ETL vs. Reverse ETL: The Technical Differences
Discover the technical differences between Reverse ETL and ETL/ELT and learn how they work behind the scenes.

Zack Khan

Luke Kline

Kevin Lin
December 22, 2021
10 minutes
What is the difference between Reverse ETL and ETL/ELT? This is one of the most common questions we get asked here at Hightouch, so we thought we’d do our best to answer it and dive into some of the technical differences and discuss why Reverse ETL is different when compared to conventional ELT.
What is Reverse ETL?
From a high-level Reverse ETL looks very similar to ELT because they both move data from point “A” to point “B” automatically. However, whereas ELT reads data from SaaS tools and writes to the data warehouse, Reverse ETL reads from the data warehouse and writes to SaaS tools. Reading and writing are two completely different operations with their own unique technical quirks, which we’ll dive into.
You might be thinking: “Why would I want to move data out of the warehouse if I just spent so much effort getting it into the warehouse via ELT?”
Without Reverse ETL, your data warehouse is a data silo. All of the data within it is only accessible to your technical users who know how to write SQL. The data only exists in a dashboard or report used to analyze past behavior and not drive future actions. Your business users who are running your day-to-day operations across sales, marketing, support, etc. need access to this data in the tools they use on a daily basis (i.e. Hubspot, Salesforce, Braze, Marketo, Amplitude, etc.).
Technical Challenges of Building Reverse ETL
Reverse ETL comes with an assortment of technical problems that make it substantially more challenging to get right when compared to conventional ELT.
We’ll walk through each step of Reverse ETL, and the challenges associated with them. If you have tried to build an in-house Reverse ETL pipeline then you are probably all too familiar with these problems.

