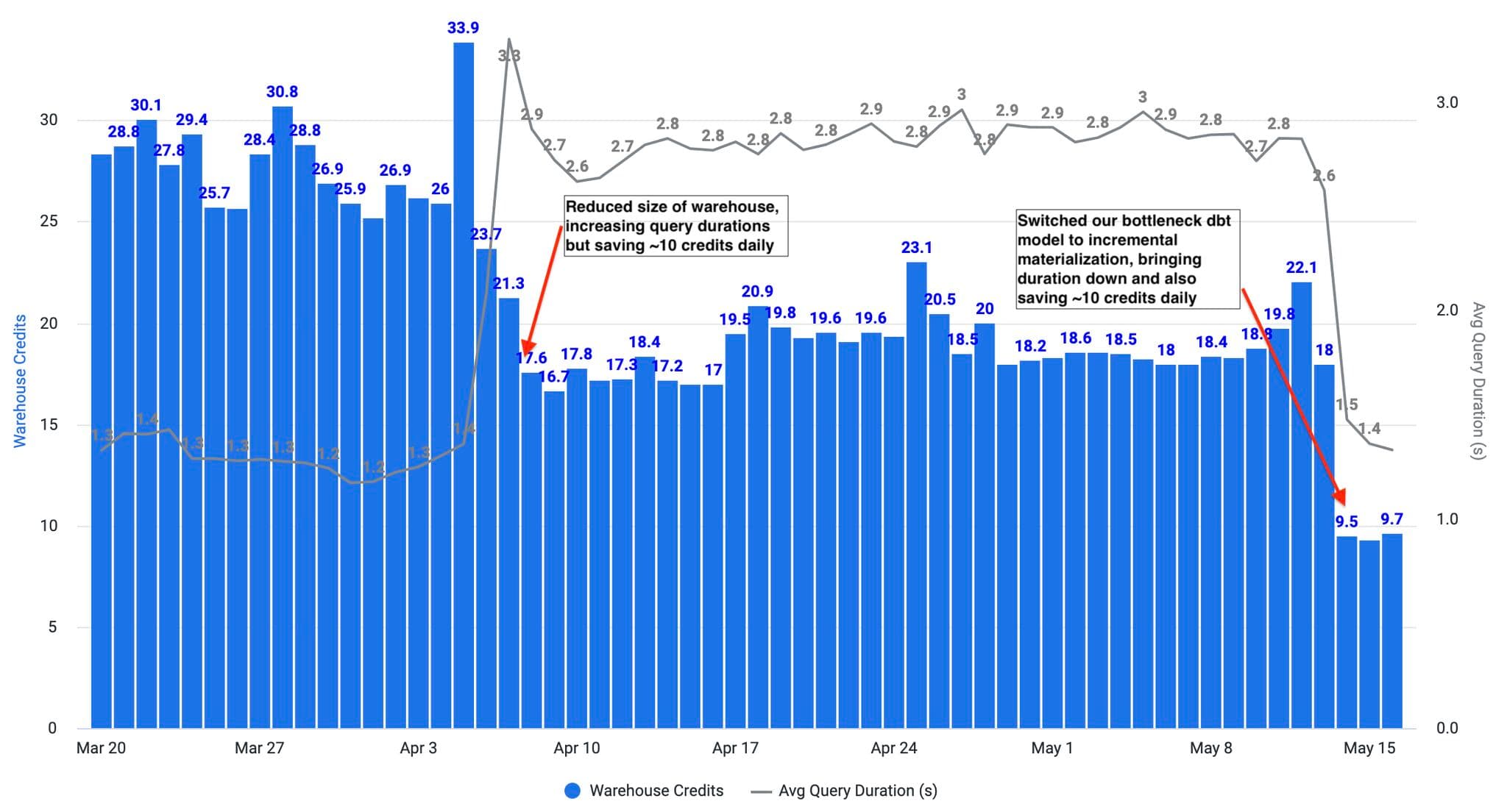
Our first observation was that this warehouse was indeed oversized. It was not overwhelmed by the workloads assigned to it, wasn’t queueing queries, and didn’t need to avoid queuing. It’s easy to look for this in Snowflake’s UI and with the account usage metadata they provide to all customers. Action: We reduced the size of the warehouse from Medium to Small in April, and while we saw our job durations jump because of this, we also saw total credit consumption reduced dramatically.
