To set up identity resolution rules, you must first configure your input models and select the appropriate identifiers. Please review the information in the Model Configuration page before proceeding.
This page goes through the merge and limit rule configuration:
Merge rules
Merge rules instruct Hightouch how should it should try to find connections between records. For example, two users may have the same email, or two events may have the same anonymous_id.
You can build complex merge rules using the merge rule builder to nest and/or conditions.
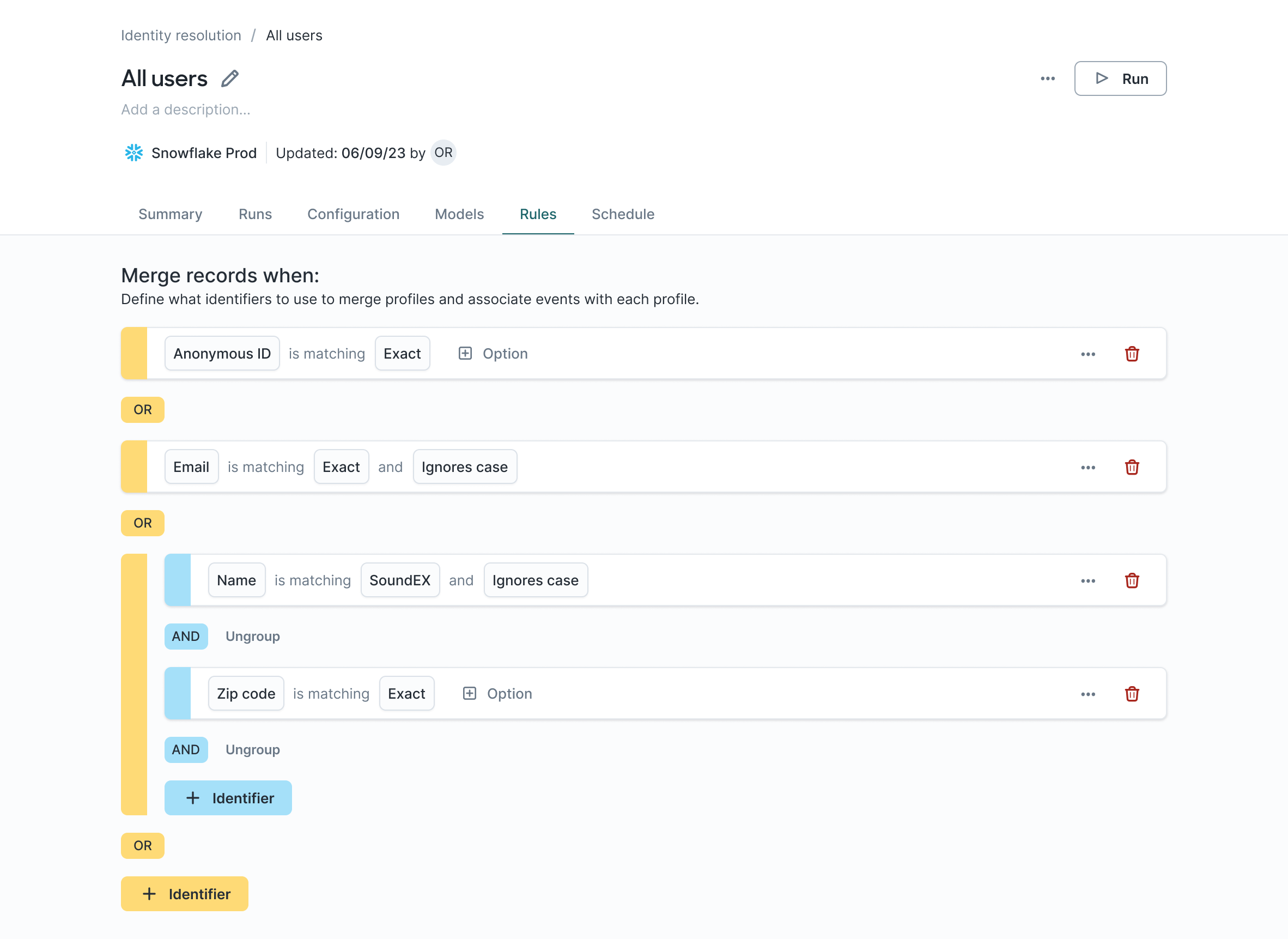
Hightouch fully supports exact comparison with up to roughly 1 billion input rows (total number of rows from input models).