Step 1: Plan your sync with diffing and transformations
The first step to Reverse ETL is preparing the data you need to sync. We believe that Reverse ETL should follow two key principles at this step:
1. It should only sync changed data (diffs) to efficiently handle scale and syncing millions of rows of data.
2. The platform should handle last-mile transformations to provide a streamlined UX for business users.
Diffing for Faster Performance
Reverse ETL needs to diff changes between runs so that only changed data is synced.
With ELT, time is the only parameter to account for when diffing: you just need to merge in the latest data based on “updated_at” fields.
With Reverse ETL, you just have a list of rows you need to sync. There are no “updated_at” fields in your query. The only way to diff is to compare the values directly between your current warehouse query and what you’ve previously synced.
This adds an additional challenge when it comes to rows of data that failed to sync because you have to ensure that you don’t resync stale data. For example, if some rows fail during a previous sync, and then those rows get updated within your warehouse after that, you need to only sync those updated rows of data (ignoring the stale data from the previous sync).
Behind-The-Scenes Transformations for Different End-Users
The whole point of Reverse ETL is to democratize data out of the hands of just data engineers and into the tools of customer-facing teams. Because of this, we strongly believe that these business end-users should have a streamlined UX that handles all the edge cases that technical users would typically solve with SQL. Business users don’t have the luxury of transforming data on their own. That is why Reverse ETL tools should do behind-the-scenes transformations of data to make the UX for business users easier.
For example, certain ad networks require matching data to be hashed to protect customer privacy. Business users shouldn’t have to worry about that: Reverse ETL tools should consider the requirements of the end destination and transform the user’s data on their behalf.
Each destination has its own quirks and associated transformations required to provide a seamless UX for business users. All in all, Reverse ETL requires more transformations to be done behind the scenes for business users, whereas ELT solutions simply merge data into the warehouse.
Step 2: Step 2: Execute Your Sync and Write to APIs
Now that we’ve determined which changed data we want to send, we need to actually write to a destination using the provided APIs. For executing Reverse ETL syncs, we believe that:
1. The only limit to sync speed should be the performance of the destination. Your Reverse ETL tool should pipe data in as quickly as the destination will accept it.
2. The tool should play nicely with other writers to the destination (ex: other team members, SaaS applications, etc.).
API Performance and Speed
Since Reverse ETL is often powering workflows and marketing campaigns (like automating timely Slack messages), speed is of the utmost importance. In most cases, ELT tools like Fivetran or Stitch are only ever powering dashboards or reports, so it typically does not matter if this data arrives 2 hours late.
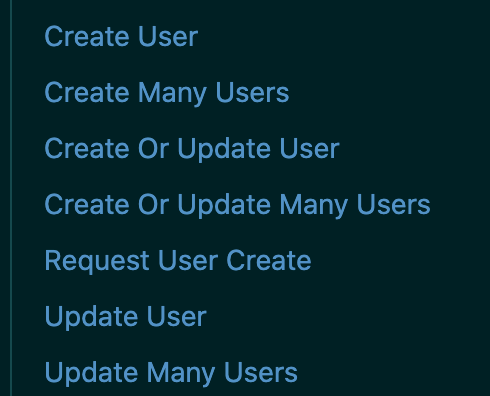
To maximize speed, you need to make use of batch APIs that are made to handle larger loads of data wherever possible, and respect rate limits. Doing this for a single object type of one destination is already difficult, but your tool must have the same rigor across all the different destinations and API endpoints. For example, Zendesk has 10 different endpoints for interacting with their Users object, so you need to make sure you are efficiently calling and respecting the rate limits set for each.
Example of Zendesk User endpoints
Every destination API has a slightly different interface, so recreating these pipelines is a manual and time-consuming process (especially since the average midsize company uses 130+ SaaS tools). There is always custom code required for each additional Reverse ETL integration because of this: the transformations required to send data to Slack are very different from the operations required for Salesforce.
For ELT, writing directly to a data warehouse is much simpler because warehouses are optimized for this exact purpose and built to store large amounts of data from multiple different sources.
To our previous point about transformations, there are many transformations needed to efficiently write to certain APIs efficiently, while still allowing business users to match data seamlessly. For example, to allow sales teams to match HubSpot Contacts based on any external field such as a phone number (not just HubSpot ID), you need to first make a bulk search by the external field, grab the HubSpot ID, and then use that HubSpot ID to write to the API.
You can learn more about the challenges of speed in Reverse ETL here.
Multiple Writers
Another challenge with Reverse ETL comes in the fact that you often have multiple tools and people writing to a destination like Salesforce. Fields are always updating or changing in Salesforce (ex: salespeople adding notes or other SaaS applications writing to Salesforce). With ELT, you only have one writer writing to a given table in a data warehouse (ex: Fivetran).
If you have ever used a tool like Salesforce or Hubspot, then you understand that there is no undo button for reversing field changes within the platform. Since ELT tools like Fivetran write to tables within the warehouse, you can blow away a table and simply resync that data to restore it.
On the other hand, Reverse ETL will override fields. This means that you have to worry about specifically defining which fields should be owned by Reverse ETL and which fields should be owned by people (manual entry) or other SaaS products. A great example of this is a lead source field in a CRM like Salesforce: do you want this field to be defined in your warehouse via Reverse ETL or by your Sales team?
Leading Reverse ETL tools allow you to specify certain update modes to handle this. For example, you can select an “Update” mode for only updating existing records and “Upsert” mode for both inserting new records and updating existing ones too.
Step 3: Maintain Your Syncs
Great, now we have our syncs sending data to our destinations. But that’s only half the challenge. Now that these syncs are powering customer experiences and internal workflows, we need to ensure they are reliable. For maintaining syncs we believe that:
1. Your Reverse ETL tool should provide maximum visibility, alerting, and observability. You should be able to see every operation and error received from destination APIs.
2. Reverse ETL syncs are as valuable as production code and need to be backed with git.
Visibility, Alerting & Observability
Visibility is another core problem for Reverse ETL because syncs can fail for multiple reasons. If your data is not properly formatted within your warehouse before syncing it to your destination, you will have trouble completing the sync. With Reverse ETL, the data has to be curated to match the format of the end destination for a sync to complete. On the flip side, if a sync fails using a tool like Fivetran to send data to your warehouse, you know it was likely due to a problem on Fivetran’s side since data warehouses accept all formats of data.
Developer Experience
Your Reverse ETL syncs are just as valuable as production code. In order to properly leverage Reverse ETL, you’ll likely want to back your syncs with version control (Git). Defining the format of the files that you version control and integrating with various Git providers can be a lot of work, but is crucial for the developer experience of Reverse ETL. On the other hand, ELT configs don’t change frequently because the schema is standardized.
Build vs Buy
Building a Reverse ETL pipeline internally to address these challenges would require an inordinate amount of effort from your data engineering team. To address the problems just listed, you would also need to manage and maintain each individual pipeline for every destination that you are looking to send data to. If you have multiple business teams, each with a different set of SaaS tools and operational systems, this likely is not scalable.
The Solution: Hightouch
As a cloud-native SaaS and Reverse ETL platform, Hightouch easily addresses all of the problems listed above.
API performance and speed: Hightouch is extremely fast. Currently, 90% of all syncs complete within 30 seconds, and 98% of all syncs complete within three minutes. With our custom integrations, you don’t have to worry about writing to various APIs because we handle all of this behind the scenes; you simply have to define the data you want to send. Hightouch also batches multiple rows of data in a single request so you never have to worry about rate limits or batch calls.
Diffing: Diffing is also handled automatically so you never have to worry about syncing bad data because we automatically diff the results between syncs to save you both time and money.
Visibility: Our live debugger logs changes to rows and provides all the info you need (such as responses from API requests) to help you identify and fix errors. We also send configurable alerts via Slack, Pagerduty and email when syncs fail so you can quickly get your syncs live again in no time.
Transformations & end-users: To simplify things for the user, we also do “last mile” transformations under the hood so you can match fields using custom objects. For example, if you want to match contacts to HubSpot using email, we would enable this by making a request for HubSpotID and then use that object to write so that it is faster and simpler for you.
Developer experience: We automatically back your syncs with Git.
Getting started
The first integration with Hightouch is completely free, so it's never been easier to dive in.