2nd Observation and Action:
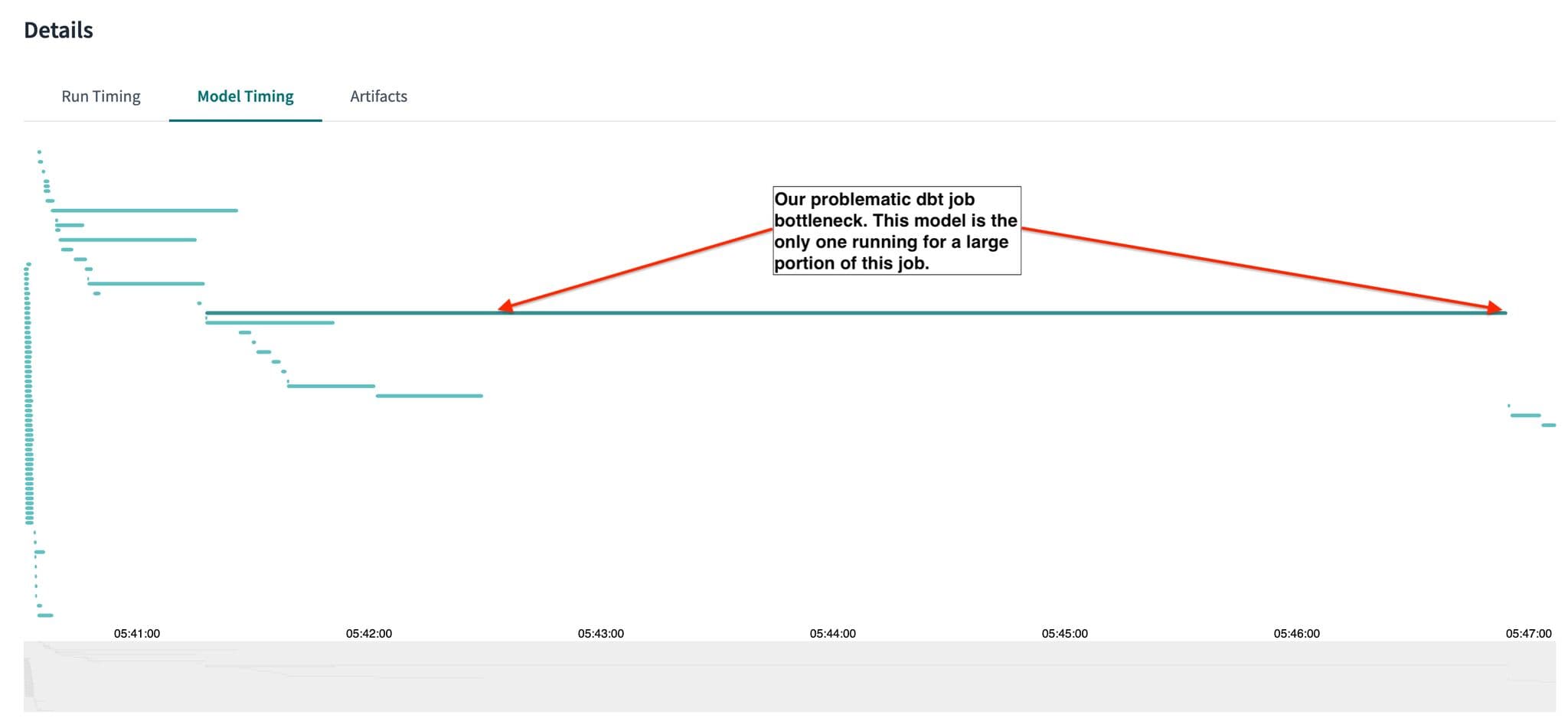
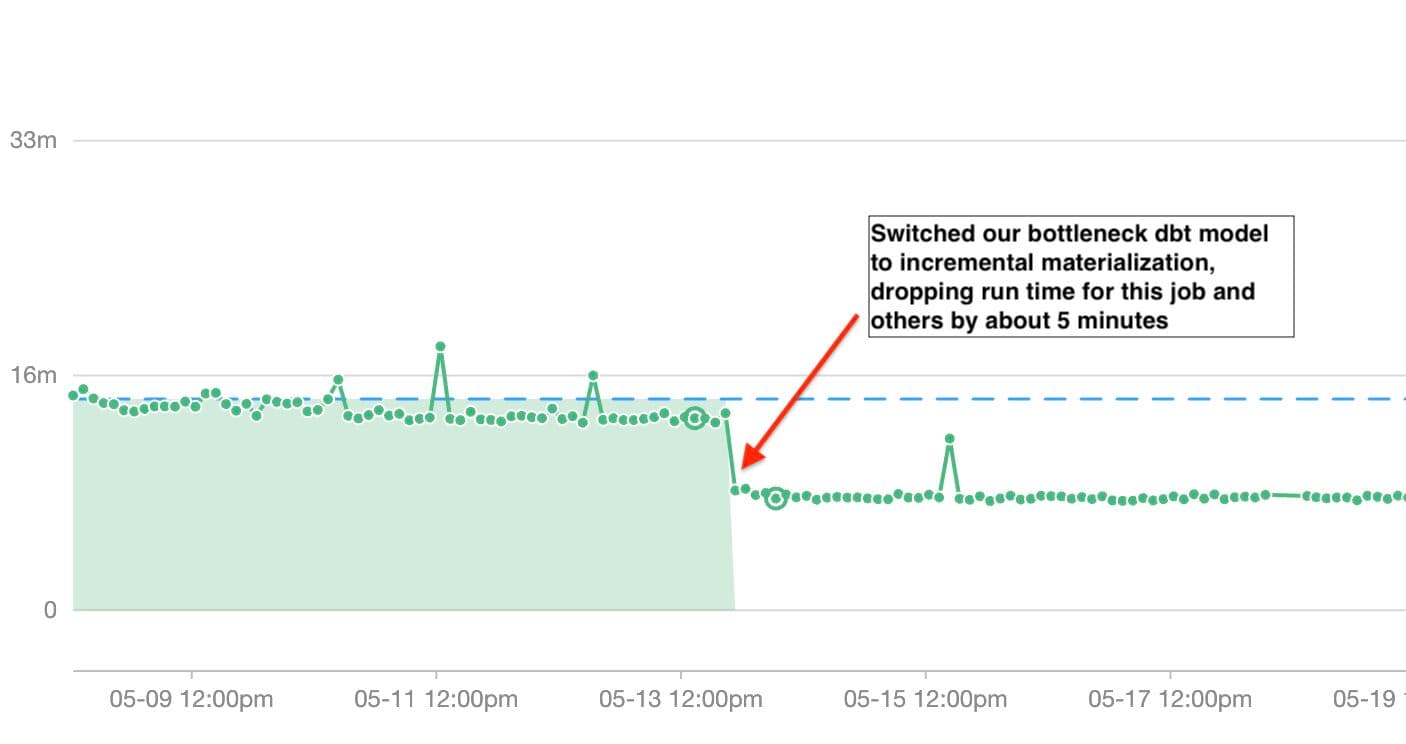
Our second observation was that our jobs being run on this warehouse were being bottlenecked by 1 model in particular. Bottlenecking happens when a model is holding the job up instead of running in parallel with other models. Action: We decided to see what we could do to optimize this model and quickly found that we could leverage incremental materialization to reduce its normal run time by about 5 minutes or ~91%.
Results:
- The result of our first action (reducing the warehouse size) was that this warehouse consumed at least 10 fewer credits per day than before.
- The result of our second action (using incremental materialization for the bottleneck dbt model) also happened to reduce our consumption by about 10+ credits daily because this model was run very frequently.
- Altogether, these 2 simple actions created 4-figure dollar savings monthly, and 5-figure dollar savings annually 📊
We’ve attached images showing 1) the impact of these two changes on credit consumption and average query duration 2) the DAG bottleneck in one job and 3) the drop in run time for that job from the incremental materialization.
Big thanks to Kevin Hu and the Metaplane team for making it trivial for us to monitor our dbt Cloud job run times (among many other things) Shout out to Niall Woodward of SELECT for your work on the dbt artifacts dbt package which can also be used to dig deeper into dbt artifacts more easily And of course thank you to dbt Labs and Snowflake for serving as core pillars of our data stack, powering everything from our dashboards and notebooks to our Hightouch syncs and beyond.

