🧪 Hightouch also has an experimental feature for fuzzy comparison that works with small input row sizes in Snowflake and Databricks. Please reach out to your account rep if you want to test fuzzy comparison.
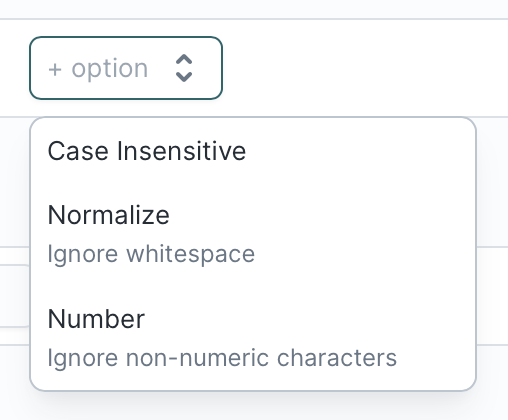
You can also use Hightouch's out-of-the-box transformations / data cleaning mechanisms to improve the likelihood of accurate matches:
- Case insensitive
- Normalize (convert multiple consecutive spaces to a single space and remove spaces from the beginning and end of strings)
- Number (ignore non-numeric characters)
Limit rules
Limit rules allow you to prevent merging records if they would violate some business rule that is important to your data.
For example, if you never want to merge two records if they have different user_id values, then you can specify a limit rule of 1 user_id per record.

Rule sets
Rule sets allow you to group and evaluate merge rules in sequence. This locks in the results of each rule set (assuming no limit rules are violated) before moving on to the next set to try and merge in additional records.
Example
Low confidence rules (e.g. match on first and last name) can merge different actual identities together and introduce limit rule violations.
Rule sets allow you to use these rules more confidently by running them after higher confidence rules (e.g. match on user ID) and undoing them if they merge records together that violate limit rules.
For example, imagine you have the following data:
| First Name | Last Name | Source | HT_ID | |
|---|---|---|---|---|
| john.doe@acme.com | John | Doe | Profile | |
| john.doe@acme.com | J | Doe | Event | |
| john.doe@dundermifflin.com | John | Doe | Profile | |
| john.doe@dundermifflin.com | Johnathan | Doe | Event | |
| barack@barackobama.com | Barack | Obama | Profile | |
| Barack | Obama | Event |
If you combine low and high confidence rules into a single rule set like this:
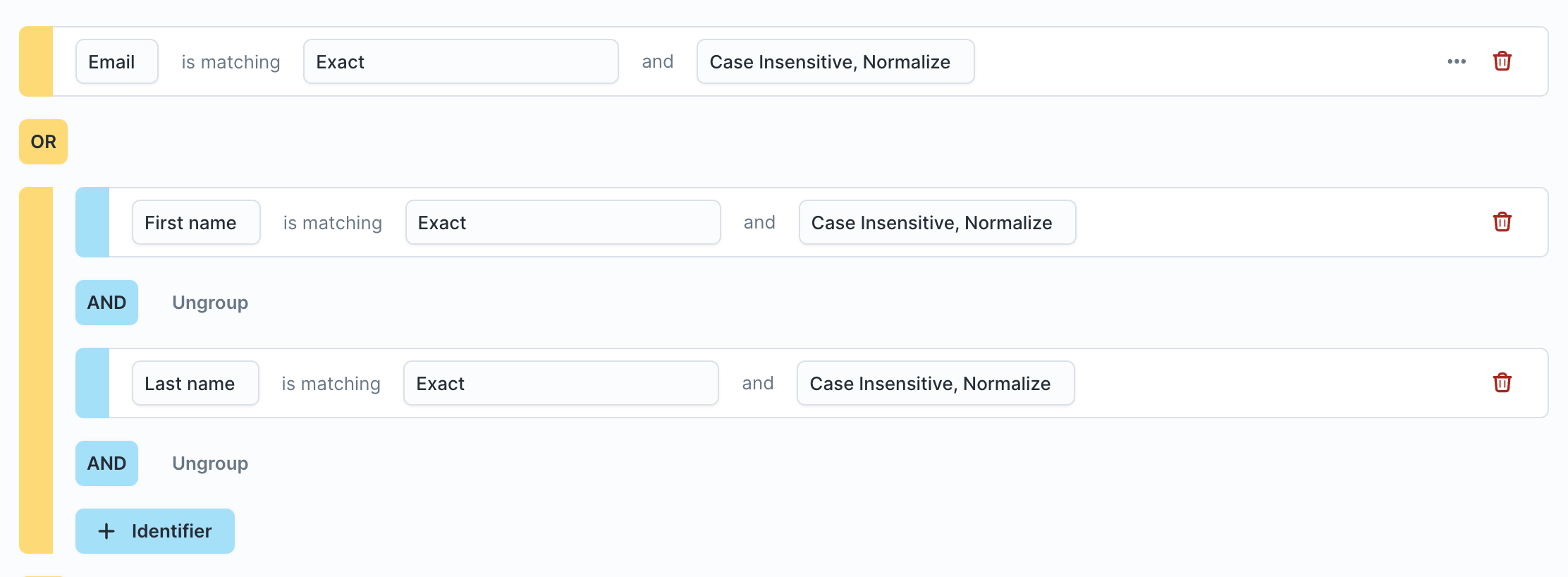
The profiles (represented by the HT_ID being the same) would look like this—note that none of the rows related to the John Does got merged together because of the limit rule violation:
| First Name | Last Name | Source | HT_ID | |
|---|---|---|---|---|
| john.doe@acme.com | John | Doe | Profile | 73bd... |
| john.doe@acme.com | J | Doe | Event | 17a3... |
| john.doe@dundermifflin.com | John | Doe | Profile | 5b6e... |
| john.doe@dundermifflin.com | Johnathan | Doe | Event | 372b... |
| barack@barackobama.com | Barack | Obama | Profile | 9p8h... |
| Barack | Obama | Event | 9p8h... |
The issue here is that you want the rows with john.doe@acme.com and john.doe@dundermifflin.com to be merged into 2 separate profiles with their respective emails because email is a high confidence match. The merge rule on first and last name, however, merges the 2 profiles with separate emails and their associated rows together, causing the limit rule to be hit. This happens because 1 row from each profile matches the other on first and last name.
With rule sets, you can separate the low and high confidence rules into different rule sets:
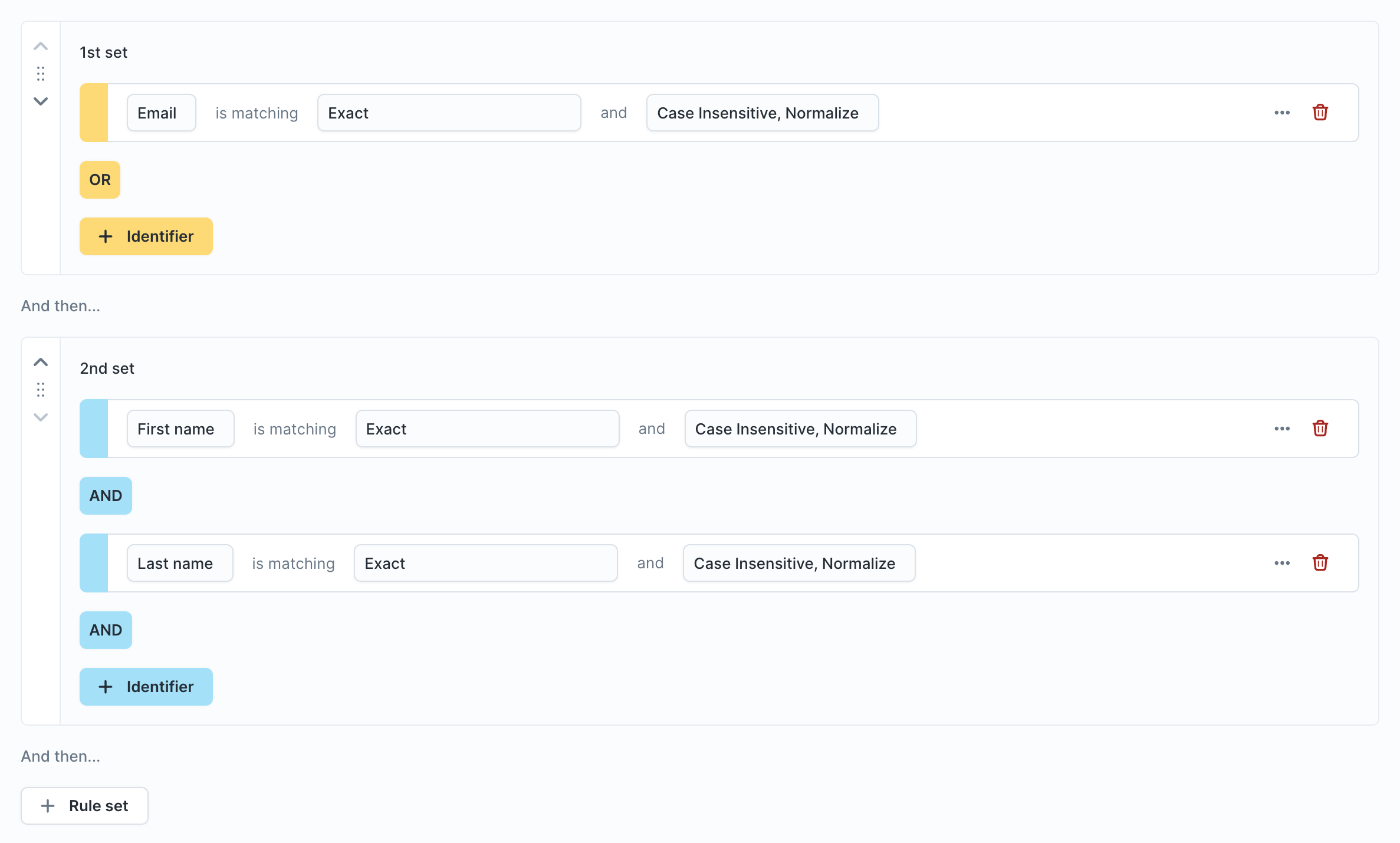
The result looks like this—notice that we now have three HT_IDs representing three unique profiles. We first merge records on email. Then we try merging records on first name and last name, and only for those merges that would introduce limit rule violations, we fall back to the profiles from the previous rule set:
| First Name | Last Name | Source | HT_ID | |
|---|---|---|---|---|
| john.doe@acme.com | John | Doe | Profile | 73bd... |
| john.doe@acme.com | J | Doe | Event | 73bd... |
| john.doe@dundermifflin.com | John | Doe | Profile | 5b6e... |
| john.doe@dundermifflin.com | Johnathan | Doe | Event | 5b6e... |
| barack@barackobama.com | Barack | Obama | Profile | 9p8h... |
| Barack | Obama | Event | 9p8h... |
How it works
After each rule set gets evaluated, we check for profiles that exceed any limit rules and, if found, don't merge in any of the new records from that rule set's evaluation for that profile.
Once the limit rule check completes, the profiles formed from that rule set get locked in so that if subsequent rule sets introduce limit rule violations, those only unmerge records that were merged during that particular rule set's evaluation, not previous rule sets' evaluation.